TOC
Generating TOC...
3.2. QA Test automation using DeviceFarm AI
The era of “super apps” that handle everything from shopping and payments to banking in a single app. As more features are added, the number of scenarios that QA must verify increases exponentially. It is nearly impossible for humans to test all routes.
In response, the development industry introduced script-based automation (Appium, Selenium, etc.), but soon encountered new problems:
- Fragile script: Even changing a single button caused errors in the script, increasing maintenance costs.
- Unpredictable environment: There were numerous reasons for script failure, including various devices, OS versions, network speeds, and sudden pop-ups.
Ultimately, script-based automated testing remained “occasionally helpful,” and testing was still not automated, requiring a significant amount of time and resources.
Challenges of existing UI testing
Many companies and teams have adopted existing UI testing automation tools such as Appium, but the following issues make it difficult to fully leverage the benefits of automation in actual business environments:
- Frequently changing element ID/XPath: If the app structure or UI changes frequently, existing test scripts will not work. QA must then track this down and repeat the corrections, resulting in ongoing maintenance costs.
- OS and app version fragmentation: Test failures may occur due to differences in the location of UI elements on each device due to differences in device, OS version, resolution, and app build.
- Timing issue: Network latency, animation processing, and differences in rendering speed prevent actions from being performed at the “right moment,” resulting in test failures.
- Rigidity in error response: It is difficult to respond with scripts to unexpected pop-ups (OS, app), notification windows, and exceptions that occur on actual devices.
Examples of UI testing using AI
Recently, there have been studies and cases that go beyond the limitations of existing methods by utilizing LLM and AI-based tools.¹
- AutoDroid²
- This is a representative example of an approach that understands test scenarios written in natural language used by humans and converts them into actual mobile UI actions.
- Fastbot³
- This approach combines APK file analysis and reinforcement learning to autonomously generate and explore test scenarios.
- Firebase Testing Agent⁴
- This is a service that automatically tests apps. Recently, AI-based test agents have been introduced, enabling more intelligent testing.
DeviceFarm QA agent
Recent advances in AI and LLM are opening up new possibilities for test automation. As global IT companies are attempting AI-based test automation, Kakao has launched an AI-based UI test automation project utilizing its existing DeviceFarm⁵ infrastructure.
In this chapter, we will share our experiences and actual implementation cases gained while developing an AI-based UI test automation system.
AI-based test automation through QA agents
DeviceFarm QA Agent is an AI-based UI test automation solution created to overcome the limitations of existing manual testing and script-based automation.
DeviceFarm provides a web-based remote device testing environment that supports both Appium script execution and manual testing. QA agents operate on top of the DeviceFarm service, interpreting natural language test cases written by QA engineers to perform tests autonomously and report results in detail.
QA agents utilize LLMs to understand test cases and accurately determine the current status of apps using accessibility information and screenshot APIs provided by DeviceFarm for Android applications. Based on this information, we decide on the next steps and repeat the process of automatically verifying that the tests were performed correctly.
Making AI understand “human speech”
In order for AI to perform tests, it must first understand exactly “what” it needs to do. QA agents start by refining ambiguous test scenarios written by humans into structured steps that can be clearly understood by LLM.
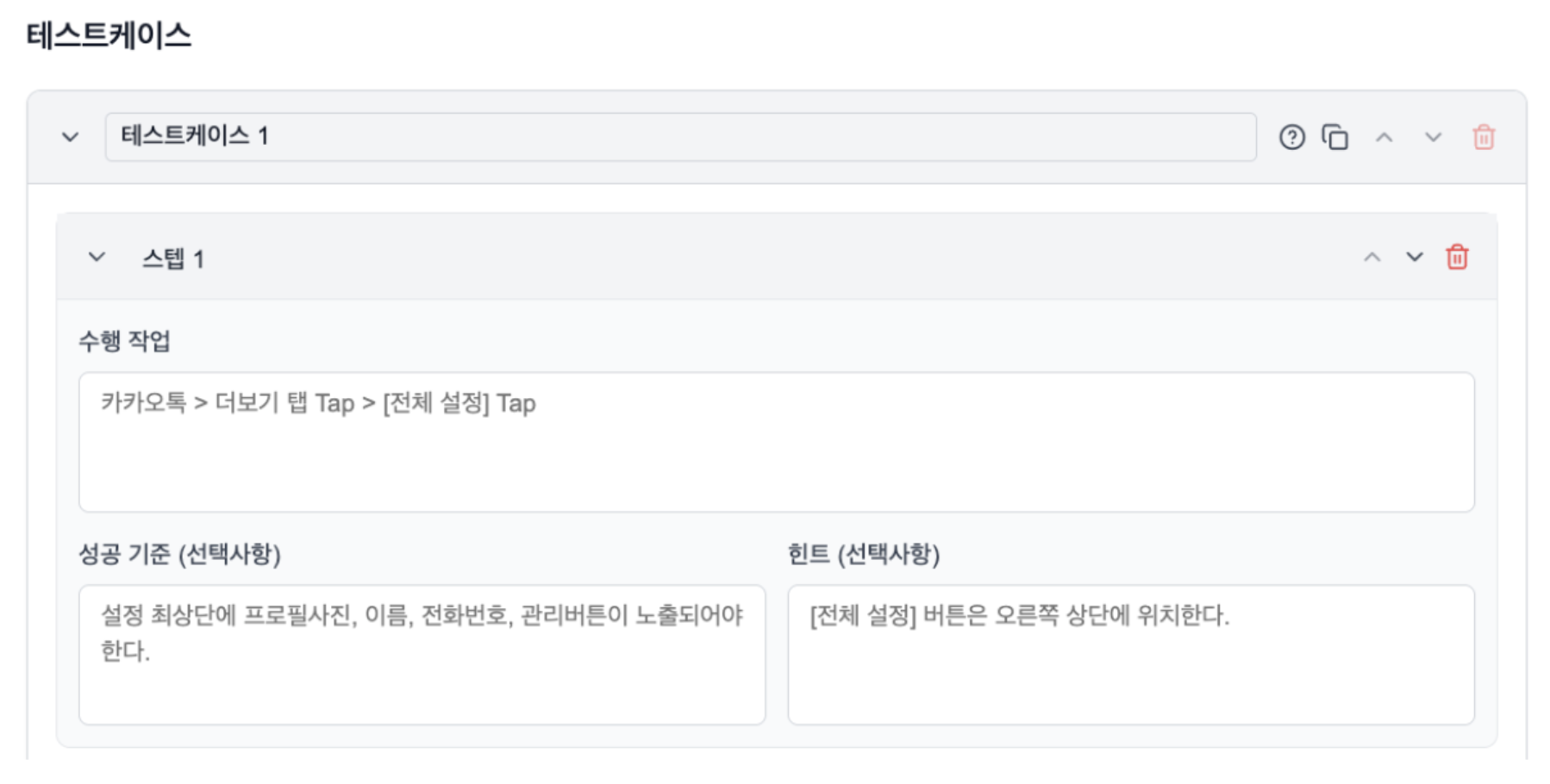
- Existing QA test cases (Kakao Map)
- Test sentence: Quick Tap > [Navigation] > My Places > [Get Directions]
- Expected results: Does the car navigation screen move to the selected destination and display the navigation route on the destination?
- Structured test cases for QA agents
- Test case name: Check the built-in navigation feature
- Step 1: Log in
- Objective: Launch Kakao Map and log in with your Kakao account.
- Success criteria: Your profile image must be visible and you must be logged in.
- Step 2: Run route guidance
- Objective: Tap “Navigation” on Quick Tap, then tap “Get Directions” in the My Places area.
- Success criteria: Go to the car navigation screen and set your destination as your location.
Only by clearly defining the goals and success criteria for each stage can AI determine what it needs to do and when it has succeeded.
Core operating principles: See, think, and act
QA agents that receive structured test cases perform tests autonomously by repeating the cycle of [recognition → decision → execution].
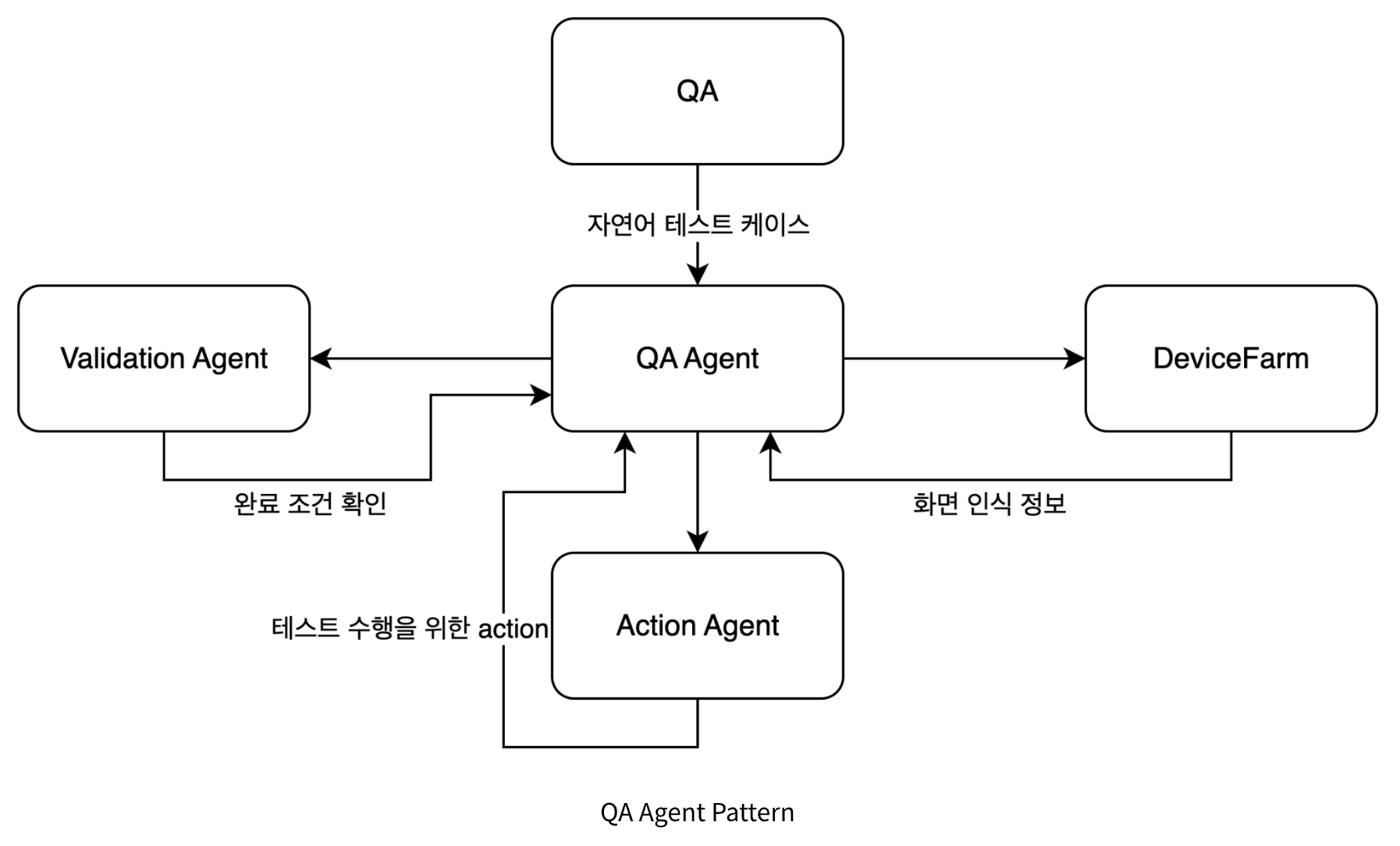
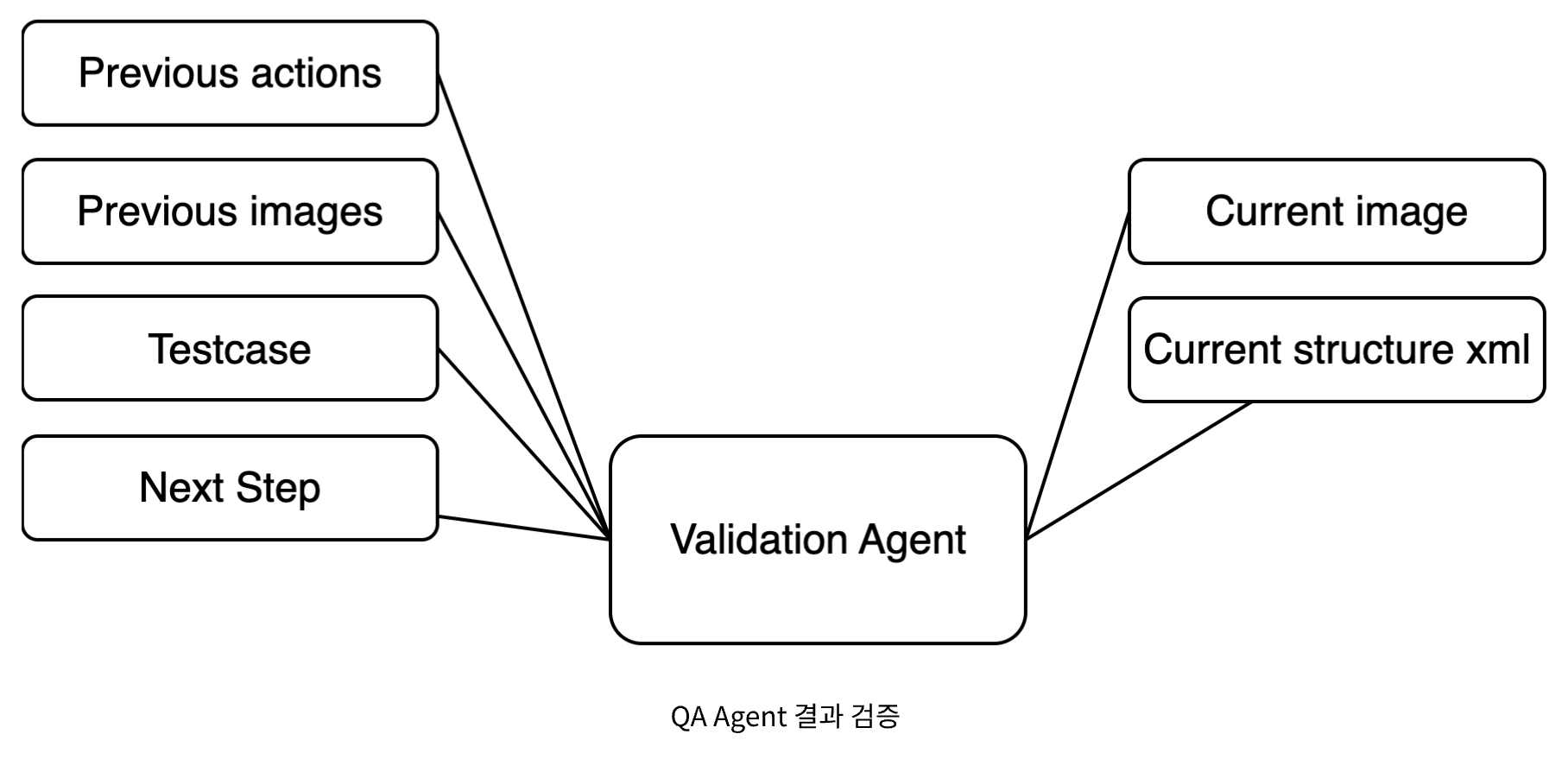
Recognition: How do you ‘see’ the screen?
Just as a person sees a screen with their eyes, QA agents use two pieces of information—the Accessibility API and screenshots—to understand the current screen. When specific information is needed, DeviceFarm’s API is called to get the information.
Process the data obtained through the accessibility API. Perform normalization mainly on data necessary for test execution and convert it to XML.
If necessary, use icon identification and OCR to add icon and text information to XML.
Decision: How does LLM “think”?
Once the screen analysis is complete, the QA agent passes this information to the LLM to determine the next course of action. The core of this process is prompt engineering. The LLM is provided with a prompt containing the test objective, a summary of previous actions, and information about the current screen analysis.
LLM synthesizes the given information and outputs the next action in the form of logical commands. For example, if it decides to press the “Navigation” tab, it returns the following result:
{ "action": "tap", "element_id": 12, "reason": "내비 탭을 누른다" }
Execution and verification: How do robots move?
The logical commands determined by the LLM are transmitted to the QA agent system and converted into physical execution coordinates. For example, element_id: 12 information is used to determine the actual tap coordinates `(x: 1000, y: 500) is converted.
These coordinate-based commands are executed on actual devices via the DeviceFarm API. QA agents know all available actions, such as tapping, swiping, and text input, in advance in the form of APIs.
After the action is executed, the QA agent returns to the recognition stage to check for any changes on the screen. This process is repeated, and testing continues until the final success criteria are met. Thanks to this structure, QA agents have resilience, enabling them to continue testing based on their objectives even if the UI changes slightly or unexpected pop-ups appear.
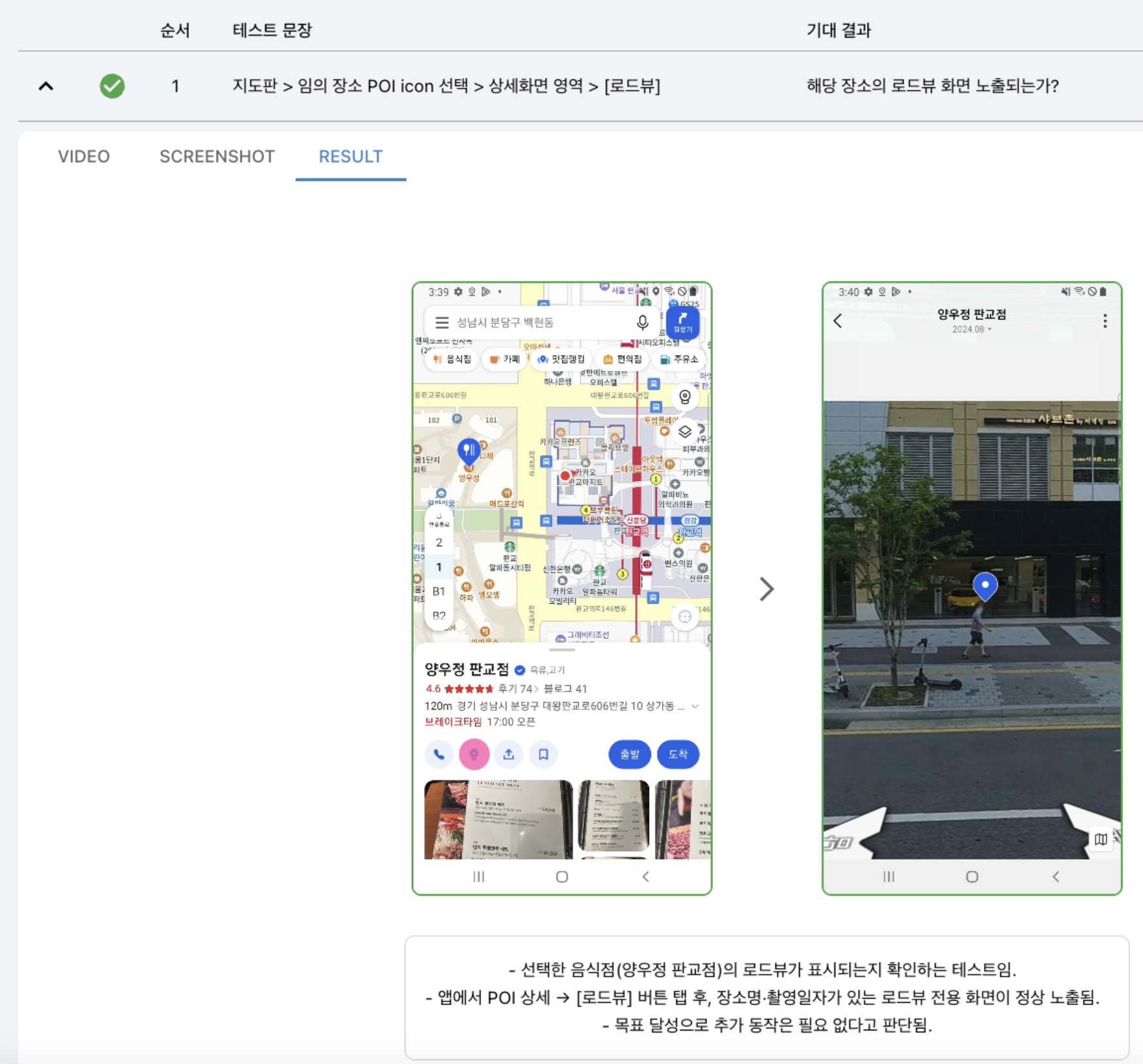
Providing results for each test case
Once testing is complete, we provide detailed results reports including success/failure status, failure cause analysis, and step-by-step screenshots and videos to help users quickly identify and fix problems.
The Evolution of QA Agents
QA agents are not stopping here, but continuing to develop more intelligent test automation.
AI that understands the “intent” of services with the introduction of RAG
- Building RAG based on QA test cases
- Planning, design, coding, and testing deliverables-based RAG construction
- QA agents query RAG when performing tests to understand the context and expected behavior more accurately.
- Combine natural language test cases and information extracted from RAG to generate an action plan.
Test case creation
Ultimately, QA agents aim to generate test cases. A bottom-up approach that analyzes APK files to understand all the features of an app, and extracting core business scenarios through RAG.and verify them on your own. We are moving toward automatically generating and executing tests that are appropriate for the context of the service without human intervention, thereby maximizing coverage.
- Bottom-up perspective
- APK analysis-based scenario generation: Analyzes APK files statically/dynamically to extract app screen, status, and transition (action) information.
- Automatically build state-action graphs and explore possible user flows.
- Domain knowledge extracted from RAG (Knowledge Base) (e.g., Key features, policies, UI elements) is used to create meaningful scenarios (e.g., payment, membership registration, etc.) to encourage testing.
- Similar to Fastbot and AutoDroid, it automatically covers unexplored paths and exceptional situations through reinforcement learning and agent-based exploration.
- Top-down perspective
- Reinforcement of domain knowledge-based scenarios: Scenarios extracted from higher-level requirements such as planning, design, and QA test cases (e.g., “Login and payment must be completed normally”) are searched and extracted from RAG.
- The extracted scenarios are mapped to the APK analysis results (state-action graph) to automatically verify whether the corresponding flow is implemented in the actual app.
- If the upper scenario is missing from the implementation or behaves differently than expected, it will be automatically reported.
- Combine top-down scenarios and bottom-up exploration results to maximize test coverage and reliability.
Footnotes
1) [Source] https://devocean.sk.com/blog/techBoardDetail.do?ID=166778
2) [Source] https://autodroid-sys.github.io/
3) [Source] https://mp.weixin.qq.com/s/QhzqBFZygkIS6C69__smyQ
4) [Source] https://firebase.blog/posts/2025/04/app-testing-agent
5) Kakao’s in-house Appium-based mobile test automation system