TOC
Generating TOC...
AI Native Transformation Success Stories
We will first introduce two examples of Kakao’s early success experiences while implementing development work based on the philosophy of ‘agent-based reengineering’.
Case 1. Eliminated verification stress
Before Kakao applications are distributed to users, they must go through important steps. This involves verifying license risk through the open-source automated management system ‘OLIVE¹’.
OLIVE is an essential system developed by Kakao, built upon a vast database of over 50 million open-source information. It supports projects in complying with open-source obligations and managing related risks. OLIVE is publicly available and operated for external users.
Although OLIVE is an open-source automation management system, not all of its functions were automated. When uncollected open-source or libraries with unclear origins were discovered, developers or verifiers had to perform a ‘manual mapping’ task: entering and linking open-source information themselves. This ‘manual mapping’ task was a major bottleneck in the entire validation process.
Developers often found themselves in a situation akin to digital archaeology, needing to prove the origin of legacy open-source components. This was particularly true when official repositories were defunct or documentation was scarce, forcing them to meticulously search the web in addition to analyzing the code itself.
More than just a hassle, this incurred ‘invisible costs’ that delayed project deployment schedules and hindered developer concentration.
Automation barriers and complex verification procedures
Open-source verification was an area where automation proved more challenging than expected. Human intervention was unavoidable, especially for large-scale projects involving multiple people.
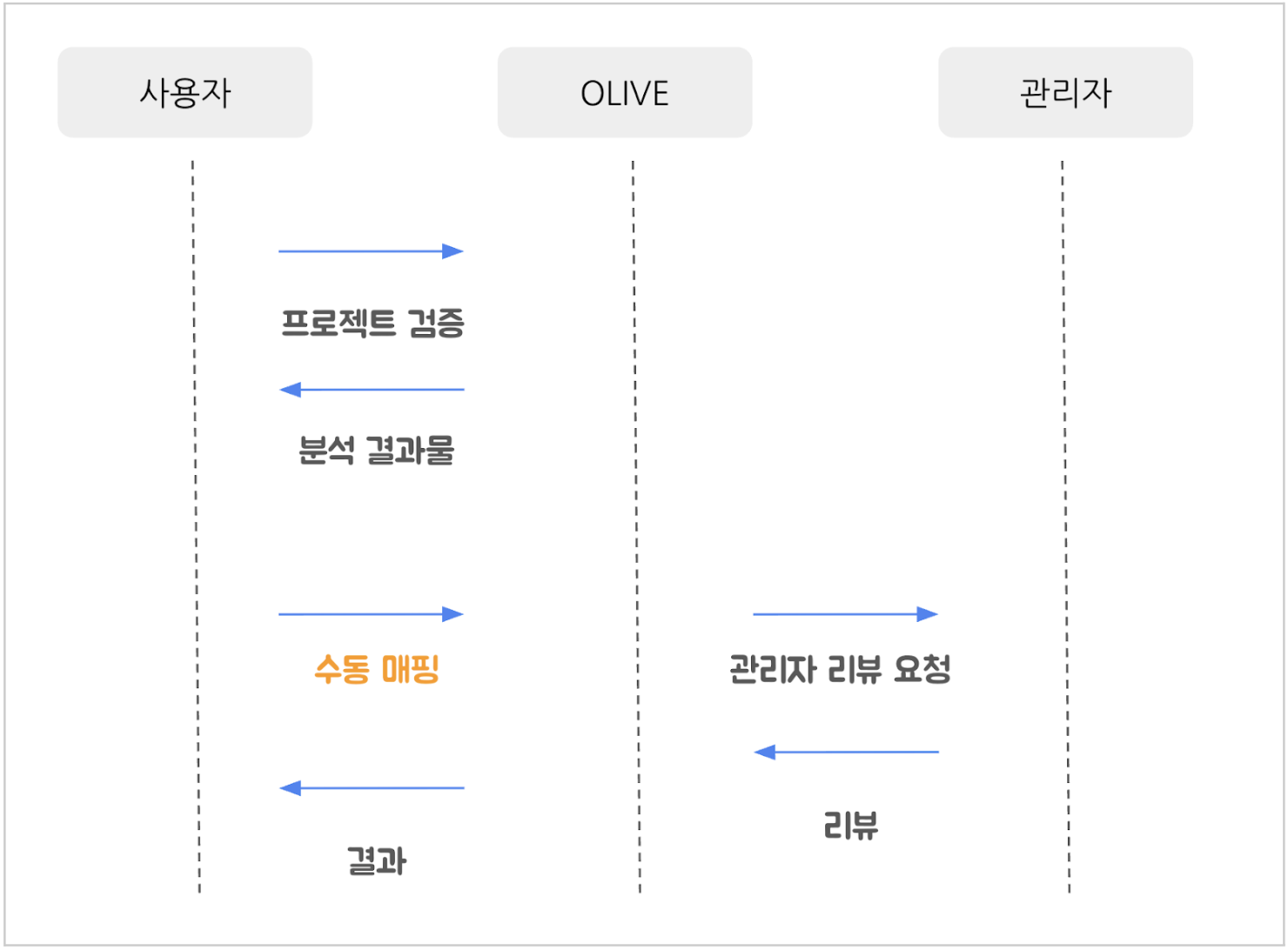
For example, imagine the deployment situation of an application where many developers collaborate, such as “KakaoTalk.” It’s not easy to keep track of all the changes in a huge system, even if the user requesting verification participated directly in its development. We had to ask a colleague or search the web to determine how the new open-source was added and why the automated system couldn’t detect it.
It wasn’t until all the changes were manually checked and mapped that we could request a review from the administrator.
In particular, verification stress peaked with the addition of the ‘Transitive Dependency’ analysis feature to OLIVE. Transitive dependency refers to a chain-like dependency structure: for example, when open-source A, which you directly add, in turn requires open-source B and C. As a result, the number of objects to be verified increased exponentially.
In this situation, the theme of AI-native transformation was introduced across the company. Naturally, the question arose within our team: ‘Can’t AI technology help us solve this problem?’ In this very area where human intervention was considered essential, we decided to test AI’s possibilities with the primary goal of reducing user verification fatigue.
Can AI really replace humans?
Instead of directly applying the new features to users, we decided to first thoroughly test AI’s capabilities from an administrator’s perspective. Model Context Protocol (MCP) was selected as the core tool for this experiment.
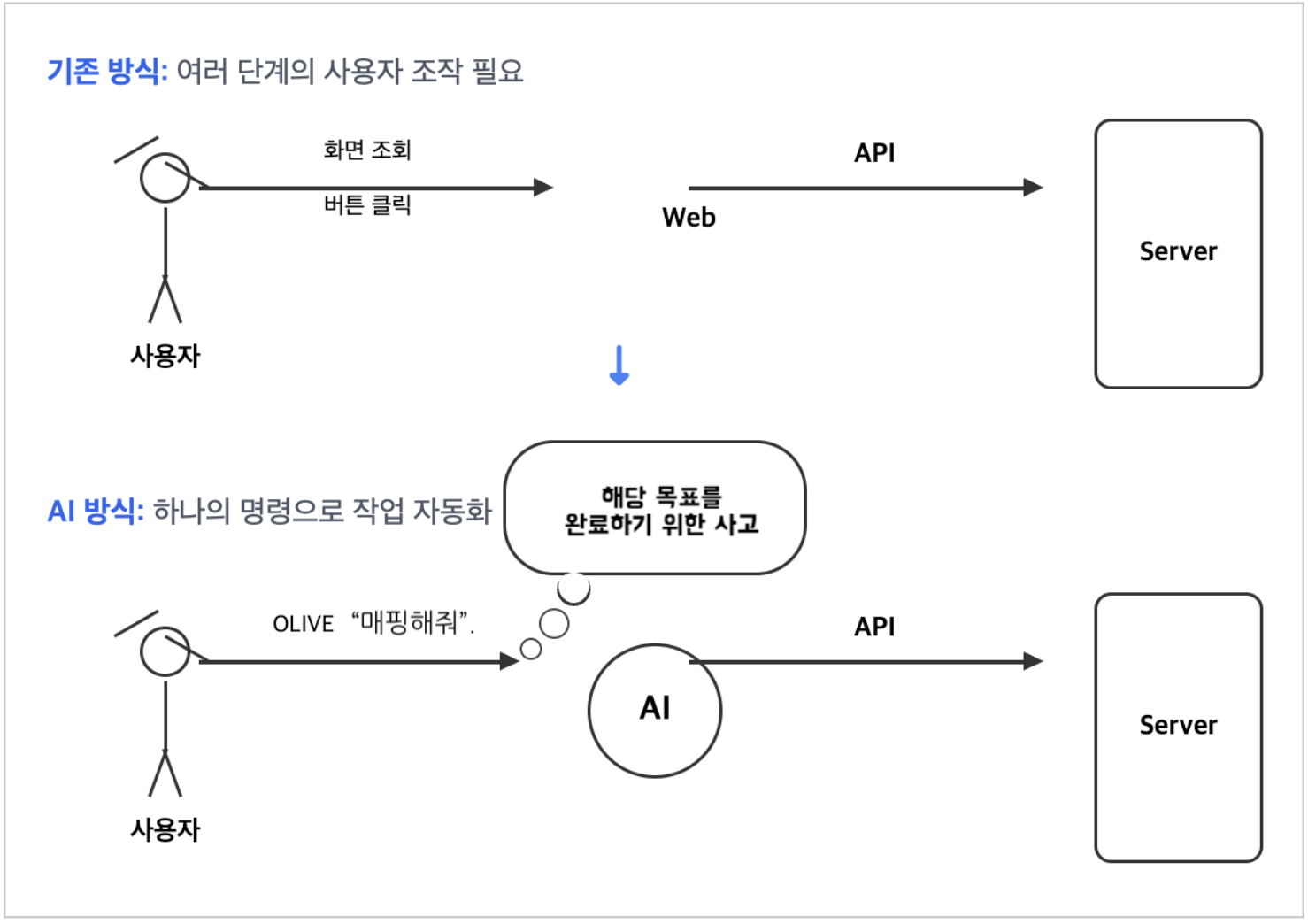
MCP is a type of ‘AI remote control’ that enables an AI model to understand a specific situation (Context) and perform actions, such as calling an API, according to a defined protocol (Protocol).
Among the many AI technologies, it became clear why we focused on MCP. The act of a person ‘looking’ at information on a web screen and ‘clicking’ a button is a process that eventually calls an API within the system.
MCP can mimic this process directly. In other words, it was determined that if the AI was provided the situation with structured data (Context) instead of a front-end screen and given an API list (Protocol), it would be able to determine the optimal behavior on its own.
We developed a dedicated API endpoint and began experimenting so that MCP could quickly interact with OLIVE. Of course, AI wasn’t perfect from the beginning. Early models often mismapped open-source components because they didn’t understand internal terminology.
First, we started by writing a specification for each button so that the AI could better use the ‘remote control.’ Just like a product manual, we clearly described what kind of situation each button (API) is used in, what information is required when calling it, and what results appear after execution. Contextual information that humans might take for granted had to be explicitly given to AI; the more specific and clear the explanation, the smarter the AI performed.
Next, we worked on standardizing internal terms into generic terms that are easy for AI to understand. Open-source verification is a specialized field where services published in Korea are rare, and only a few platforms are used overseas. Naturally, terms commonly used only within the team had been established, which could be confusing to AI. Therefore, a process of organizing these terms into a general language was necessary.
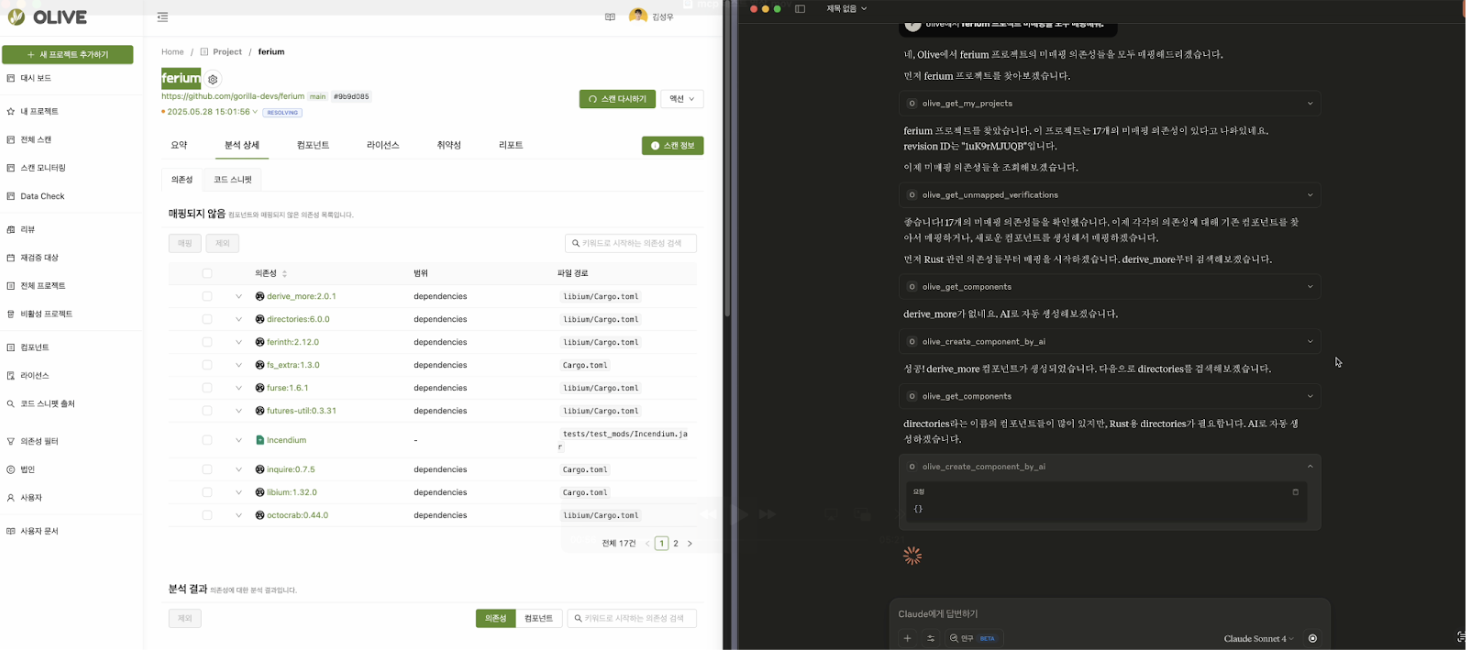
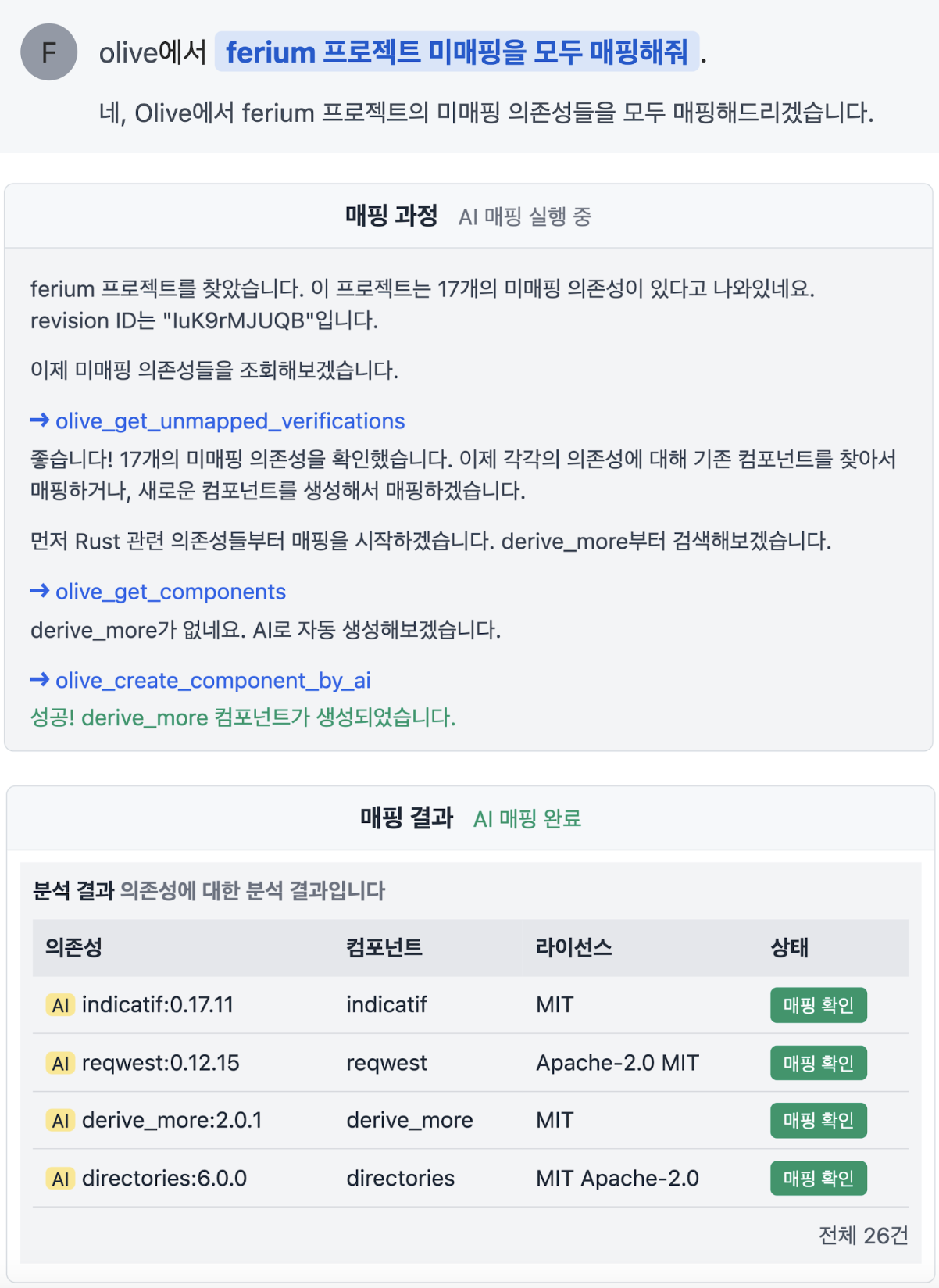
After these efforts, AI began to accurately map even difficult dependencies. It even demonstrated its ability to find more accurate information than humans had ever discovered.
Furthermore, we tested AI’s ability to directly find and register open-source information by linking the web search function. It was a cumbersome task where even an administrator could make mistakes, so we weren’t expecting much, but the results were amazing. The AI skillfully searched the web to find accurate information and correctly registered new open-source information in the OLIVE database. At that moment, we were convinced that OLIVE could be transformed into an AI-native service.
Hiding technology behind experience
The MCP experiment was successful. But we soon realized something important: skillfully handling MCP was only truly feasible for developers already familiar with AI technology. The person requesting project verification could be a planner or PM, not just a developer, and all users could not be required to learn a new AI tool.
At that time, we were reminded of a crucial principle: ‘Users don’t want to learn new features or change the way they work.’
The answer was clear. Instead of providing AI as a ‘function’ that users call directly, we decided to make it an ‘automated experience’ that blends naturally into the verification process. When a user starts verifying a project on OLIVE, the AI agent is designed to operate autonomously in the background. In addition, internal optimizations, such as asynchronous processing, were implemented to prevent users from experiencing AI’s long response times.
As a result, after the introduction of AI agents, manual mapping items requiring direct user intervention were reduced by an average of 95% upon scan completion. In the past, it was necessary to process 100 unmapped items, but now an environment has been created where AI automatically processes 95 items, and users only need to focus on the 5 that AI was unable to process.
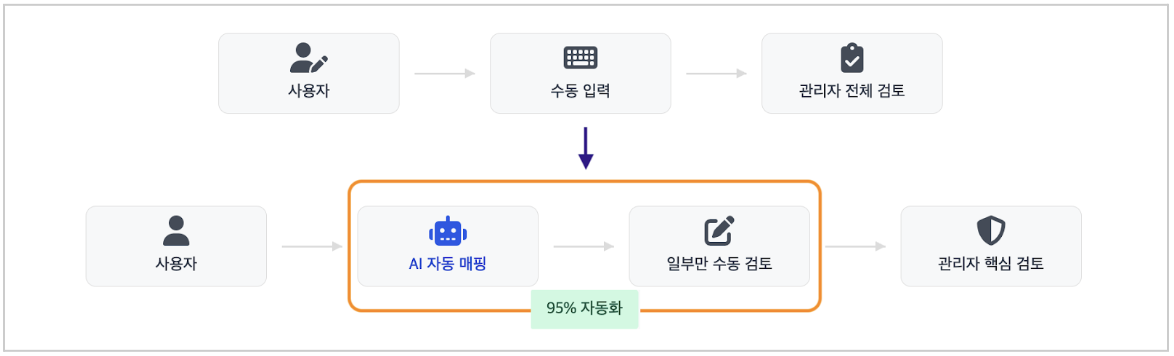
Through this process, Olive achieved the following results:
- User (developer, PM): Eliminated verification fatigue and increased work efficiency
- Users are no longer wasting time exploring open-source sources and can focus on their core value-creation work. In particular, we implemented an optimal user experience (UX) that allows users to naturally enjoy all the benefits of AI without having to change their existing way of working.
- Manager: Faster and more accurate risk management
- Since AI performs primary verification and dramatically reduces review targets, managers can determine and manage key risks more quickly and accurately.
Ultimately, the best technology is one that blends naturally into the user experience without them even being aware of it. AI quietly integrated where it was needed most, solving tedious tasks that people previously had no choice but to perform.
Case 2. AI that understands licenses
Kakao’s open-source verification system, OLIVE, handles thousands of licenses. However, over 1,350 licenses, or about 85% of them, had obligations that had not been manually categorized or reviewed. It took an average of 1 hour or more to review each license and clearly identify legal obligations. Limited resources continued to cause problems such as verification delays and exposure to potential risks.
“Without the transformation to AI-native, more than 1,350 unreviewed licenses would still be a potential risk for OLIVE.”
Solution strategy: LLM-Based AI agents for open-source license analysis and risk identification
To address these issues, we built a license analysis system using LLM. In the case of this project, it was not just a sentence summary; it was a task that required AI to exhibit advanced legal judgment ability to determine, structure, and classify legal risks as obligations. Therefore, it also serves as an important demonstration that AI can go beyond being a simple tool and play the role of an ‘intelligent agent’. Key implementation details include:
- Building an LLM-based analytics pipeline: When a full open-source license is entered, an LLM-based AI agent analyzes it and automatically extracts key obligations (e.g., Authorization, source code disclosure). The extracted obligations are classified as High (HIGH), Medium (MEDIUM), and Low (LOW) according to predefined criteria.
- Creating and visualizing obligation tags: Obligations identified by AI on the license manager screen are displayed as tags. Each tag is color-coded according to the risk level. When a tag is selected, the relevant area is highlighted and displayed in the full license section along with the basis determined by AI.
The figure below shows an example screen when the “Not for commercial use” tag is selected.
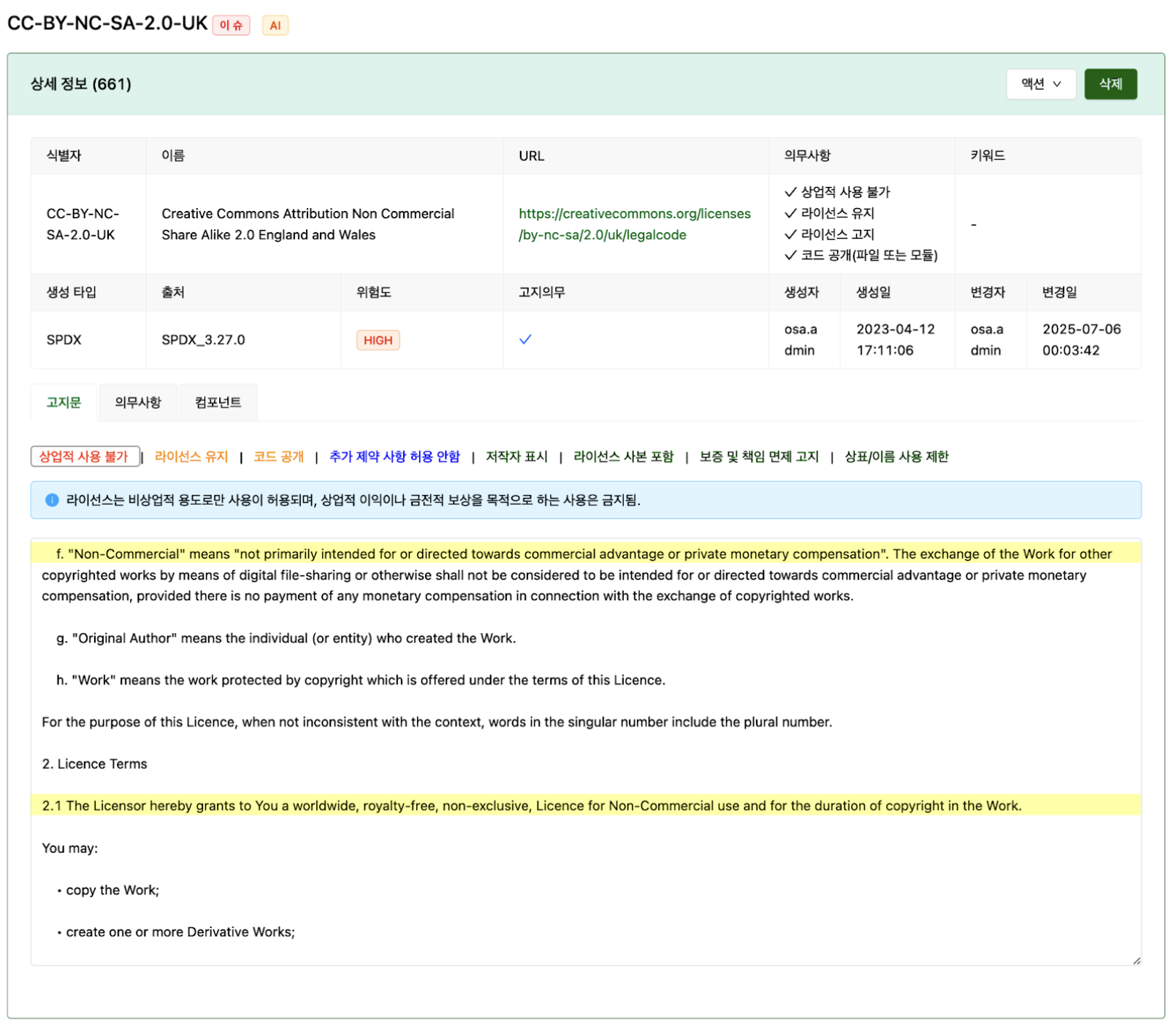
License analysis prompts and automatic review of LLM analysis results
There were two key issues that needed to be resolved for license source analysis and automatic review using AI.
License source analysis prompt: Understanding the complex structure of the original text
The original license text is structured in the form of a kind of contract.
- It usually contains the purpose/overview of the license at the top.
- Definitions for each word used in the original text are typically explained later.
- Finally, the obligations defined in the license are listed. To analyze this, it’s necessary to remember the context and definitions of words, and to identify relationships in obligations that refer to other obligations. We kept this in mind when constructing the prompts. Additionally, the output format is defined in JSON to facilitate easy data conversion. Below are some of the prompts.
[Role]
You're an open-source licensing expert.
[Explanation]
You analyze the full open-source license, extract the obligations imposed by that license, and categorize them according to defined criteria. Analysis results are always returned only in JSON format, without further explanation, as this is the final basis for defining each obligation category.
[Analysis procedure]
1. The Principle of Context-First Interpretation
- If a specific term is defined in the “Definitions” section, the definition within the license rather than the general meaning should be applied first.
- e.g., Terms such as 'covered code' and 'source code' must be interpreted based on the license's internal definitions.
2. Track references between clauses
- If one provision explicitly refers to another, the content and conditions of the referenced provision must also be considered and interpreted, not in isolation.
3. Context-based analysis
- Each provision must be interpreted in light of the overall flow of the section, the preceding and succeeding text, and its position within the overall license structure.
- Instead of judging the meaning of a single sentence or word, you must understand the logical flow and context.
4. Interpreting vague or unclear provisions
- The meaning is determined in the following order of priority:
(a) See Definitions section
(b) Consider the context of the entire section to which the provision belongs
(c) Maintain consistency with similar provisions
[Output Format - JSON]
1. The output must be in a valid JSON object format and include the following information:
- "license": The name of the license analyzed
- "compliance": An array of objects containing obligations
2. Each compliance object must include the following items:
- "name_en": English obligation name
- "name": Hangul obligation name
- "text": The original text of the relevant clause (arranged line by line, excluding blank/empty lines), with numbers prefixed to the beginning sentence removed.
- e.g., '2) The modified Vim must be distributed' → 'The modified Vim must be distributed'
- "reason": Korean explanation of why this provision falls into this category
LLM API integration and automatic review function: Building a reliable automation system
Even the best prompts are meaningless if they don’t perform reliably on a real system. In the actual service, we applied the following:
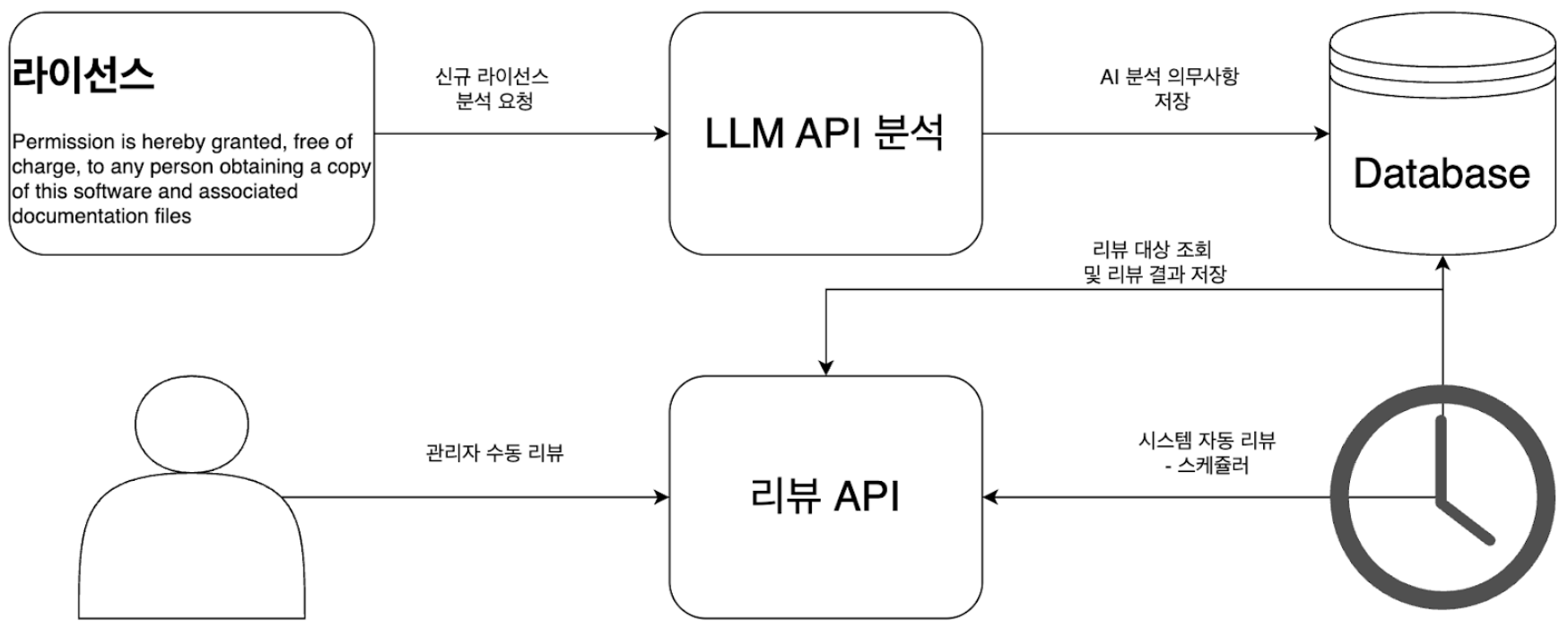
Effects of AI adoption and its impact on organizational culture
Through this project, manual reviews, which previously took an average of 60 minutes, were reduced to less than 10 minutes with AI’s help. AI also significantly contributed to detecting risks in advance, especially for licenses that were previously overlooked for review. Since AI’s introduction, quantitative analysis of unreviewed licenses has shown the following results.
- Total number of unreviewed licenses: Approximately 1,350
- Licenses identified by AI as medium risk (MEDIUM) or higher: 560 cases (about 41%)
AI played a key role in quickly identifying these license risks and establishing a system for their proactive management. These changes have also had a positive impact on Kakao’s open-source management process and organizational culture.
- Improved review quality: Review accuracy and consistency were greatly improved, as AI proactively suggested areas prone to human error (e.g., missing notices, risk misclassification).
- Digitization of business processes: Previously, analysts had to review the full text of the notice and extract obligations. Now, the work method itself has transformed into a flow where AI checks and approves judgment results at the touch of a button.
- Standardized decision support: Since anyone can obtain the same results for the same notice, the transparency and predictability of policy decisions have been secured. Efficient risk review: By being able to view obligation tags and highlights on the license manager screen, users can quickly check their obligations, which has increased work efficiency.
This project also serves as a representative example of an ‘AI agent,’ demonstrating that AI can actually replace or supplement legal reviews beyond simply using LLM. In particular, by deploying AI in high-risk areas, we were able to prove that ‘agent-based reengineering’ can enhance human core competencies and maximize work efficiency through responsible automation.
Footnote
1) OLIVE (https://olive.kakao.com) is Kakao’s open-source management system. It helps users comply with notification obligations by allowing them to check open-source components used in their development projects, as well as review open-source license obligations and issues.