TOC
Generating TOC...
4.2. Guardian of Text Content: The Story of Monitoring Assistant LLM
This chapter discusses how AI, particularly LLMs, has revolutionized text-based harmful content monitoring. This system, which was internally named “Hamong,” was named after “ham,” the opposite of spam.
“You think people will see this?” — A hidden trap in a long text
“You mean people actually read all this?” — The text content posted by countless users, including posts, comments, and reviews, is as diverse and complex as it is voluminous.
In particular, for long posts consisting of dozens or hundreds of lines, it was extremely tedious for administrators to carefully review all of the content and determine whether it was harmful. Although the beginning and end of the text appear normal, illegal advertisements or fraudulent information are often cleverly hidden in the middle, making them easy to miss with the naked eye.
For this reason, a model that explains the reasons for spam was needed, and LLM had excellent contextual understanding capabilities.
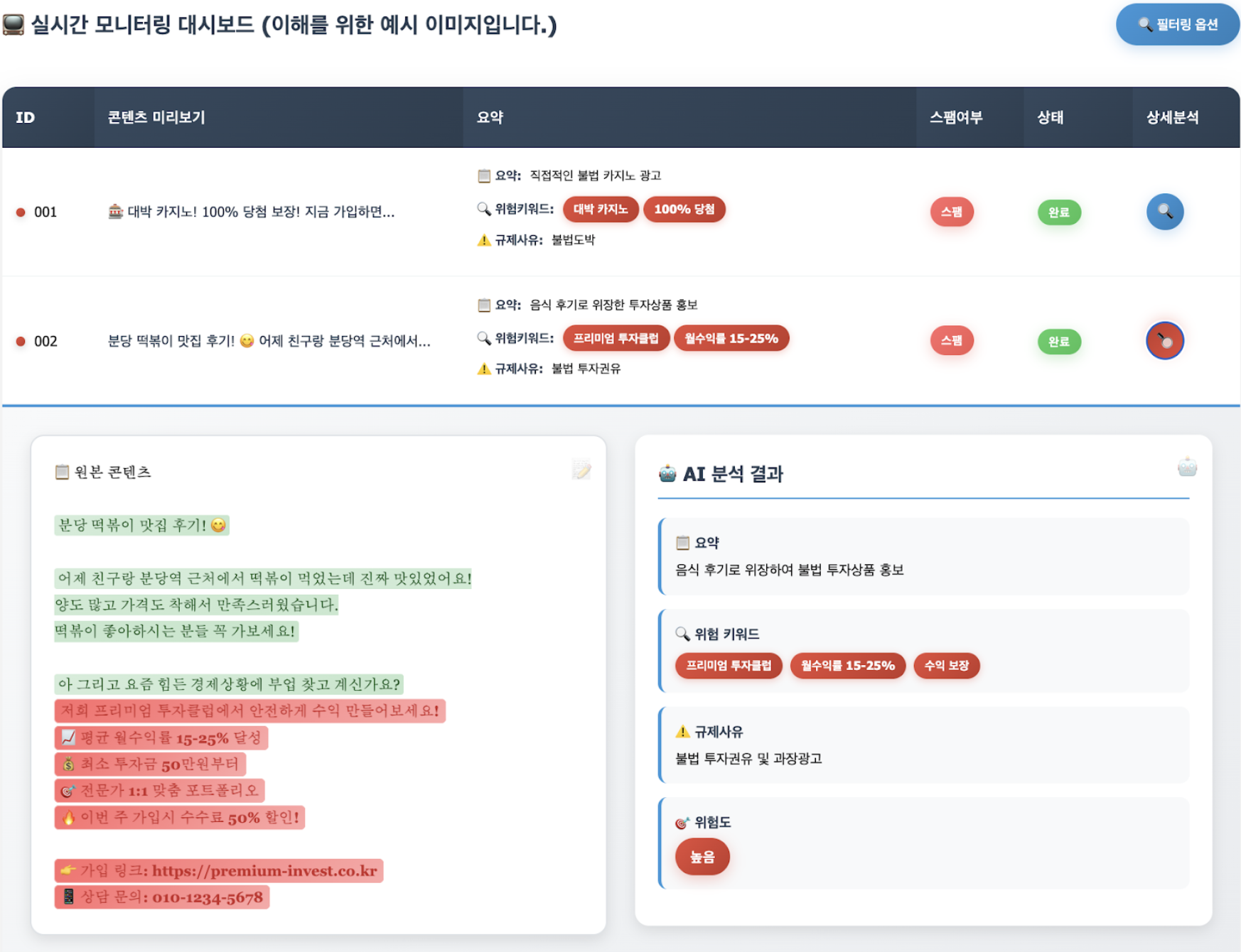
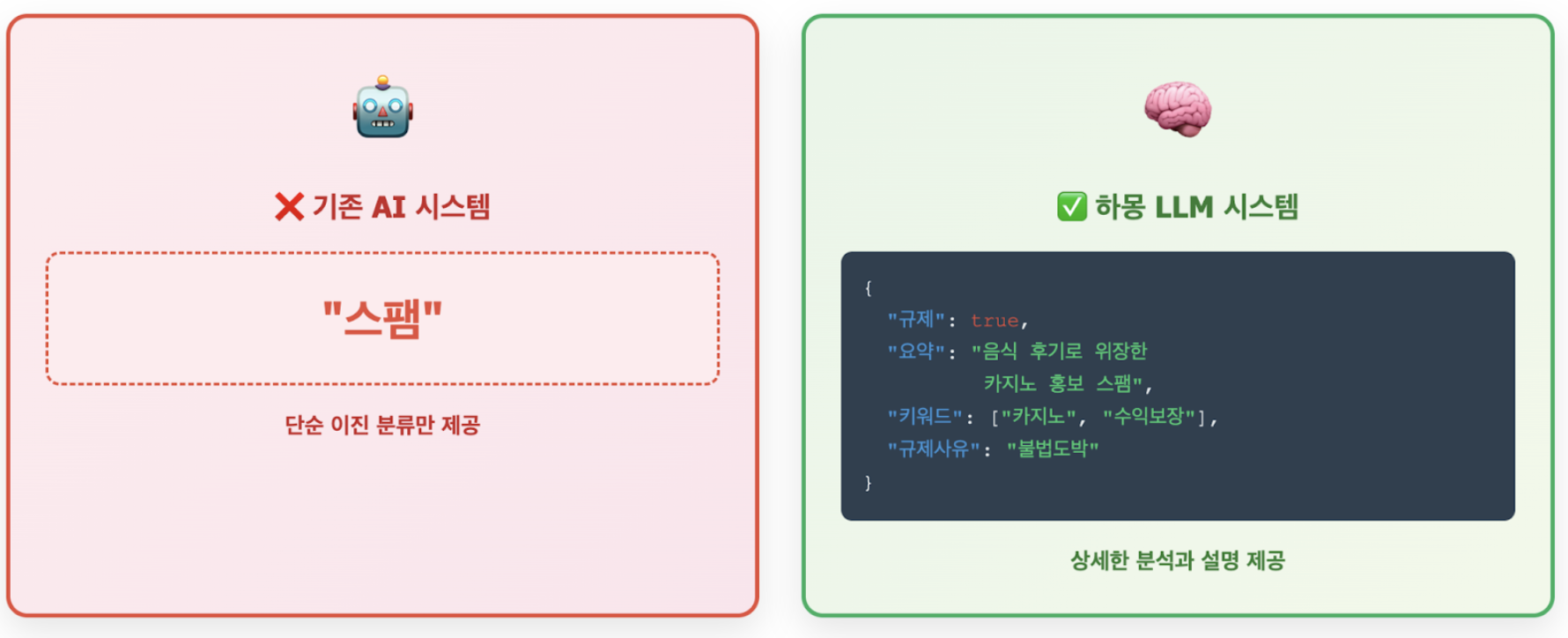
First, simple binary classification to determine whether or not a message is spam did not provide sufficient information to operators. For example “Today, the tteokbokki is delicious. …omitted… (Come to our casino: Link) ..omitted.. Bingdang Tteokbokki Restaurant #Food #RecommendationIf such a post is simply classified as “spam,” the administrator may mistakenly think, “This is a food review, so why was it classified as spam?”
At this point, if the LLM is asked to add an explanation, it can immediately identify that it is spam intended to promote illegal gambling, disguised as a food review but with a casino link inserted in the middle.
In addition, LLM can accurately understand complex contexts even with limited data. Compared to existing models that require a large amount of data to learn specific patterns, LLM can understand new patterns and complex contexts with less data, enabling it to respond well to various tones and modified harmful words.
Kakao’s decision to adopt LLM for the first time
Although this monitoring assistant LLM did not provide direct services to users, it was one of the first cases in which LLM was applied to Kakao’s internal service environment (production environment). There are countless ways to utilize LLM, but replacing existing systems that work well with LLM can be burdensome in many ways.
This system was not intended to replace operators, but rather to work alongside them as colleagues. It was an assistant role that helped operators by adding a new “description” feature that did not exist before. Since it was not required to meet clear performance standards or achieve perfection, as would be the case with a chatbot replacing human customer service representatives, we were able to safely experiment with LLM and verify its effectiveness.
Creating AI with operators
Initially, we focused on simply using AI to automatically and quickly block harmful content. However, after listening to feedback from operators, we realized that there was a lack of explanation as to “why it was classified this way,” which caused confusion when false positives occurred.
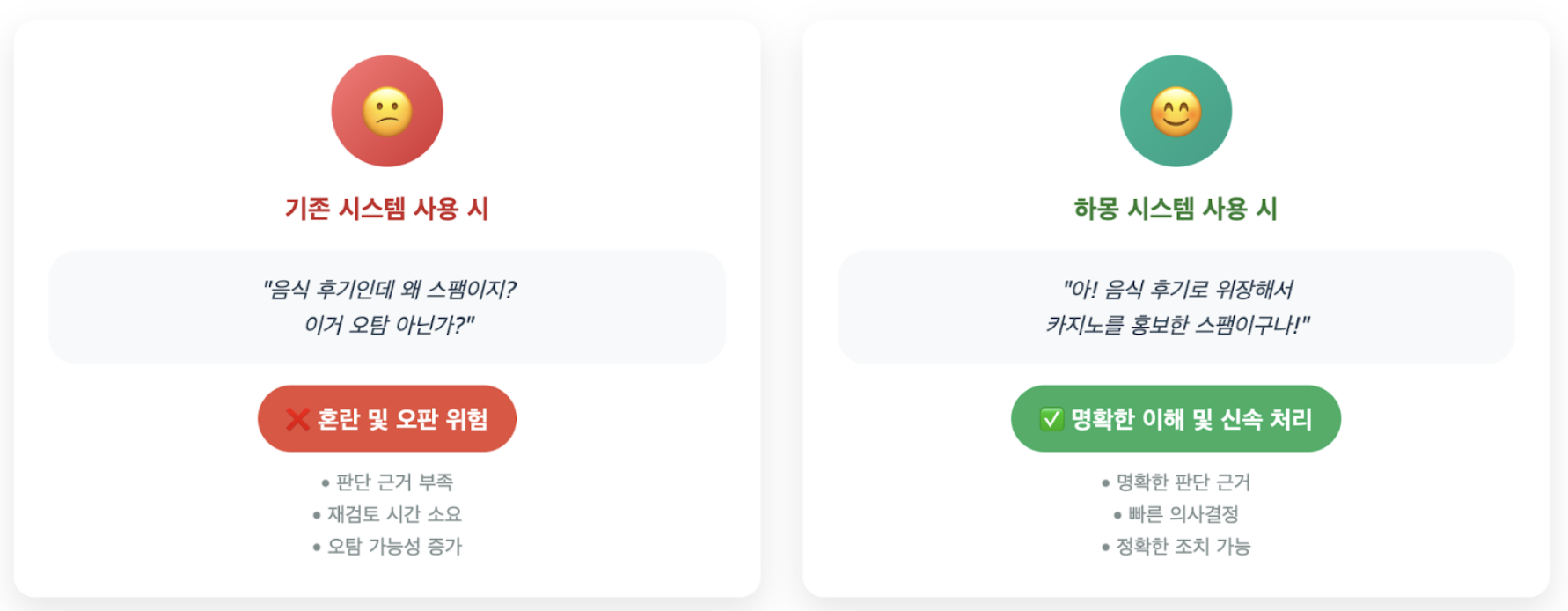
Operators’ work continues, and we have realized the urgent need for tools that help them make better decisions. The key was to go beyond simply “determining” whether something was harmful, and instead explain “why” it was harmful, thereby helping operators handle their work more quickly and accurately.
This approach of “building AI in collaboration with operators” became a core guideline for all subsequent stages of system development. While technical performance is important, it became clear that accurately identifying and reflecting the needs of actual users (operators) is the key to building a successful AI system.
“You are a spam classification AI bot” — Creating a model that responds as desired
The spam classification AI chatbot development team created content moderation AI using a base model with 8 billion parameters. This model was chosen for its performance, speed, and cost efficiency. In particular, stable inference was possible without quantization in an A100 80GB GPU environment, providing high development flexibility.
Data set design and two-track strategy
The model was trained to understand various instructions and generate appropriate responses through instruction tuning-based learning. The key was to enable a single model to provide different types of responses depending on the purpose of use.
- Real-time classification: We have ensured fast processing and cost efficiency by simply responding with 0 or 1 to indicate whether a message is spam.
- Monitoring Assistant: We have improved the efficiency of operator monitoring by providing detailed explanations in JSON format, including spam status, summaries, keywords, and reasons for regulation.
Learning and Optimization
For effective learning, we went beyond simply labeling whether something was spam or not, and built specific explanatory data on why it was spam. To this end, we refined our labeling guidelines, introduced a cross-review system by experts, and applied a model-based verification method to improve data quality.
In addition, we used an expression diversification strategy to enable the model to respond flexibly to various expressions, and compared the “baseline,” “pattern augmentation,” and “multiclass” methods to solve the data imbalance problem commonly found in real-world environments. As a result, we confirmed that augmenting ambiguous data located at the classification boundary was the most effective method.
Improved operational stability and efficiency
To optimize the inference cost of the model, we applied token length optimization techniques such as text compression, key sentence extraction, single token output, and addition of dedicated tokens. To ensure the stability of JSON output, we maintained data consistency during the learning stage, strengthened exception handling during the inference stage, and implemented schema validation and parsing error recovery in the post-processing pipeline.
We developed an automatic marking function for suspicious words to help operators quickly identify new words and slang.
“Why is this spam?” — The explanation the operator wanted from AI
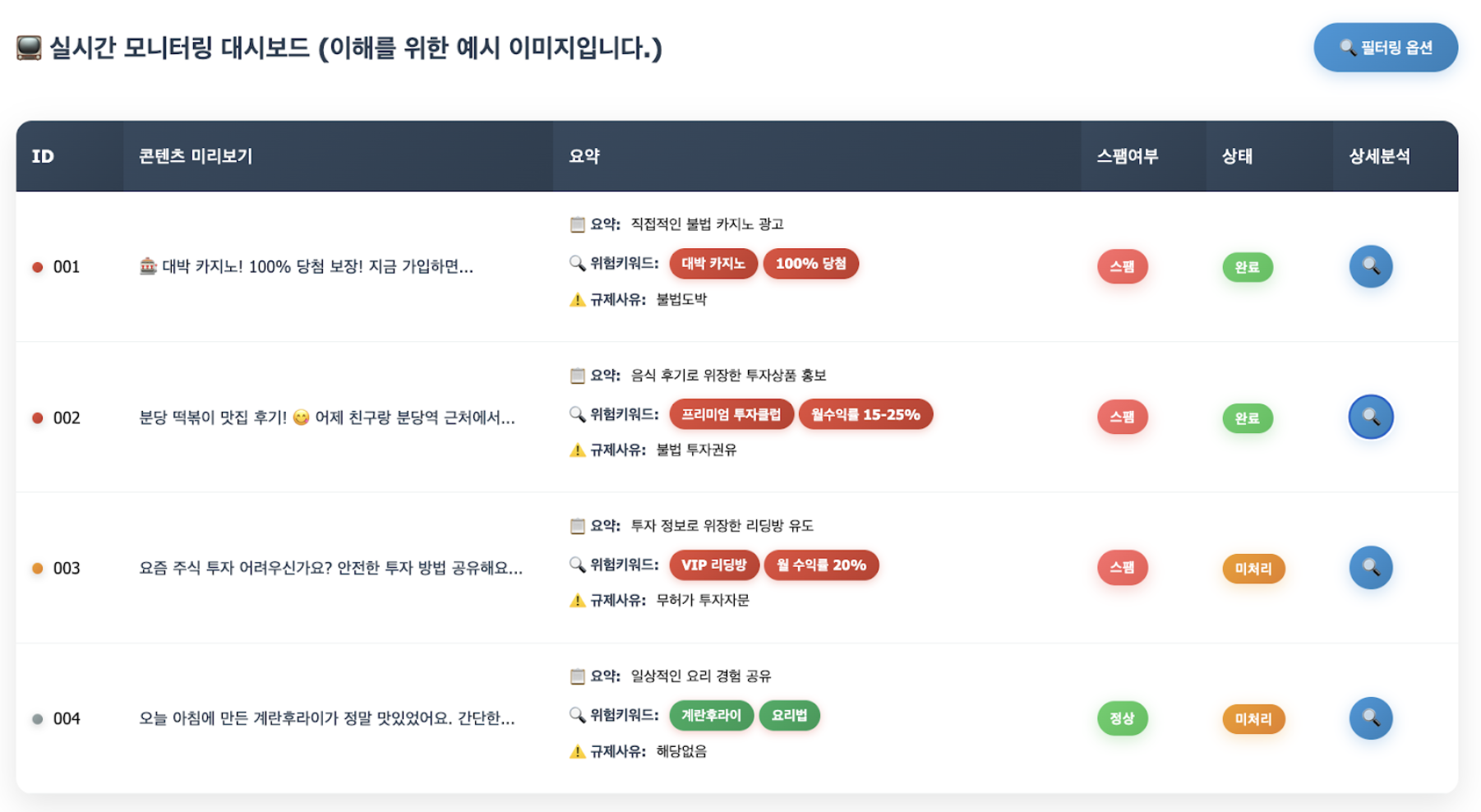
No matter how advanced an AI model is, it cannot be 100% perfect. In particular, among the content that AI deemed “suspicious” and forwarded to operators as a priority, there were some false positives that were not actually harmful. In this case, operators may experience confusion because it is difficult to understand the context behind the AI’s decision that the content is harmful, or they may waste time on unnecessary reviews.
To alleviate these challenges faced by operators and reduce fatigue caused by false positives, the monitoring assistant LLM goes beyond simple classification and provides the core functionality of explaining the basis for determining harmfulness in natural language.
Content example:
Hello! Are you looking for ways to make money with cryptocurrency? 😮 Experience amazing returns with our “Super Coin Investment Club.” ✨ Safe, fast, and reliable! 📈 (Actual investment return photos to be attached soon). Join now! ▶️ [Exclusive private reading room link included: bit.ly/illegalinvestmentroom] We will provide you with information and strategies that you can only get here. Please send inquiries to Telegram @supercoinmaster. #coin investment #financial management #bitcoin #big profits #financial management know-how
LLM analysis results (JSON format example):
{
"규제": true,
"요약": "투자 유도 및 외부 리딩방 가입 권유",
"키워드": ["코인", "수익", "투자클럽", "단독 비공개 리딩방", "불법투자방"],
"규제사유": "불법 사행성 카지노 홍보"
}
This LLM-based system extracts key information in the form of “regulations,” “summaries,” “keywords,” and “regulatory reasons,” providing it in a format that is easy for operators to view and understand.
If AI is used for content moderation…
The most notable achievement is the improvement in operator monitoring efficiency. Previously, when reviewing reported content, operators needed to spend a significant amount of time and concentration to understand the full context of the content and determine whether it was harmful. However, through the structured analysis results provided by LLM, we were able to confirm that the time spent on monitoring was reduced by more than 20% compared to the previous system.
In addition, we were able to achieve significant performance improvements compared to the existing system by applying appropriate data imbalance resolution strategies. In particular, we saw significant improvements in spam detection rates and overall classification accuracy.
In the experimental group where data with patterns similar to spam was added, significant performance improvements were observed in all evaluation metrics, and in particular, the substantial improvement in recall suggests that the model is now better able to detect various spam variants.
More important is its effectiveness in actual operating environments. The improved model has greatly improved the efficiency of the operator’s monitoring work and contributed to reducing unnecessary review time due to false positives.
Through this development, we have achieved two major results: improved operational efficiency and improved spam detection rates and overall classification accuracy. In particular, the significant improvement in recall means that the model is now better at detecting various spam variants.