TOC
Generating TOC...
4.3. Building a harmful image classification system
The initial situation was clear. The amount of image content is growing exponentially, but the number of people who can review it is limited. 100% manual review not only increased operational fatigue, but also posed structural problems that made it difficult to maintain consistency due to different judgment criteria among individuals. This project began with the very practical and clear goal of “reducing the absolute number of images that need to be reviewed by humans.”
“How can we reduce the number of images that people need to see?”
The goal of establishing a harmful image classification system was to overcome the limitations of manual review of rapidly increasing image content within Kakao services and to ensure operational efficiency and consistency in judgment.
Initial exploration: Exploring the potential of CNN-based classification
Before developing a full-scale AI model, we went through an exploratory phase to understand the nature of the problem by testing several basic approaches.
The first thing we tried was similar image search technology, which could immediately improve operational efficiency. Since the same harmful images were often uploaded repeatedly, we built a system that automatically filters out images that have already been judged as harmful by extracting the features of the images as vectors and comparing their similarity using the Approximate KNN¹ (K-Nearest Neighbors) technique. This was a significant first step toward reducing the number of items requiring manual review.
At the same time, we tested the performance of CNN² (convolutional neural network) -based models to classify new types of harmful images. We conducted various experiments, such as utilizing several models that were publicly available at the time, such as Inception-ResNet-v2, and applying basic ensemble techniques to overcome the limitations of a single model.
This initial exploration process provided important lessons. Simply applying publicly available examples was not enough to solve the speed and resource usage issues encountered in the actual service environment. We concluded that a model that considers not only accuracy but also efficiency in actual service environments is necessary, and this became a stepping stone for the project to move forward to the next stage.
First stage of development: Introduction of EfficientNet - The beginning of full-scale AI model development
At this point, we encountered EfficientNet³ and began our journey into AI model development in earnest. The core of EfficientNet lies in its “compound scaling⁴” methodology, which involves expanding the depth, width, and resolution of the model in a balanced manner according to a predetermined ratio, rather than simply increasing them indiscriminately.
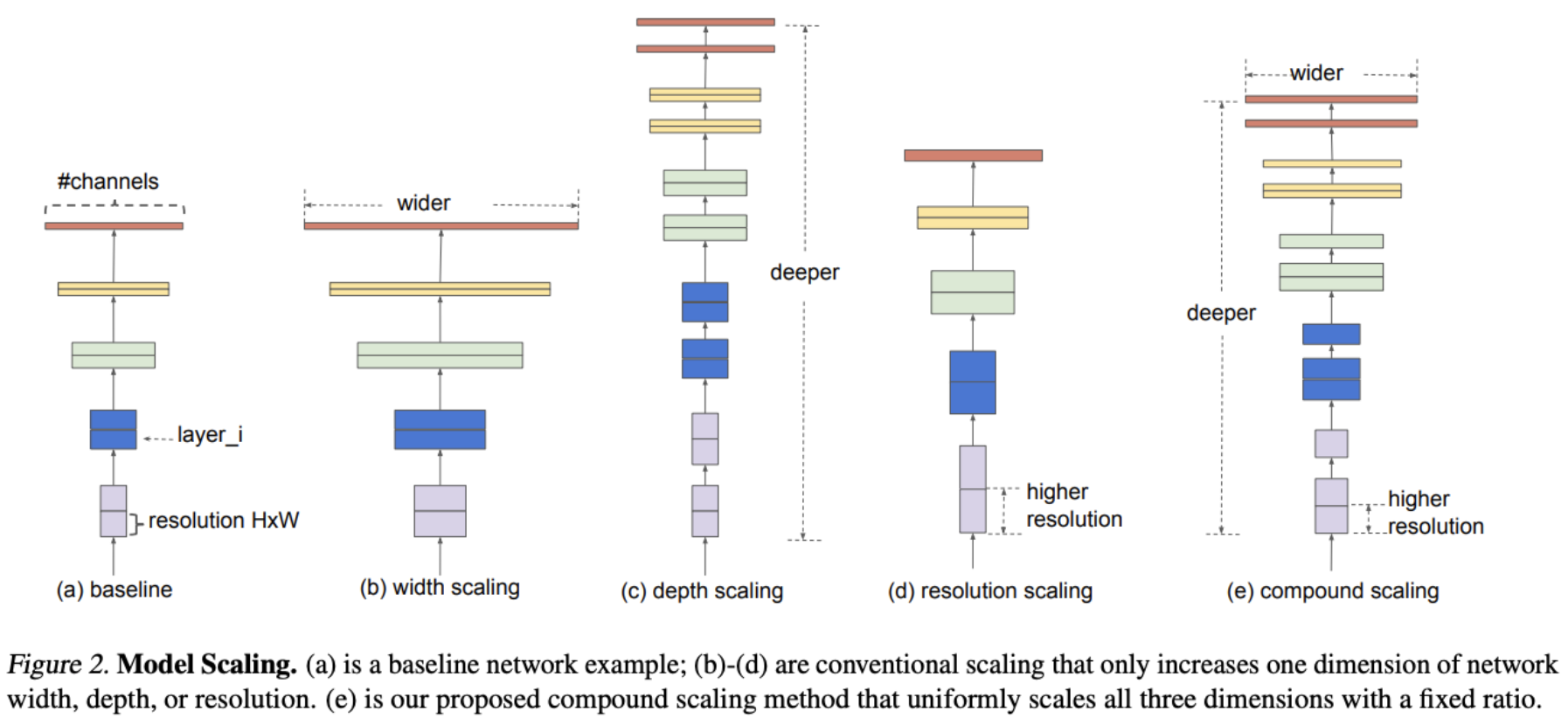
However, no single model could be optimal for all situations. We had to strike a balance between accuracy and speed according to the requirements of the service.
- EfficientNet-B0: The model size is very small and the inference speed is the fastest. Applied to lightweight services and mobile clients where real-time performance is critical.
- EfficientNet-B4: Provides higher accuracy. Used for core filtering and server-side batch processing that require high reliability.
Through this strategy of flexibly selecting models appropriate for each situation, we were able to substantially improve service operation efficiency by maintaining similar accuracy to existing test models based on EfficientNet-B4, while increasing inference speed by approximately 1.8 times and reducing the number of model parameters to 1/4.
Second development: Swine Transformer - Understanding the “context” of images
CNN-based models are strong at recognizing local patterns in images, but they have relative weaknesses in understanding global relationships and context across the entire image.
As a solution, we chose Window-based Self-Attention⁵.
There were limitations in applying existing Transformer models directly to images. This is because calculating the relationships between all pixel fragments in an image at once requires too many operations, making it inefficient.
Swin Transformer⁶ solves this problem in a very clever way. It is to divide the image into multiple windows and view them. Instead of analyzing the entire image at once, we calculate the relationships between pixel fragments only within small windows. This dramatically reduces the amount of calculations required.
However, there is one problem with this method. The windows are separated from each other, so Window A cannot see what is happening in Window B.
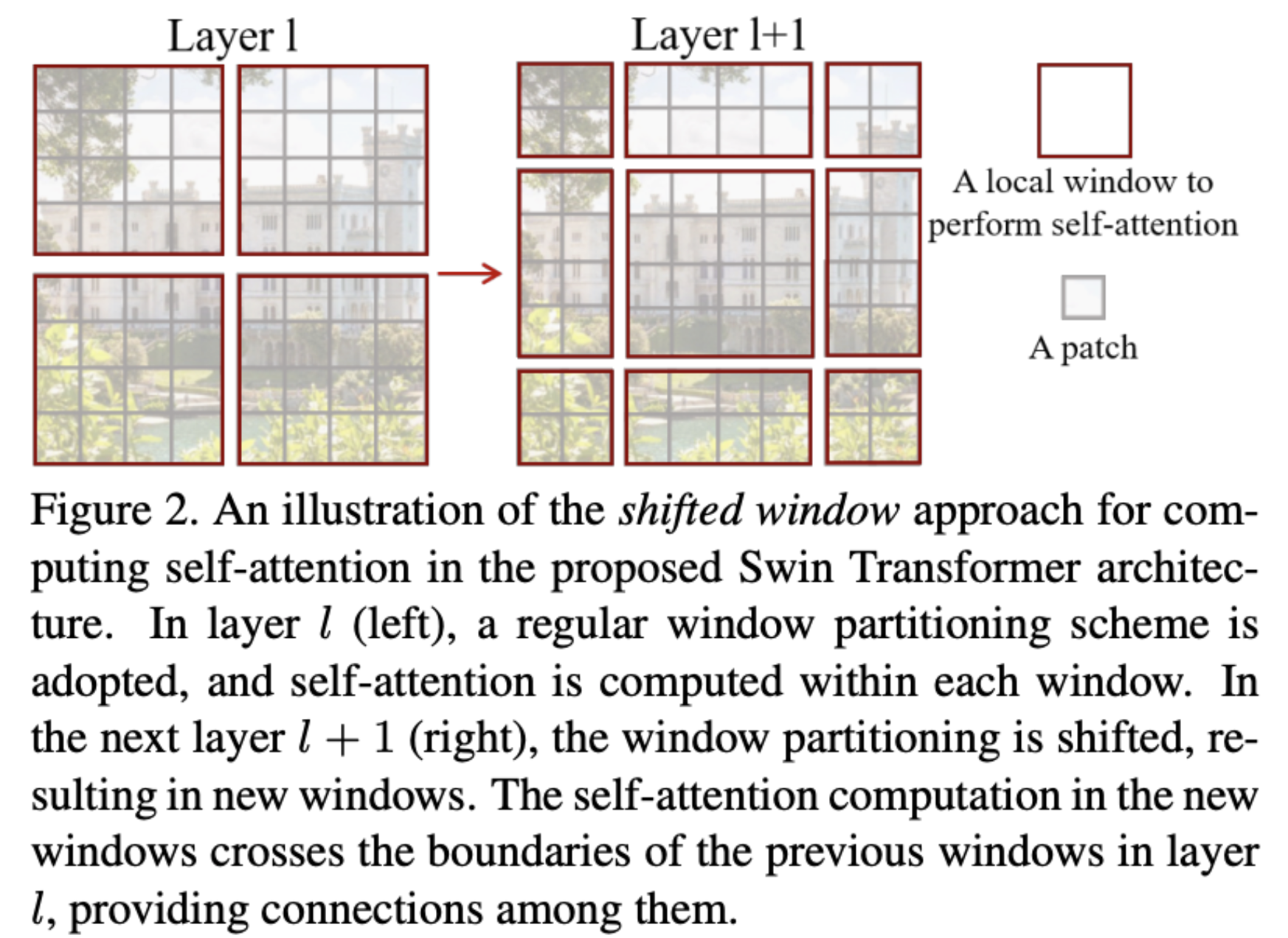
To solve this problem, Swin Transformer slightly shifts the position of the window in the next step. By overlapping windows in this way, pixel fragments that belonged to different windows in the previous step can now meet and form relationships within the new window. By alternating between “fixed windows” and “moving windows,” computational efficiency is increased while ensuring that information beyond the window is not lost, enabling effective learning of the context of the entire image.
As a result, the biggest achievement after introducing Swin Transformer was performance stability. It is common for models that performed well on training and validation datasets to perform poorly when deployed in actual service. However, Swin Transformer demonstrated robustness by maintaining stable metrics even with various unpredictable images from real servers. In particular, the ability to distinguish between ambiguous images that were frequently misclassified in the past has been greatly improved.
Key findings: High-quality labeling data is more important than model architecture.
We have steadily improved model performance by introducing the latest architecture such as Swin Transformer. However, at some point, the performance improvement gained from changing the model structure alone gradually decreased. After analyzing the false positive cases that remained unresolved, we found that the problem was not with the model, but with the data.
- Ambiguity in labeling: The criteria for “sexuality” were interpreted differently by each labeler.
- Inconsistency in labeling: There were cases where the same image was labeled differently by different labelers at different times.
This realization was a turning point that changed the direction of the project by 180 degrees. It was the moment when the paradigm of thinking shifted from “model-centric” to “data-centric.” We have empirically confirmed that creating cleaner and more consistent data has a much greater impact on performance improvement than striving to find a better model.
Data labeling for AI
The quality of data ultimately determines the performance of AI models. In particular, in domain-specific fields such as harmful image classification, incorrect labels can undermine the reliability of the entire service. However, securing high-quality labeling data was a more complicated issue than we had anticipated.
The biggest issues were cost and time. The amount of content that a skilled labeler could process in a day was limited, especially complex exception cases. Furthermore, labeling criteria differed between labelers, often resulting in different results for the same content.
We have decided to address this issue in three ways. First, we intelligently selected data for labeling through active learning⁷. Second, we improved the labeling environment by applying cognitive psychology principles. Third, we built a collaborative system in which AI assists human judgment.
Active Learning: The model selects data to learn on its own
Active Learning is a technique in which a model selects the data that will be most helpful to itself and requests labeling from a human. The core idea is that focusing on “difficult” data that confuses the model is more efficient than adding labels to “easy” data that the model already fits well.
The query strategy that determines which data the model selects determines the success or failure of active learning. We tested various strategies and ultimately reviewed two main strategies.
- Uncertainty Sampling: This is a method of prioritizing data that the model is unsure about in its predictions. Among these, we applied the entropy sampling⁸ method, which selects samples with high entropy from the model’s prediction distribution.
- Committee-based queries (Query-by-Committee, QBC): Create a “committee” consisting of multiple models and select the data for which the opinions of the committee members differ the most. This method combines the prediction results of multiple models trained with different initial values to find the most controversial cases.
[Comparison of performance and operational efficiency by query strategy]
| Query Strategy | Labeling Performance Improvement | Computing Resources | Speed of Selecting Labeling Targets |
|---|---|---|---|
| Entropy Sampling | ★★★ | ★ | ★★★★★ |
| Query-by-Committee | ★★★★ | ★★★★★ | ★ |
Initial review confirmed that query-by-committee contributed more to improving labeling performance. This is because we were able to effectively identify truly difficult cases by leveraging the collective intelligence of multiple models.
However, other factors also had to be taken into consideration in the actual operating environment. Since QBC needs to run multiple models simultaneously, GPU memory usage increased exponentially, and inference time increased proportionally. Considering the amount of images that need to be processed every day, this overhead was not realistic.
On the other hand, entropy sampling showed smaller performance improvement than committee-based queries, but had several advantages.
- Resource efficiency: Minimal memory usage due to use of a single model
- Processing speed: Fast processing close to real time
- Operational stability: No need to manage complex model ensembles
- Scalability: Suitable for large data processing
Ultimately, we adopted the entropy sampling method, which strikes a practical balance between performance and efficiency. Although this was a choice of a workable alternative rather than perfection, it was a more suitable choice in the actual service environment.
Improvement of cognitive psychology-based labeling tools
Existing labeling tools provided labelers with excessive information at once, distracting them from their core judgment tasks. To solve this problem, we completely redesigned the labeling interface based on cognitive psychology theory.
We systematically analyzed the cognitive load of the existing system to identify the root causes that hinder the efficiency of labeling work. According to cognitive psychology’s cognitive load theory, human working memory has a limited capacity for processing information at any given time. As suggested by Miller’s study “,” people can only effectively process 5 to 9 units of information at a time.
Analysis of existing labeling tools revealed that more than 10 information elements were displayed simultaneously on a single screen. Most of the information was additional information that was not directly related to the actual labeling judgment, and the important images and judgment buttons only occupied a small part of the entire screen.
[Analysis of problems by cognitive load type]
| Type of Cognitive Load | Problems in Existing Systems |
|---|---|
| Intrinsic Load | Cognitive complexity caused by complicated decision criteria |
| Extraneous Load | Distraction caused by unnecessary UI elements |
In addition, we analyzed usage patterns of the existing system to identify factors that hinder the efficiency of labeling work. Most images could be handled adequately with a two-step process of “image confirmation → immediate judgment,” but the existing interface was designed in a way that hindered this process.
Work Process Analysis:
- Ideal process: Check image → Make immediate decision (in most cases)
- Complex cases: Check image → Check reference information → Make a decision (if the inherent load is high)
- Actual existing system: Cognitive interference caused by unnecessary information exposure
The main problem was that the ratio of metadata to labeling content (images) was excessively high. The more serious problem was that most of this metadata was not helpful at all in making actual labeling decisions.
For example, unnecessary information such as “Is it necessary to display the image file size as text?”, “Will the upload time information help determine the harmfulness?”, and “Will the file name affect the labeling quality?” took up a significant portion of the screen, while the actual images were displayed in a small area. In addition, really necessary reference information was mixed with unnecessary meta information, making it difficult to recognize immediately.
Problem solving through UI/UX redesign of labeling system
Through analysis of the existing system, we have established the following key areas for improvement.
- Image-centric layout: The images, which are the core of labeling, are placed larger than before on the screen so that we can be focused on immediately.
- Remove unnecessary information: We removed meta information (RGB values, histograms, image sizes, etc.) that is not helpful for judgment from the screen.
- AI assistance
- Visual evidence: GradCAM highlights areas of interest identified by AI with colors
- Similar images provided: Similar case images used by AI as basis for judgment
- Text interpretation: Interpret image content as text and highlight key words in color
First, we simplified the complex information structure of the existing system as follows:
[Re-establish information element priorities]
| Priority | Information Element | Placement Method | Basis for Improvement |
|---|---|---|---|
| 1st Priority | Main Image | Large display on the left side of the screen | Place the core labeling target by applying the F-pattern principle |
| 2nd Priority | AI Auxiliary Information | Right panel | Reference when judgment is difficult |
| Remove | Metadata | - | Information unnecessary for judgment |
The screen layout has also been improved as follows:
[Comparison of labeling interface before and after improvement]
Before improvement:

After improvement:

When redesigning the labeling system, we also implemented the following AI assistance features:
- GradCAM visualization: The image areas where AI is believed to have influenced the judgment are highlighted in color to focus the labeler’s attention on those areas.
- Judgment basis image provided (“low exposure image”): Provide supporting information in the form of images that are believed to help AI determine the label for the current image, thereby assisting the labeler’s decision.
- Image text interpretation: Interpret the image content as text, such as “A cute cartoon character is holding hands on the beach,” and highlight key elements in color.
Furthermore, Allan Paivio’s Dual-Coding Theory⁹, we provided both visual and verbal information.
- Visual information: Image, GradCAM heatmap, similar images
- Linguistic information: Text interpretation, highlighting of key keywords
- Connection structure: Spatially connect visual elements and text descriptions
This structure allows labelers to refer to the AI’s interpretation while viewing the images, enabling more accurate and faster decisions.
While improving the UI/UX of the labeling system, we were able to achieve all three goals we initially set. First, we selected efficient labeling targets through active learning, then improved the work environment by applying cognitive psychology principles, and finally, AI assisted human cognitive abilities to improve labeling quality.
What is particularly noteworthy is that a structure has been created in which AI and humans collaborate by leveraging their respective strengths. AI uses GradCAM to indicate areas of interest, interprets image content as text, and provides supporting information to aid decision-making. People make final decisions based on this AI-provided supplementary information, and the results are then fed back into the AI learning process, creating a virtuous cycle in which the entire system continuously improves.
We have established a foundation that enables labelers to make faster and more accurate judgments through an intuitive interface and AI-assisted information. Especially highly complex exception cases, the visual evidence and text interpretation provided by AI significantly contributed to improving the quality of labelers’ judgments, highlighting the significance of this improvement.
Footnotes
1) Approximate K-Nearest Neighbors (AKNN) is a method that improves the efficiency of the K-Nearest Neighbors (KNN) algorithm. Traditional KNN calculates the distance between a given data point (query) and all other points in the dataset to find the K nearest neighbors. As the dataset size grows or dimensionality increases, the computation grows exponentially, consuming enormous time and resources. AKNN addresses this issue by sacrificing a small degree of accuracy to dramatically improve search speed. Instead of finding the absolutely closest K neighbors, it efficiently finds K neighbors that are sufficiently close.
2) CNN (Convolutional Neural Network) is a deep learning neural network specialized for image recognition and processing. It automatically extracts and learns features (such as lines and contours) from images, and is used for tasks like object classification or detection. CNNs preserve and process spatial information effectively through convolutional and pooling layers.
3) EfficientNet is a CNN model that achieves high accuracy and efficiency with fewer parameters. It uses a “Compound Scaling” method, which balances the expansion of depth, width, and resolution, resulting in far more efficient performance compared to previous models.
4) Compound Scaling is the network scaling method proposed by EfficientNet. Traditionally, model performance was improved by increasing one of depth, width, or input image resolution independently. However, the EfficientNet team found that scaling these three dimensions simultaneously and proportionally is much more efficient. Compound Scaling uses a single variable, the “Compound Coefficient” (ϕ), to increase depth, width, and resolution together in a fixed ratio. This maximizes performance while maintaining computational efficiency. For example, with larger images, a deeper network observes a wider area while more channels capture finer details.
5) In traditional Transformers, self-attention computes relationships among all pixels in an image, so the computational complexity grows exponentially as image size increases. Window-based self-attention reduces this complexity by dividing the image into small “windows” and performing self-attention only within each window.
6) The Swin Transformer is a Transformer model specialized for image processing. To address the high computational complexity of the Vision Transformer (ViT), it introduces a hierarchical architecture and the concept of shifted windows. This enables efficient learning of multi-scale image information and achieves strong performance in complex vision tasks such as object detection and segmentation. The Swin Transformer uses Window-based Self-Attention as its core component. The shifted window technique allows information exchange between neighboring windows, overcoming the limitation of attention being restricted to a single window, and enabling effective capture of global context. In other words, the Swin Transformer leverages the efficiency of window-based self-attention while enabling broader information exchange through shifted windows, maximizing image processing performance.
7) Active Learning is a training strategy aimed at maximizing model performance with a small amount of labeled data. In general supervised learning, humans must label all data, which is prohibitively time- and cost-intensive for large datasets. Active Learning addresses this problem by allowing the model to select data that is most informative (i.e., most beneficial for learning) and request labeling from humans. Through this iterative process, Active Learning reduces labeling costs while rapidly improving model accuracy.
8) Entropy Sampling is a strategy that selects data with the highest entropy (uncertainty, disorder) in the model’s prediction results and requests labeling for it. High entropy means the model is uncertain, assigning similar probabilities to multiple classes. Training on such data effectively reduces the model’s uncertainty.
9) Allan Paivio’s Dual-Coding Theory proposes that the human brain processes and stores information in two forms: verbal (text, speech) and visual (images). When both channels are used together, memory retention improves significantly, both in strength and duration.