TOC
Generating TOC...
2.4. Real-time code review and quality control
In modern software development, code reviews have become an essential procedure for quality assurance and knowledge sharing within teams. Code reviews are typically performed in one of two ways.
- Post-review: PR (Pull Request) based review, where code is reviewed before being merged after it has been written.
- Preview: A method in which a pair or senior directly checks code that is being written or has just been completed.
This review culture has a positive impact on maintaining code readability and consistency, early error detection, and security flaw prevention. However, there are clear limitations to the traditional approach.
PR (Pull Request)-based code reviews cause an average delay of 4 to 24 hours between code writing and approval. Review bottlenecks are particularly noticeable in the following situations.
- Limited reviewers cause PRs to pile up for the entire team.
- Review criteria are not documented, resulting in different interpretations for each PR.
- The more code there is or the higher the complexity, the easier it is for feedback to be interrupted.
According to various studies and GitHub data analysis cases, the average PR merge time is reported to range from several hours to several dozen hours. Although there are variations depending on factors such as team size, number of reviewers, amount of code changes, and level of automation, it is generally observed in most projects that “an average of one business day or more (≈24 hours or less) is required per PR.” These delays directly impact the team’s release cycle and feedback speed.
One of the main reasons for this delay is that code reviews rely heavily on human intuition without clear criteria for judgment. In particular, human-centered reviews have the following limitations.
🅧 “This function is a bit complicated.”
🅧 “This part should be refactored later.”
🅞 “The cognitive complexity (Cyclomatic Complexity) of this method exceeds 15 (standard: 10)”
Feedback that lacks quantitative criteria like this is easily influenced by the reviewer’s authority or the author’s experience, which can undermine the consistency and fairness of the review. In addition, the most serious problem with reviews is when security flaws or critical bugs are missed during the review stage. For example, SQL injection vulnerabilities often occur in code such as the following.
String query = "SELECT * FROM users WHERE name = '" + username + "'";
Even if this code is included in the PR, reviewers who do not normally perform security reviews may not discover the issue. Given that reviewers’ knowledge gaps and fatigue directly affect code safety, the need for automated assistance tools is becoming increasingly apparent.
The necessity of introducing AI and expected effects
To overcome the limitations of traditional code reviews and improve both development efficiency and quality, AI-based automated review systems are rapidly becoming widespread. In particular, the combination of LLM and static analysis algorithms is evolving beyond simple regular expression-based reviews to a level where it can understand context and make judgments.
1. Automatic detection of highly repetitive patterns
Issues that are repeatedly pointed out in code reviews mostly stem from static rules or structural problems.
For example:
- Method length exceeded
- Duplicate if-else blocks
- Hard-coded constants
- missing try-catch
Such patterns can be detected automatically by AI analyzing code structures according to predetermined rules or learned criteria, rather than by humans searching manually. For example, the following code could be criticized for having redundant conditional statements and excessive complexity.
if (user != null && user.getRole() != null && user.getRole().equals("ADMIN")) {
// ...
}
A GPT-4-based model can automatically generate the following comments based on the above code:
[AI Review] 조건문이 중첩되어 있어 읽기 어렵습니다. 아래와 같이 리팩토링을 고려해보세요:
Optional.ofNullable(user) .map(User::getRole) .filter(role -> role.equals(“ADMIN”)) .ifPresent(…);
2. Improved review speed and elimination of bottlenecks
AI is faster than humans and is always on standby. When automatic review is triggered as soon as code is committed, review results can be provided within seconds and implemented in the following manner.
- Run static analysis and LLM review agents when PRs are created in GitHub Actions or your internal CI/CD tool.
- Review comments are automatically registered in PR.
- Summarize static analysis results and display them as inline comments.
This structure minimizes bottlenecks in team code reviews and allows reviewers to focus solely on core logic and architectural decisions.
3. Providing quantified quality feedback
Where existing reviews were limited to subjective comments, AI can provide automated reports based on quantitative criteria. For example, results containing the following metrics are possible:

These automated review results can be easily linked to the next steps, such as QA, operations, and release approval, enabling consistent quality standards to be applied throughout the DevOps flow.
4. Learn internal specialized review criteria
In addition to general open-source standards, the internal LLM model can be trained with review criteria specific to the company’s code style, failure history, component structure, and other factors.
For example:
- Past fault-causing code → Learns “similar conditions” to provide risk alerts
- Prohibited use of specific library versions → Warning at review time
- Analysis of the scope of impact when changing common modules → AI automatically comments
Through this, AI reviews can evolve beyond simple rule-based reviews and be used as review agents tailored to teams and organizations.
The Impact of Real-Time Reviews on Development Culture
AI-powered real-time code review goes beyond simply automating the review process, significantly impacting developer experience and the overall code quality culture of an organization. Its effectiveness is particularly evident in the following three aspects.
1. Shortening the feedback cycle
Traditional reviews followed a flow of review request → review pending → feedback received → revision request → re-review, which took several hours for each PR. However, with AI reviews providing real-time feedback, the following changes may occur.
- Revision cycle shortened to minutes → Review bottlenecks eliminated, number of commits increased
- Provides inline suggestions that can be checked immediately → Can be modified directly in the IDE or PR UI
This immediacy allows developers to receive feedback without interrupting their coding flow, which reduces emotional fatigue and improves work engagement.
2. Standardization of review feedback and increased psychological stability
Real-time AI reviews provide feedback that is judged by the same standards for everyone, resulting in the following positive organizational cultural effects:
- Ensuring consistency in feedback: Code style issues and refactoring criteria, which were interpreted differently by each reviewer, are clarified.
- Separation of review subject and feedback: By having AI provide reviews first, rather than humans, the psychological burden of accepting feedback is reduced.
- Supporting the growth of inexperienced developers: Even new developers can quickly recognize standardized areas for improvement through reviews and repeat learning.
For example, when the following code feedback is provided by an AI reviewer rather than a human reviewer, there tends to be a higher feedback acceptance rate:
[AI Review] 이 메소드는 42줄로 구성되어 있어 유지보수가 어렵습니다.
메소드를 2개 이상으로 나누는 것을 고려해보세요.
It is conveyed in a more objective and critical manner than human reviewers, and improvements can be made without emotional friction.
3. Strengthening a team culture focused on code quality
AI reviews analyze and record all code using the same criteria, enabling natural team-wide quality control.
Visualization of team code quality metrics: Average cyclomatic complexity, average coverage, duplicate code ratio, and other metrics can be automatically calculated and shared in weekly reports.
Structuring review feedback history: Organizational improvement directions can be derived by analyzing the review patterns of the entire team.
Enhanced review-release linkage scenario: AI review results are directly reflected in release conditions, enabling a culture where releases are determined based on quality.
AI-based static analysis technology
AI-based real-time code review requires a foundation that can intelligently analyze code and generate meaningful feedback. And static analysis technology can provide this foundation.
Static analysis is a technique that finds errors and vulnerabilities by analyzing the source code itself without executing the program. This involves more precise analysis than the syntax checking performed by compilers, and is widely used as a core technique in modern software quality assurance. With the addition of AI technology like LLMs, static analysis is going beyond simple rule-based checks to understand the context and meaning of code, spot complex patterns that humans might miss, and give more sophisticated and practical feedback.
Code complexity analysis using AI models
In static analysis, code complexity is one of the most important metrics for quantifying code quality. In particular, cyclomatic complexity and cognitive complexity are key metrics that quantify the structure and difficulty of understanding at the function level, and are also used as important criteria for predicting code risk in AI review systems.
1. Cyclomatic complexity
Cyclomatic complexity is calculated based on the number of branch points in the control flow and generally follows the following formula:
M = E - N + 2P
- E (Edges): Number of paths in program flow
- N (Nodes): Execution units such as conditions and statements
- P (Connected Components): Normally, a single function/procedure is considered to be one connection element.
However, most static analysis tools are implemented using simplified calculations as shown below:
M = 1 + number of conditional statements (if, while, for, catch, case, &&, ||, etc. )
Example: Calculating the cyclomatic complexity of Java methods
public boolean validate(User user) {
if (user == null) return false;
if (user.getAge() < 18) return false;
if (user.isBlocked() || user.isBanned()) return false;
return true;
}
ifstatements: 3||operator: 1 (adds 1 additional branch)- Total complexity: 1 + 3 + 1 = 5
Generally, refactoring is recommended when the score is 10 or higher, and when it is 20 or higher, the code is considered to be very complex and requires review or enhanced testing.
2. Cognitive complexity
Cognitive complexity analyzes code from a human understanding perspective rather than from a cyclical complexity perspective. It considers not just the number of branches, but also nesting, flow clarity, and predictability of return locations.
For example, the following code has low cyclical complexity but may be evaluated as having high cognitive complexity:
for (...) {
if (...) {
while (...) { // 반복/분기 중첩이 깊을수록 Cognitive Complexity는 비선형적으로 증가
// … // 조건/루프 탈출이 예측 불가능하거나 흐름이 복잡하면 더 가중치 부여
}
}
}
Complexity is generally considered difficult to understand when it is 15 or higher.
3. How do AI models interpret complexity?
LLM does not directly calculate complexity, but it recognizes patterns similar to complexity in the following ways:
- Recognize the number of Abstract Syntax Tree (AST) nodes in conditional statements, loops, and try-catch structures.
- Calculate the nesting level (depth) of code blocks.
- Reflect context-based complexity such as exception handling, logging, and side effects in each branch.
- Compare the similarity (cosine distance) with other codes that implement the same function to determine whether the structure is complex.
[GPT-4-based code summary example]
[AI Review] 이 메소드는 분기 조건이 많고, 예외 상황이 분리되어 있지 않아 가독성이 떨어집니다.
→ ‘isValidUser’와 ‘checkUserPermission’으로 분리해보세요.
4. Example of AI + numerical-based composite analysis
The AI review system combines numerical complexity and LLM judgment in the following manner:
{
"function": "validateUserAccess",
"cyclomatic_complexity": 13,
"cognitive_complexity": 21,
"ai_feedback": "중첩된 조건문과 긴 논리 조합으로 인해 이해하기 어렵습니다. 리팩토링을 권장합니다.",
"suggestion": [
"조건을 별도 메소드로 분리",
"로깅 및 에러 처리를 명시적으로 구조화"
]
}
These results are automatically attached to GitHub PR reviews or reported as part of quality reports. Furthermore, it can also be used as deployment blocking conditions or QA severity classification criteria.
Security vulnerability detection and response
Security is just as important as code quality. In particular, missing input validation, resource access permission errors, and hard-coded sensitive information in code running in a production environment can lead to critical service failures and information leaks. To defend against these serious security issues, code static analysis can be used to detect security vulnerabilities in advance by analyzing code structure and string literals without executing the code. Recently, AI-based context interpretation and response recommendation functions have also been added to this.
1. Major security vulnerability types (based on OWASP)
OWASP Top 10 is an international standard that systematically classifies security vulnerabilities found in code. Here are some examples.
| Type | Description | Example |
|---|---|---|
| A01: Broken Access Control | Accessing critical resources without authentication | Missing URL authorization check |
| A03: Injection | Manipulation of commands through input values | SQL, LDAP, Command Injection |
| A06: Vulnerable and Outdated Components | Use of outdated libraries | Inclusion of vulnerable versions such as log4j, spring-security-web |
| A07: Identification and Authentication Failures | Use of weak authentication mechanisms | Simple IDs, passwords, etc. |
Some of these can be detected using string regular expressions or patterns, but many require contextual analysis, such as flow of conditional statements, missing input filtering, and exception handling structures, in order to detect vulnerabilities.
2. Security issues detectable by static analysis
Kakao’s internal static analysis tool SCAN detects vulnerabilities by applying the following security rules.
[Example: Dynamic Injection Detection (TypeScript)]
let value = eval('obj.' + propName);
Static analysis results:
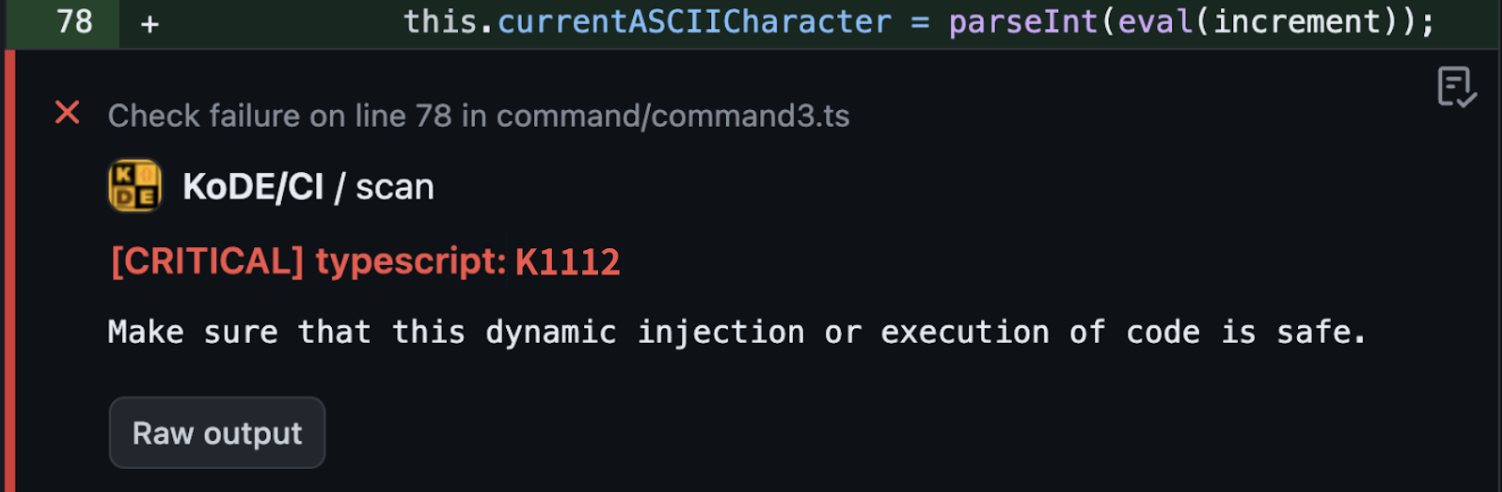
However, the problem lies in the fact that the actual code is much more complicated. Even if input values have been validated by other functions or if a specific framework has internal defense logic, static analysis often sends warnings based on the principle of “better safe than sorry.” Ultimately, developers may miss real threats amid numerous false warnings.
3. How AI views security vulnerabilities
AI models go beyond simple string pattern matching to interpret and judge threats within the overall structure and flow of the code. For example:
@app.route("/search")
def search():
keyword = request.args.get("q")
return f"<div>Results for {keyword}</div>"
In the case of the code above, GPT-based AI can generate the following review comments:
[AI Review] 사용자 입력값 ‘keyword’가 HTML로 직접 렌더링되는데 사용되고 있습니다. → XSS(Cross-site Scripting) 공격 가능성이 있습니다. → escape(), sanitize() 또는 템플릿 엔진 사용을 권장합니다.
AI recognizes that this code operates within a web routing context and that user input has been inserted into the HTML string, enabling it to identify the potential for XSS rather than simply inserting a string.
4. Combining AI and rule-based static analysis tools for complex pattern detection
AI-based review systems can complement rule-based static analysis tools in the following ways:
| Feature | Static Analysis | AI Review |
|---|---|---|
| Fast and rule-based detection | ✅ Strength | ⚠️ Some limitations |
| Context-based understanding | ❌ Lacking | ✅ Strength |
| Refactoring suggestions | Limited (e.g., use try-with-resources) | Natural language-based refactoring recommendations |
| Learning from user feedback | ❌ Not available | ✅ Possible (Few-shot / Fine-tune) |
This hybrid analysis system complements static analysis by identifying context-based security flaws that static analysis misses, and automates refactoring suggestions to improve code beyond simple warnings.
Building a practical bug prediction model
An AI-based review system for hybrid system configuration must go beyond the obvious rule-based detection of static analysis and build a learning-based bug prediction model that leverages the development team’s past mistakes as assets. This model learns from past code change history and actual bug data to warn you in advance of code structures that are likely to contain errors.
1. Data structure: Extracting “real” bug history
The performance of bug prediction models depends on the quality of the training data. Usually, the following two data are used.
- Normal commit: General feature additions/refactoring, etc.
- Bug fix commit: Commits containing keywords such as “fix” and “bug” linked to issue trackers
This is where the biggest hurdle arises. In practice, the keyword “fix” is often used for simple typos or setting changes rather than bug fixes, resulting in a lot of noise. Therefore, not only commit messages, but also processes such as linking Jira tickets’ “Bug” labels with commits to refine data have a decisive impact on model performance. In addition, commit data that has been modified to address issues detected by static analysis tools is also important data that can significantly improve model performance.
Let’s look at a simple example of a bug fix commit:
- if (user != null && user.getName().equals("admin")) {
+ if (user != null && user.getName() != null && user.getName().equals("admin")) {
This change is a modification to avoid NullPointerException, and allows the following labels to be assigned:
{
"before_code": "if (user != null && user.getName().equals(\"admin\"))",
"after_code": "if (user != null && user.getName() != null && user.getName().equals(\"admin\"))",
"bug_type": "NullDereference"
}
We collect thousands to hundreds of thousands of such changes to build a learning dataset. Publicly available data such as Defects4J and CVEfixes can be utilized effectively, but the best option is your own dataset that reflects your team’s code base and development culture.
2. Model configuration: Realistic choices and trade-offs
Bug prediction models are broadly divided into two types. Each has clear advantages and disadvantages, so we should choose based on the team’s current technology stack and goals.
(1) ML-based classification model: Start small and fast
- Features: After evaluating the features (e.g., code complexity, API call frequency), we classify them using RandomForest, XGBoost, etc.
- Advantages: The model is lightweight, relatively easy to interpret, and easy for existing data analysts to work with.
- Disadvantages: The process of defining which features are associated with bugs, known as “feature engineering,” is very difficult and requires a lot of time and effort. There is also a clear limitation in that it is difficult to reflect the subtle context of the code.
(2) LLM-based pattern similarity model: Aiming for high accuracy
- Features: We apply pre-trained LLMs such as CodeBERT/GPT or open-source models directly to the code to assess risk.
- Advantages: By understanding the context and meaning of the code itself without feature engineering, it has the potential to achieve much higher accuracy than traditional ML models.
- Disadvantages: High-spec infrastructure (GPU) costs for model operation may be burdensome. In addition, fine-tuning to teach the model specific bug patterns in the codebase requires considerable expertise. In the early stages, instead of fine-tuning, RAG (Retrieval-Augmented Generation), which searches for similar bug cases, may be a more realistic alternative.
3. Risk assessment and practical review integration
The model’s predictions should be provided in a way that developers can trust and act upon.
{
"function": "validateUser",
"risk_score": 0.91,
"matched_bug_type": "NullDereference",
"suggestion": "user.getName() 호출 전 null 확인이 필요합니다. 과거 유사 버그(Kakoa-BugFix/6824)를 참고하세요.",
"business_impact": "High (로그인 실패 및 사용자 경험 저하 유발 가능)",
"owner": "@kakao-team/service/shopping"
}
Beyond simply displaying risk scores, linking to similar past bug tickets or specifying the potential impact of the bug on the business encourages developers to take warnings more seriously and take immediate action.
Detection of configuration errors and prediction of potential failures
Modern applications are driven not only by simple code, but also by numerous configuration values. Spring Boot’s application.yml, Docker’s docker-compose.yml, Kubernetes’ deployment.yaml, Python’s .env file, etc. are core configuration components that specify the execution environment, security policies, and external connection conditions.
- These configuration files have the following characteristics.
- Unlike code, they are not verified by a compiler or IDE.
- Errors only become apparent after runtime.
They account for a high percentage of causes of failures.
Therefore, combining static analysis of configuration files with AI-based anomaly detection models can greatly improve the accuracy of predictive risk detection.
1. Common types of configuration errors
Configuration file errors are usually divided into the following four categories:
| Type | Description | Example |
|---|---|---|
| Missing | Required key or value is absent | Missing spring.datasource.url |
| Typo | Using a non-existent key | servlet.seession.timeout (typo) |
| Range Violation | Value exceeds the allowed range | maxConnections: -1 |
| Inconsistency | Two items conflict logically | tls: enabled + port: 80 |
Since these errors often appear as failures after deployment, it is very important to detect them during the review stage or at the time of build.
The following is a sample list of high-risk settings options:
| Category | Config Keys (Examples) | Description | Incorrect Value Examples | Risk Factors |
|---|---|---|---|---|
| Network Connections | connectTimeout, socketTimeout, readTimeout | Timeout settings for external service/API connections | Too short (e.g., 100ms) | Unable to tolerate network latency → cascading failures |
| Thread/Pool Management | maxThreads, minSpareThreads, corePoolSize, queueSize | Number of threads/queue capacity for handling requests | Excessive (e.g., >1000) Too small (e.g., 1) |
Thread starvation or OOM due to overload |
| Database/Cache Connections | maxPoolSize, connectionTimeout, idleTimeout | DB connection pool size and timeout settings | Undersized or oversized (e.g., pool=5, timeout=10ms) | Connection exhaustion, accumulated timeouts |
| GC/Memory Settings | Xmx, Xms, newSize, GC type | JVM memory and GC configuration | Small heap, unbalanced GC | Frequent Full GC → response time spikes |
| API Security Settings | allowCredentials, cors.allowedOrigins, csrf.enabled | API authentication/authorization/security settings | * or disabled |
Authentication bypass, CORS bypass, security vulnerabilities |
2. Detection of configuration errors using static analysis tools
Static analysis tools and schema validation tools can identify configuration errors in the following ways:
- YAML/JSON Schema-based key validation
- Required value missing check (required)
- Regular expression-based allowed value check (pattern, enum)
- Mutually dependent field logic check (e.g. When A is true, B is required)
[Example: application.yml schema validation]
spring:
datasource:
url: jdbc:mysql://localhost:3306/db
username: admin
password: admin123
→ Spring-based application YML schema definition:
{
"spring.datasource.url": { "type": "string", "required": true, "pattern": "^jdbc:" },
"spring.datasource.username": { "type": "string", "required": true },
"spring.datasource.password": { "type": "string", "required": true }
}
By validating based on this schema, we can detect URL value omissions, type errors, format errors, and other issues in advance.
3. Configuration error detection using AI models
Context-based risks that static analysis cannot detect can be supplemented with AI-based analysis. In particular, by utilizing bug prediction models previously trained for security vulnerability detection, it is possible to detect semantic inconsistencies or incorrect combinations between elements in configuration files in real time. This model analyzes correlations between configuration items to identify potential configuration errors and conflicts in advance, providing real-time feedback to developers in the following ways.
- Detection of logical conflicts between settings
- Warning about missing required items or combinations that are not recommended
- Risk assessment based on similarity to past similar configuration errors
This approach goes beyond simple rule-based approaches and provides a foundation for building a system that detects configuration errors based on meaning and provides feedback.
[Example: Example of generating risk feedback at the time of review (from application deployment script)]
env:
- name: JAVA_TOOL_OPTIONS
value: >
-Dsun.net.inetaddr.ttl=0
-javaagent:/share-vol/apm/apm.agent.jar
-Dapm_application_key=$(APM_APPLICATION_KEY) <- 실수로 삭제가 되었다면
-Dapm_collector_address=$(APM_COLLECTOR_ADDRESS)
-XX:InitialRAMPercentage=60.0
→ GPT-based model analysis results

4. Static analysis + AI hybrid configuration strategy
Combining static analysis and AI analysis creates a complementary and powerful system for detecting configuration errors.
| Feature | Static Analysis | AI-based Analysis |
|---|---|---|
| Key/Type Errors | ✅ Strong | ❌ Not supported |
| Combination Logic Errors | ❌ Not possible | ✅ Possible |
| Warnings Based on Past Incident Context | ❌ None | ✅ Learnable |
| Flexibility for Customization | Limited (Schema-based) | High (Learnable based on in-house data) |
Integration example:
- Perform schema check first in CI stage → Filter YAML errors
- Then, send the changed settings diff to the AI model → estimate risk level + generate review comments.
- If the risk score is equal to or greater than the threshold value, PR comments can be registered or distribution blocked. Trigger integration possible
This hybrid analysis system complements static analysis by identifying context-based security flaws that static analysis misses, and automates refactoring suggestions to improve code beyond simple warnings.
AI-based review systems are typically not operated independently, but rather integrated with existing static analysis tools to perform a complementary role. Open-source analyzers such as SonarQube, Semgrep, and SpotBugs have already become central to quantitative quality management in numerous organizations. Kakao is leveraging these tools in conjunction with SCAN, a code static analysis tool, and AI-powered analysis tools to achieve synergies in terms of accuracy, explainability, and scalability.
Improve code quality through automated unit test generation
Unit testing is a key means of maintaining code quality and preventing regression errors. However, in reality, unit tests are difficult to write, time-consuming, and prone to omission depending on the writer’s capabilities and time constraints.
To overcome these limitations, LLM-based test code auto-generation technology has been rapidly adopted recently, and it is gaining attention as a new approach that improves code coverage and simultaneously increases developer productivity and quality.
LLM has the ability to understand code context and control flow, and generate appropriate test cases. The basic flow of operations is as follows:
- Parsing the signature and body of the method to be analyzed
- Derive test scenarios based on input types, condition branches, exception flows, etc.
- Insert into a template suitable for a test framework (such as JUnit).
- Automatically configure mock objects, assertions, boundary values, and more.
[Example: Target code]
public class Calculator {
public int divide(int a, int b) {
if (b == 0) throw new IllegalArgumentException("Division by zero");
return a / b;
}
}
[GPT-based automatic generation test example (JUnit 5)]
@Test
void testDivide_ValidInputs() {
Calculator calc = new Calculator();
assertEquals(2, calc.divide(4, 2));
}
@Test
void testDivide_DivideByZero() {
Calculator calc = new Calculator();
assertThrows(IllegalArgumentException.class, () -> calc.divide(4, 0));
}
Like this, LLM can understand the meaning of code and automatically generate tests for normal and exceptional cases.
To generate automated tests, AI analyzes the following code elements:
| Element | Role | Example |
|---|---|---|
| Parameter Type | Estimate the valid range of input values | int, String, List<?> |
| Conditional Statements (if, switch) | Generate test branches for boundary conditions | if (x > 100) → x=99, x=100, x=101 |
| Exception Handling | Induce failure cases | throw new IllegalArgumentException(…) |
| Dependency Injection | Determine whether to create mock objects | UserService userService = … |
By combining this information, models such as GPT can automatically configure multiple test scenarios rather than a single one.
AI Strategy for Improving Unit Test Quality
AI can automatically generate unit test code, but mechanically generated test code does not guarantee that it will be immediately executable and of meaningful quality in practice.
Therefore, utilizing the following strategic elements can greatly improve the practicality and reliability of the generated test code.
1. Utilizing dependent class code through dependency analysis
When AI analyzes test subjects, its ability to automatically identify dependent classes that are internally called or used by the class and include them in the test plays a major role in improving the quality of the generated test code.
For example, consider the following code:
public class UserService {
private final UserRepository repository;
public UserService(UserRepository repository) {
this.repository = repository;
}
public User findUser(long id) {
return repository.findById(id).orElseThrow(() -> new NotFoundException());
}
}
AI does not simply test UserService, but must analyze UserRepository as shown below to configure appropriate virtual (mock) behavior:
@Test
void testFindUser_Found() {
UserRepository repo = mock(UserRepository.class);
User user = new User(1L, "test");
when(repo.findById(1L)).thenReturn(Optional.of(user));
UserService service = new UserService(repo);
User result = service.findUser(1L);
assertEquals("test", result.getName());
}
Thus, dependency analysis enables accurate context mocking¹, reduces the generation of unnecessary NullPointerException avoidance code, and is essential for creating truly meaningful test flows.
2. Automatic validation of unit tests through the Java compiler
AI-generated tests may appear grammatically correct, but errors frequently occur during compilation. For example:
- Missing imports inside a test class
- Calling private methods directly
- Calling non-existent fields or methods
To prevent such problems in advance, it is essential to have a structure in which the generated test code is pre-compiled using the Java Compiler API or javac, and if it fails, the error details are fed back to the AI.
3. Verifying unit test execution using JUnit Runner
Testing alone does not have much value. In fact, it can be said that only when success and failure are distinguished and meaningful results are achieved can value be proven and product quality be improved.
To this end, tests generated by AI must be automatically executed through JUnit Runner, and an automated feedback loop must be established to derive results in the following manner, analyze failures through AI, and regenerate test code based on the results.
[Example: Results of running the generated test code through JUnit Runner performed by the Kakao Test Generation Agent]
{
"status": "FAILED",
"summary": "5 tests found.\n4 tests successful.\n1 tests failed.\n",
"errorLog": "\nFailures (1):\n testAverageWithSingleElementArray()\n MethodSource [className = 'com.kakao.quality.sample.AverageCalculatorTest', methodName = 'testAverageWithSingleElementArray', methodParameterTypes = '']\n => org.opentest4j.AssertionFailedError: expected: <-3.3> but was: <-3.0> [...]\n",
"failedTestMethodList": [
{
"className": "com.kakao.quality.sample.AverageCalculatorTest",
"methodName": "testAverageWithSingleElementArray",
"failedMessage": "expected: <-3.3> but was: <-3.0>"
}
],
"passedTestMethodList": [
{
"className": "com.kakao.quality.sample.AverageCalculatorTest",
"methodName": "testAverageWithMixedNumbers"
},
[...]
]
}
Accurately separate and manage failure and success methods along with failure logs, and reanalyze failure logs to modify AI-generated test code so that it can be executed normally.
[Example: AI analysis results for failure logs generated by the Kakao test generation agent]
{
"AiMessage": {
"text": "(1) `testAverageWithSingleElementArray`\n*
Cause: The failure log likely indicates a mismatch between the expected and actual output for the test case `assertEquals(-3.3, calculator.average(new int[]{-3, -3, -3}), 0.001);`. The test is incorrectly written because it is trying to test the average of an array with identical elements, and the expected value set in the test is incorrect. The expected average of the array `{-3, -3, -3}` should be `-3.0`, as all elements are `-3`, and the average would also be `-3.0`, not `-3.3`.\n\n*
How to fix: Correct the expected value in the `testAverageWithSingleElementArray` method for the test case involving an array with the elements `{-3, -3, -3}`. Change the expected value from `-3.3` to `-3.0`.\n\nHere's the corrected test method:\n\n```java\n@Test\npublic void testAverageWithSingleElementArray() {\n [...]"
}
}
4. Coverage measurement and incremental evaluation using JaCoCo modules
When AI generates test code, one of the most reliable quality indicators is the increase in code coverage.
To this end, we integrate coverage measurement tools such as JaCoCo² after test execution to quantify actual coverage.
[Example: Coverage variation results performed by the Kakao test generation agent]
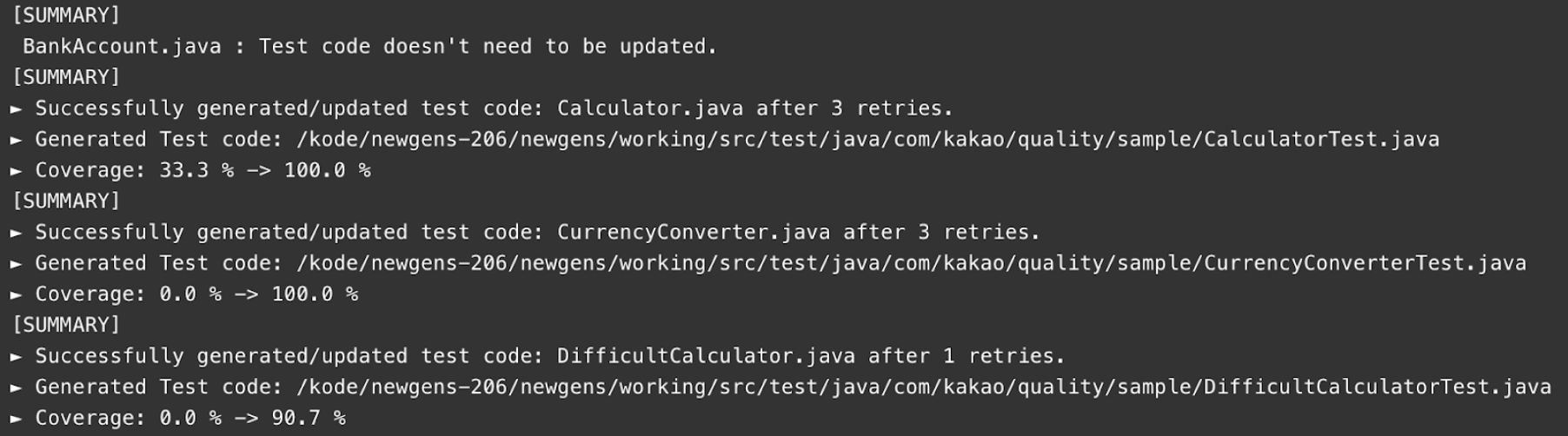
Increased coverage goes beyond simply proving that tests “exist”; it provides substantive evidence that existing coverage blind spots have been filled. In addition, these results can be automatically registered as badges in PR during code reviews, improving quality visibility.
5. Utilization of Jaro-Winkler/Levenshtein-based similarity code
By analyzing test code previously generated by AI or similar test classes within a project, we can improve the quality of generated test code by reusing structures, paths, and patterns similar to existing test flows.
To this end, string distance algorithms such as Jaro-Winkler and Levenshtein can be used to automatically analyze the following.
| Criterion | Usage |
|---|---|
| Class Name Similarity | OrderService, OrderHandler, OrderManager → Detect common units |
| Reverse Class Name Similarity | OrderService, MemberService, AccountService → Detect similar pattern logic |
| Similarity to Existing Tests | Determine possibility of cloning the structure of OrderServiceTest.testCalculateTotal() |
[Sample code (Levenshtein Distance):]
LevenshteinDistance levenshtein = new LevenshteinDistance(threshold)
int distance = levenshtein.apply(aClass.getCode(), bClass.getCode());
This approach contributes to maintaining consistency in test generation, preventing duplicate feedback, and enabling pattern-based optimization. It also enables the generation of high-quality tests while maintaining consistent code conventions based on existing test assets within the project.
Real-time code review and automated test generation integration
Unit test auto-generation is not limited to simple IDE tools, but is most effective when integrated in real time with code reviews or PRs.
Here is a recommended workflow for test automation linked to real-time code reviews:
- PR creation → Detection of changed classes
- Request automatic test generation
- Generated test code is automatically committed to PR or suggested as a comment.
- Test Coverage Badge Update (JaCoCo Integration)
[Example: PR review comments made by the Kakao test generation agent]
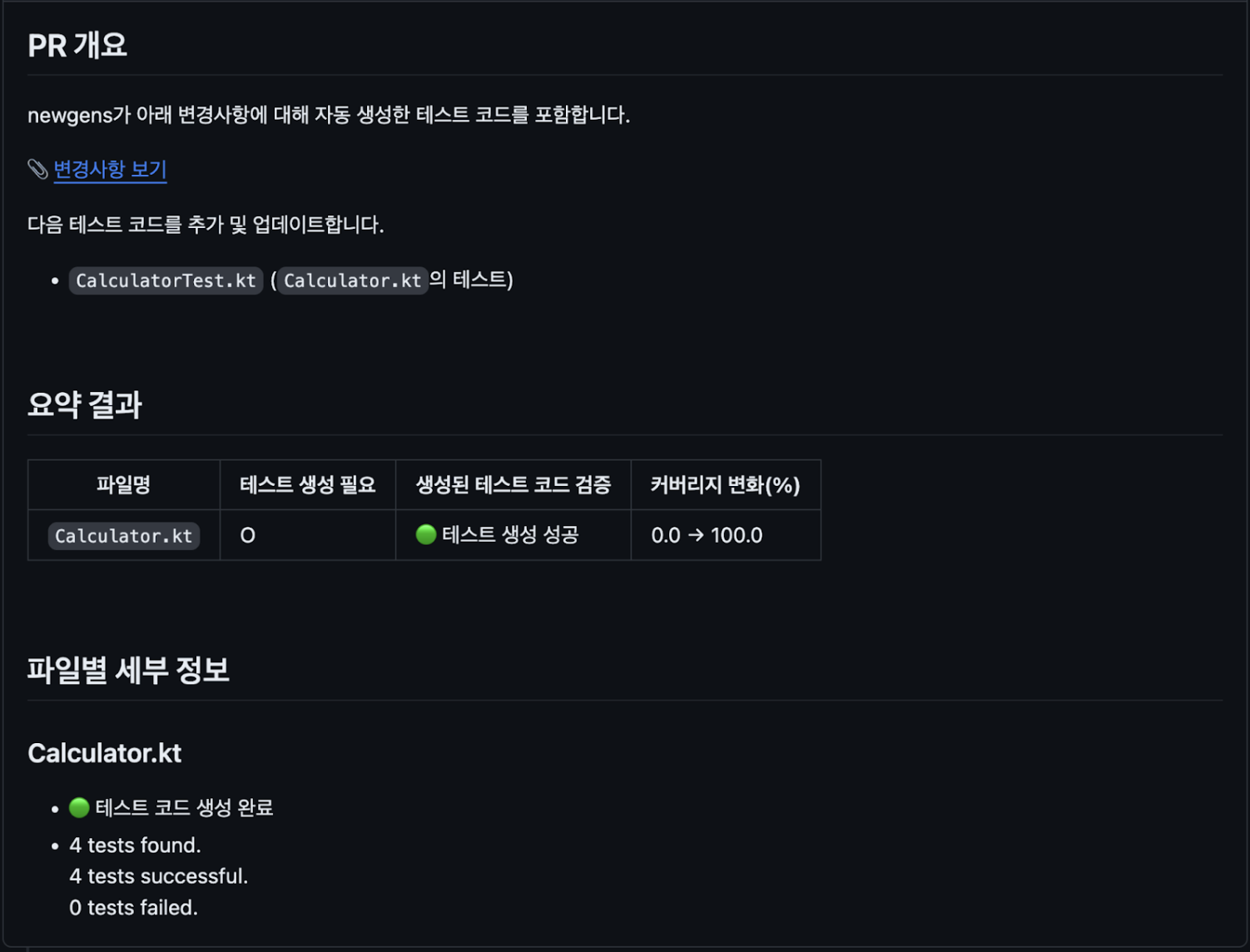
As described above, the following strategies are important for turning AI-generated test code into high-quality assets:
- Accurate mock class code configuration through dependency analysis
- Prevent failures with compiler-based validity checks
- Ensuring the effectiveness of JUnit execution-based testing
- Quantifying performance through JaCoCo coverage measurement
- Ensuring test quality and consistency with similarity-based reuse strategy
When all these elements are combined, AI-based test generation can go beyond simple automation and become an integral part of a reliable QA process.
Quality control through automated pipelines
The AI review, static analysis, and test auto-generation technologies discussed earlier enable real-time code quality management, but this is just the beginning.
Now, we need an automation pipeline that integrates each technical element into an organic flow rather than isolated functions.
Review and quality control based on agentic workflow
Agentic Workflow is an architecture in which specialized agents autonomously make decisions and collaborate with each other to perform the entire review process according to each quality control stage.
The following is an example of an agentic workflow configuration for Kakao’s code quality integration agent.
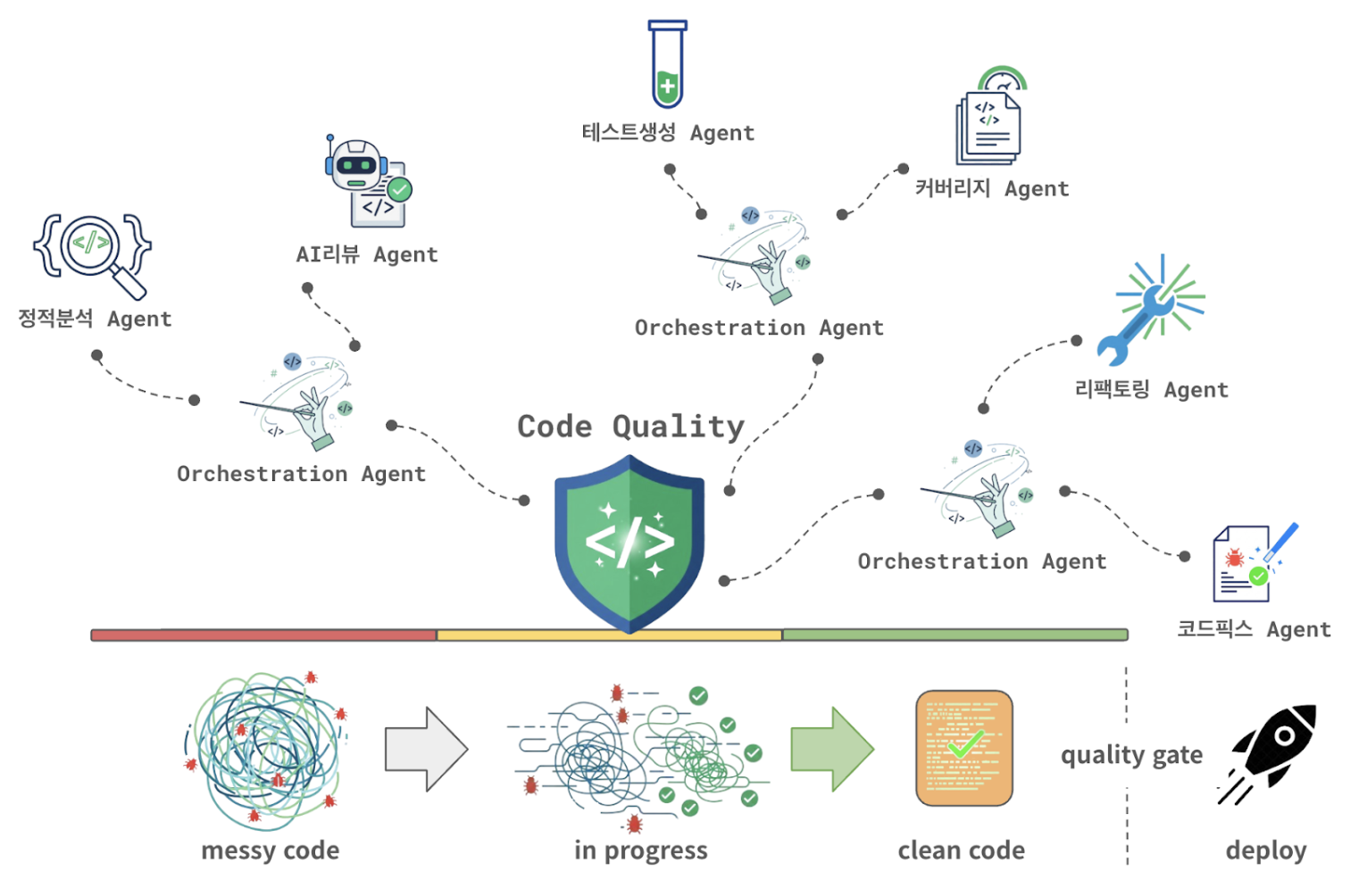
Starting with code change detection, the code quality integration agent works with multiple intelligent agents to dynamically determine and modify code to ensure safe deployment. These complex quality assurance processes can be organized into agentic workflows and flexibly automated.
Scenarios for linking with development productivity improvement tools
Agetic Workflow should not stop at code quality automation, but should also integrate with collaboration tools such as Jira, KakaoWork, GitHub, and distribution management tools such as KakaoRelease to guide and support the actual actions of developers.
The following is an example of a linked scenario.
- Automatically track related Jira tasks when creating PRs (pull requests)
- AI review result summary notification in KakaoWork (if risk level is 80% or higher)
- Indicate missing tests or release blocking criteria in GitHub PRs
- Automatically organize modules with low test coverage into Confluence Wiki documents
- Provide code quality scores to Kakao Releases for distribution management
Footnotes
1) Context Mocking is a testing technique in which the “context” (environment or state information) that specific code or components depend on is replaced with a virtual (mock) object rather than the real one during software testing.
2) JaCoCo (Java Code Coverage) is an open-source tool and library used to measure the code coverage of Java applications.