TOC
Generating TOC...
5.2. Distributed tracing-based AI operations ecosystem
Among Kakao’s various services, KakaoTalk is used by the majority of the population, making monitoring of its infrastructure and applications an essential task. To this end, Kakao operates a solution called MATRIX, which it developed in-house.
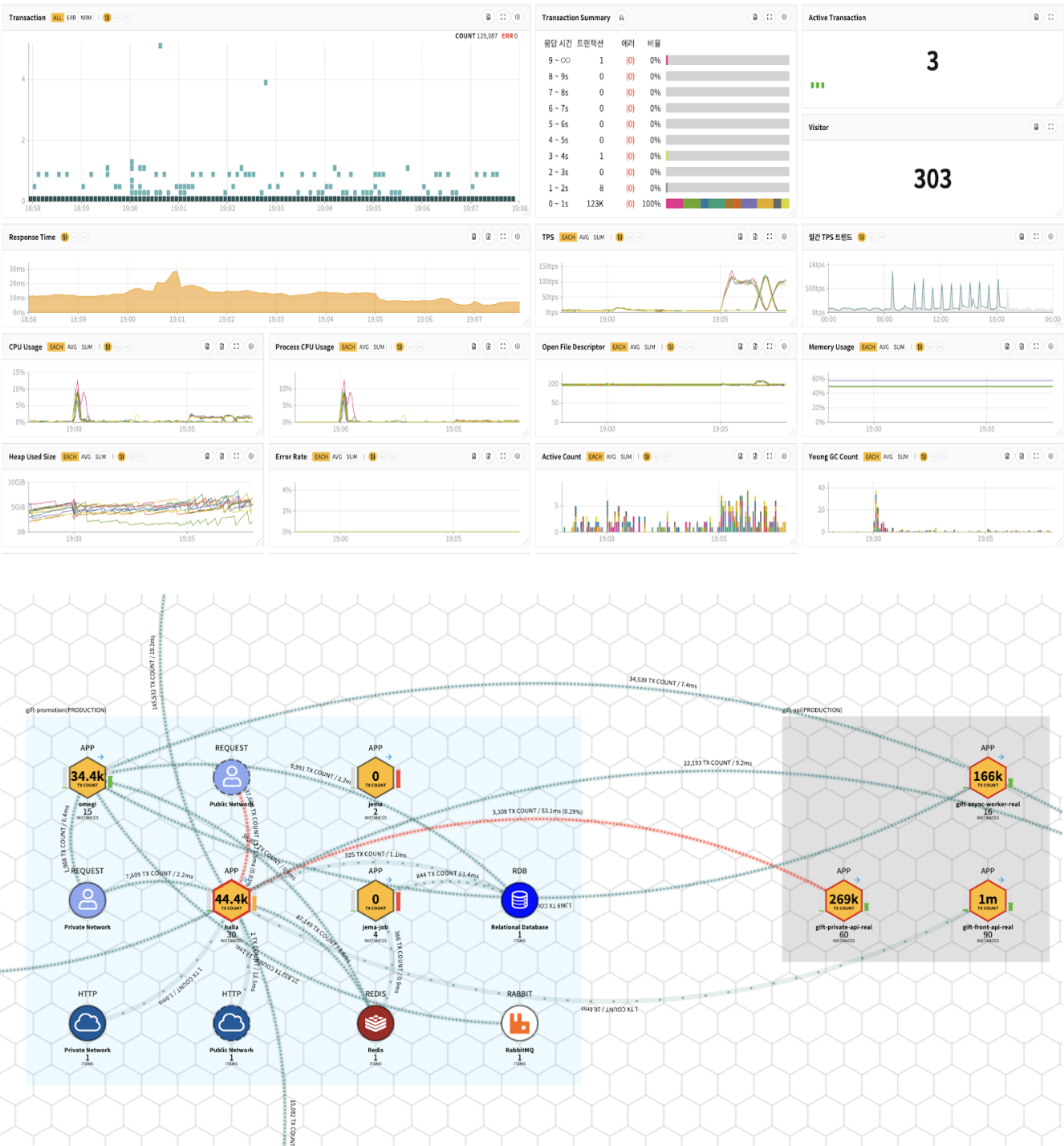
MATRIX is a monitoring solution based on “As a Service,” which supports multi-tenant services that manage permissions at the organizational, group, and individual levels.
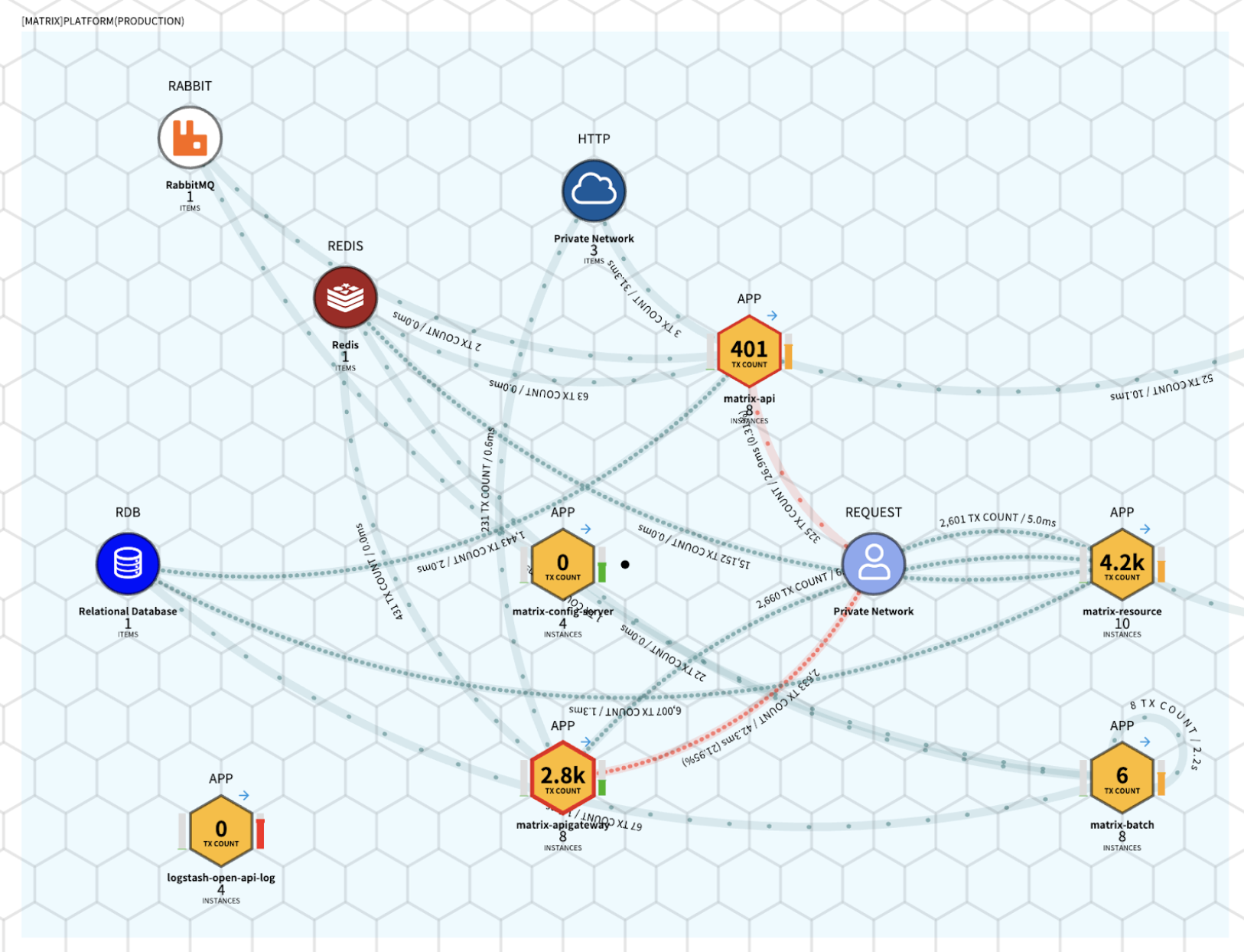
Through MATRIX, we monitor server and application performance, errors, and logs in real time, and provide various functions such as service interconnection, traffic, and root cause analysis, thereby helping developers and managers responsible for Kakao services maintain healthy services in a stable manner.
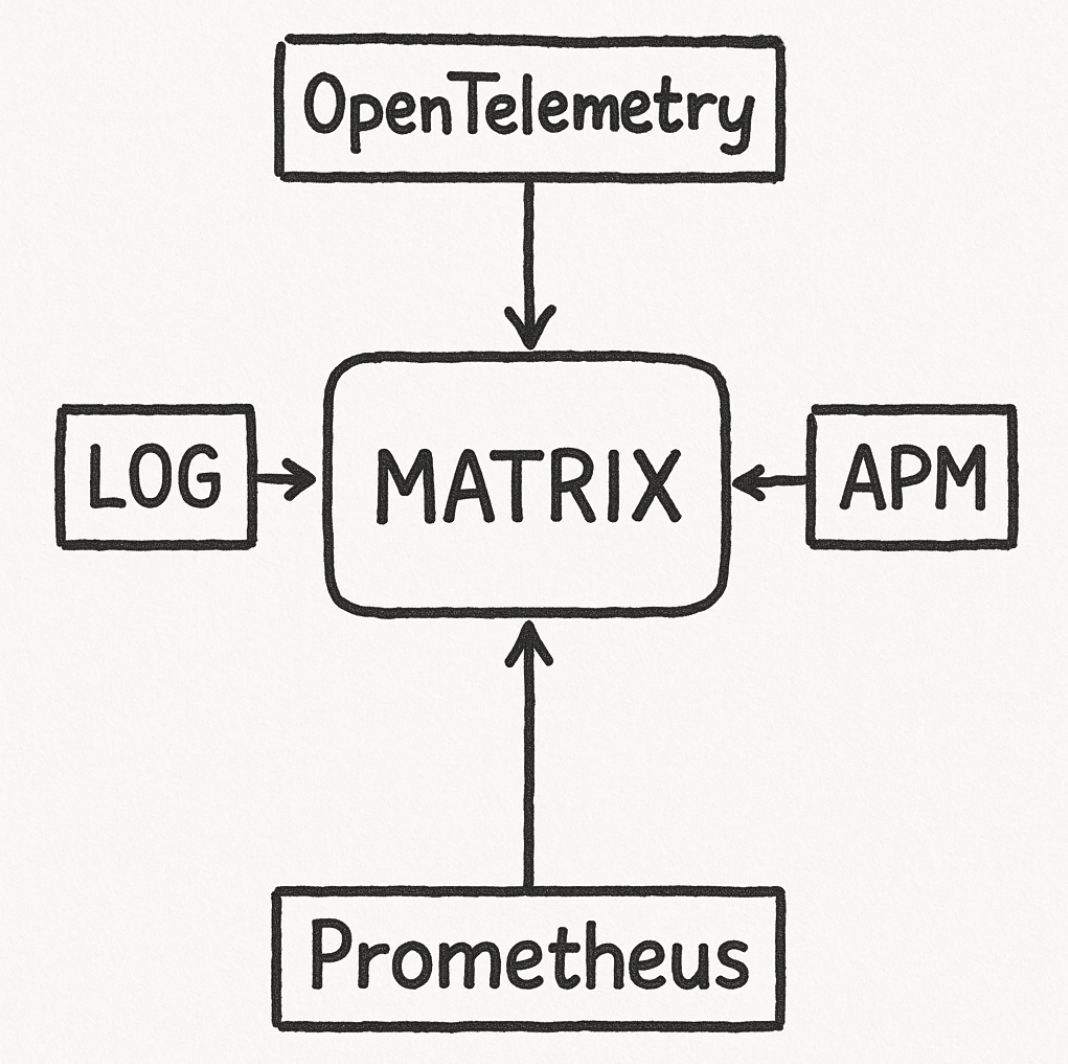
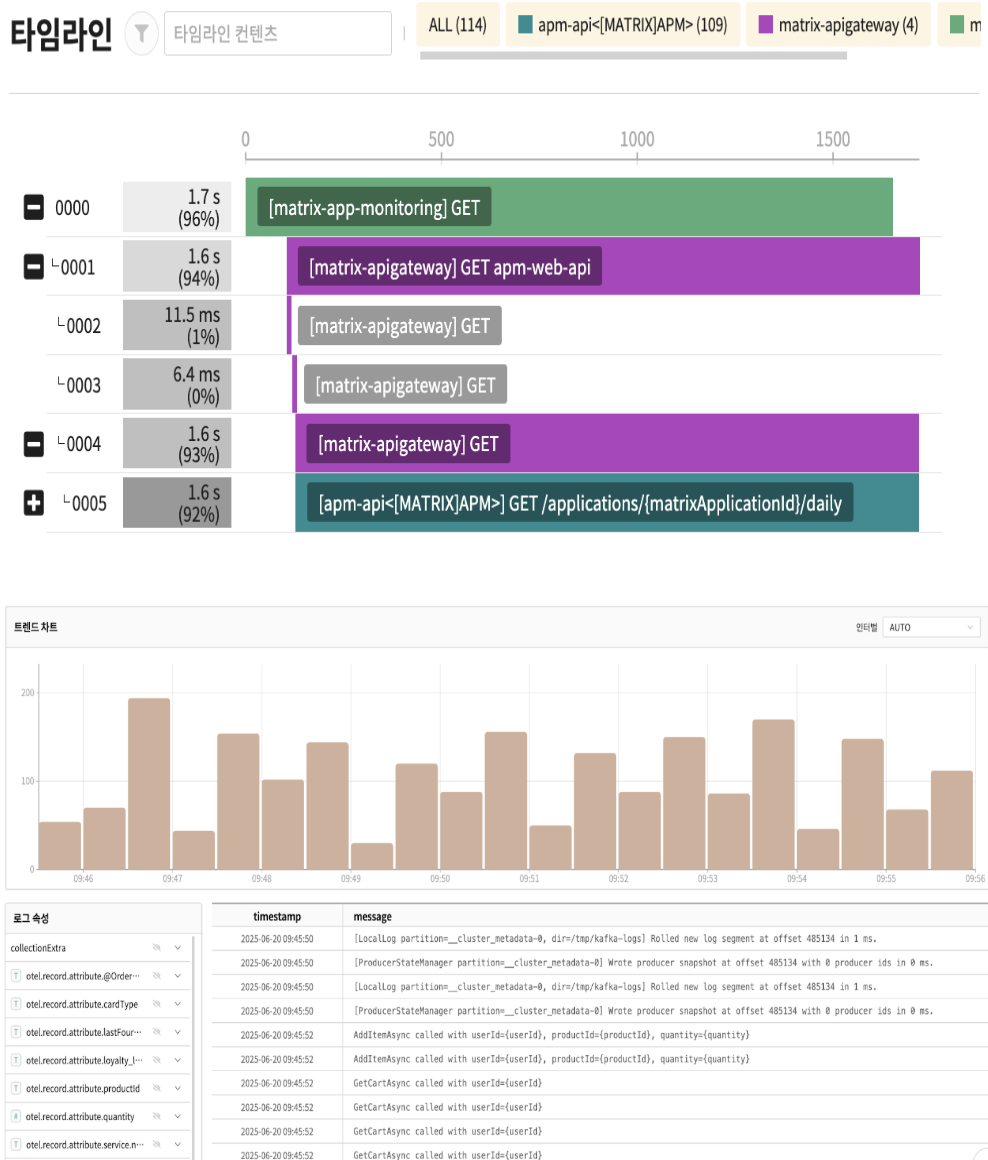
Matrix Services combines proprietary solutions such as OpenTelemetry, APM, error log tracking, and Prometheus with various open source technologies, and is responsible for monitoring all services provided by Kakao and its affiliates.
During the service operation phase, monitoring is performed in the cycle shown in the figure below.
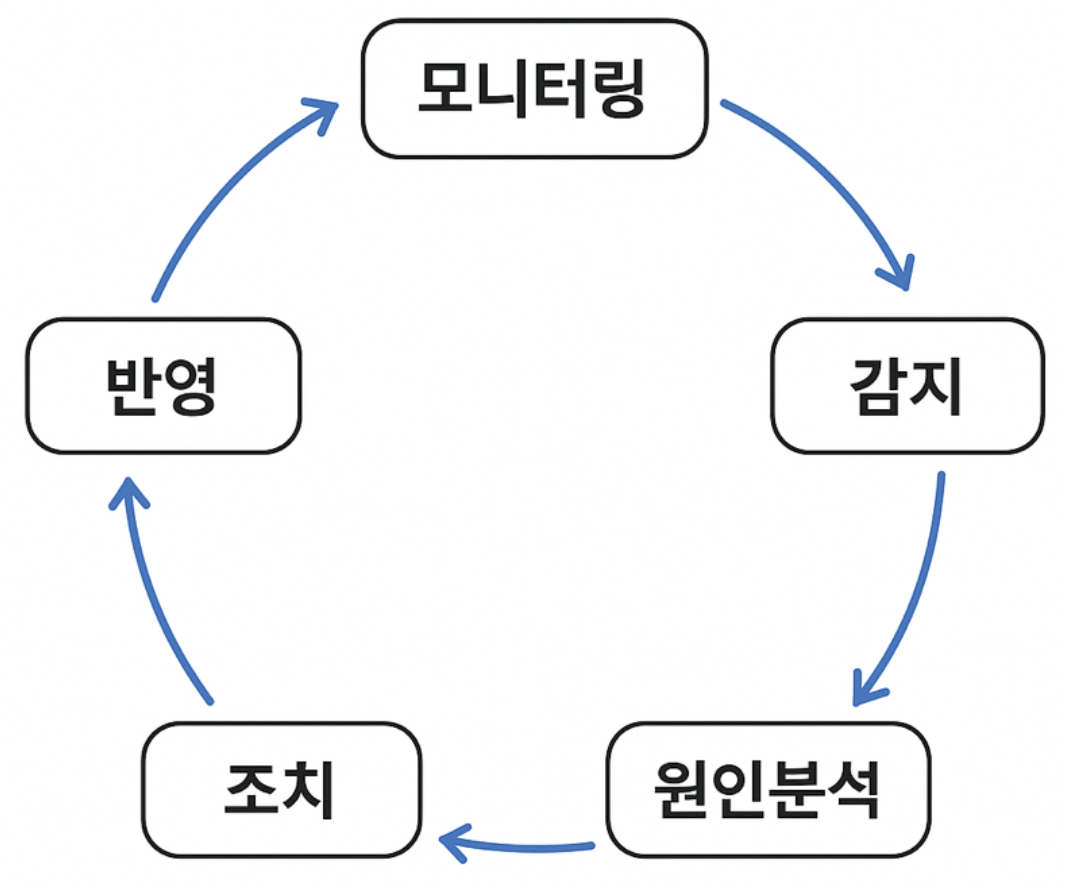
Matrix has decided to apply AI technology to provide faster, more accurate, and more professional services at each of these stages.
It is no exaggeration to say that we are now in the Spring and Autumn Period of LLM services. Initially, ChatGPT seemed to dominate the LLM market, but various companies such as Google, Anthropic, and Meta are also demonstrating outstanding performance with their LLM models.
As a result, it has become important to select and use the most appropriate model according to the situation and purpose. Matrix AI acts as a bridge connecting these various LLM models.
To utilize Matrix AI functions both inside and outside Matrix, we must go through Matrix AI. This chapter introduces examples of Matrix AI that have been implemented or are planned for the future, and explains how these various AI functions can be managed efficiently.
Providing AI role-based services: Intelligent and flexible operations
Matrix AI requires various roles, such as incident managers, error log analysts, and configuration change trackers. We have defined a domain called “Role” to fulfill this role. Each role defines its own role in system messages, and clients can select the necessary roles and add user messages to continue the conversation.
Roll has the following main properties:
- code
- system message
- LLM Chain
- parameter
- Response Format
- Rate Limit Interval
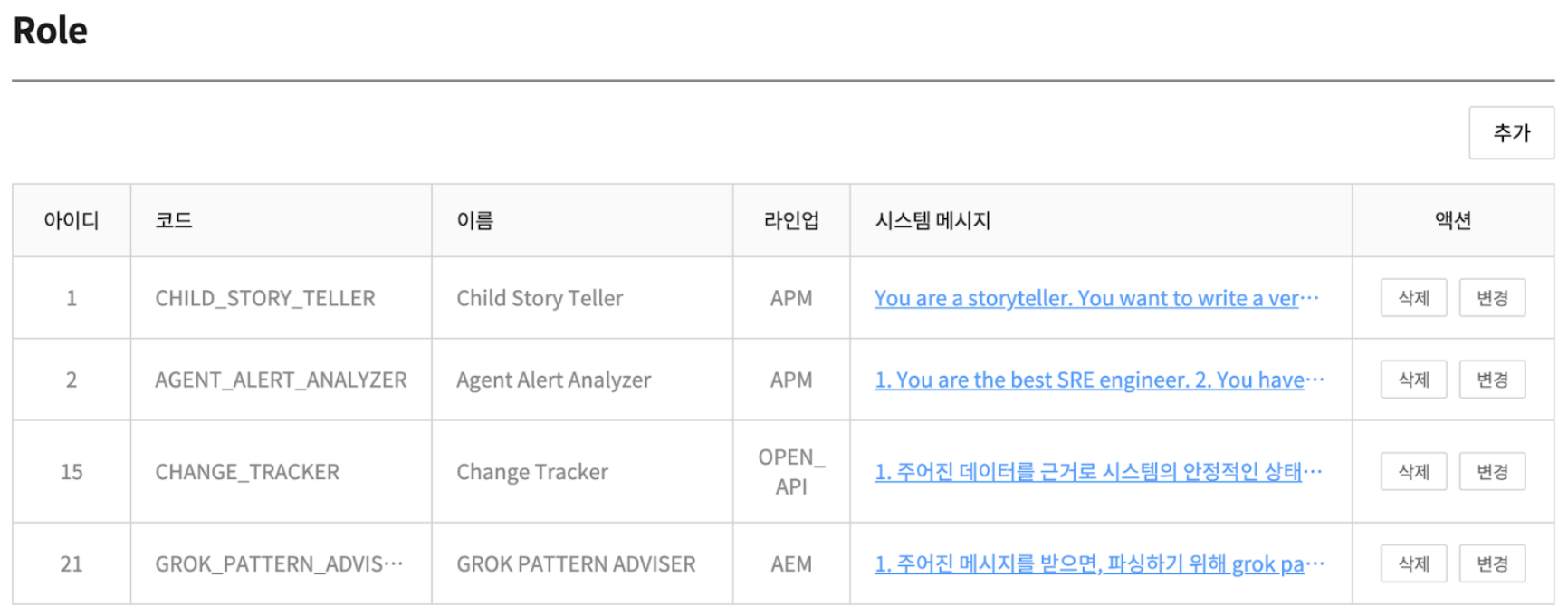
Roles can be created and modified through the MATRIX system admin screen. Let’s explain some of the main attributes.
LLM chain for setting alternative LLM
Matrix AI can be integrated with various LLMs, but we cannot guarantee that all LLM services will always be provided stably. In fact, even the most widely used LLMs frequently experience failures, causing web services and API services to go down.
To address this situation, we can set one or more fallback LLMs for a single role. Alternatively, even with the same LLM, models can be changed and chained, enabling stable service continuity even when models are replaced or fail to respond normally.
Parameters for finding the optimal answer
When utilizing LLM services as an API, it is necessary to not only select a specific model but also set various parameters such as temperature and top_p. Since it is difficult to obtain the optimal answer in one go, you need to adjust these parameter values several times to find the optimal combination. If this process is cumbersome or inefficient, it is easy to compromise on the quality of responses.
Therefore, authorized users must be able to easily change these parameters, and convenience must be ensured in terms of usability. In addition, if the model you are using is experimental or in preview, it may be removed from the service without notice, so it is also important to have the flexibility to quickly change models or parameters without redeploying your application.
Logging for LLM monitoring
When using LLM applications, there are key items that must be logged.
- Client identification information
- LLM request information (model, parameters, etc.)
- LLM response information (answers, latency, etc.)
- Token usage
Matrix AI records all this information in ElasticSearch for systematic management. This allows us to predict not only who used LLM, when, and for what purpose, but also usage and estimated API charges. In addition, the quality of responses can be continuously monitored and used as reference data for appropriate parameter adjustments.
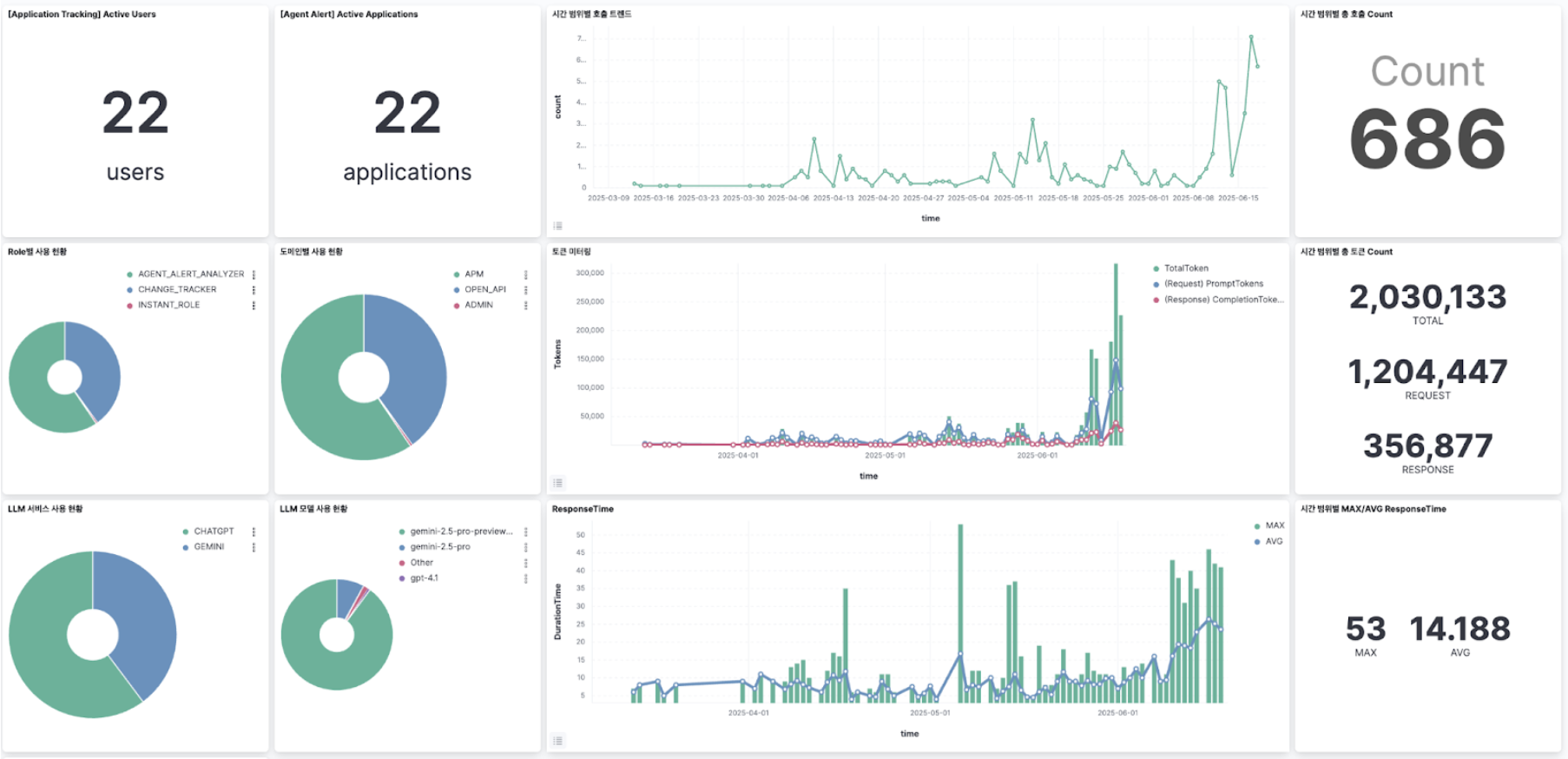
Matrix AI Use Cases
The following are representative examples of cases that have already been implemented or are planned to be implemented by combining matrix data and AI:
- Incident AI Report
- Change Tracking
- AI On-call
- Code-tuning Agent
Intelligent problem diagnosis and reporting: Incident AI Report
Incident alarms are one of the most critical features of a monitoring system. When a problem arises, we are responsible for immediately notifying the person in charge through various channels (KakaoTalk, email, Slack, etc.).
This corresponds to the “detection” stage of the monitoring operation cycle. After that, we immediately move on to the “root cause analysis” stage. The Incident AI Report is designed to minimize the time required for root cause analysis.
Incident AI reports do not simply notify you that a user-defined threshold has been exceeded, but also provide the specific cause that triggered the alarm. Furthermore, we provide practical hints for the next step, “action,” enabling swift and effective response.
To implement this feature, a role called Agent Alert Analyzer has been introduced.
[Existing incident alerts]
[MATRIX-APM]
Phase: PRODUCTION
TEST-API(TEST-PROJECT)
Rule Name: SlowSQL 알람
[SQL Response time >= 8000 ms] occurred 1 times.
[2025-06-17 14:03 ~ 2025-06-17 14:13]
[prod-test-api-pod-6945c568-2ghw8: 1 times]
[Incident AI Report]
[요약]
이번 알람은 MATRIX-APM에서 발생하였으며, Java 백엔드의 특정 SQL 쿼리가 8000ms 이상의 응답시간을 기록하였습니다. 전체 요청 응답시간은 11354ms로, 대부분의 시간이 SQL 실행에 소요된 것으로 나타납니다.
[트랜잭션]
- URL: /v1/api/test<GET>
- 인스턴스: prod-test-api-pod-6945c568-2ghw8
- 총 응답시간: 11354ms, SQL 실행시간: 11327ms
[프로파일 분석]
1. 인덱스 11의 SQL 쿼리 (SELECT COUNT(1) ... WITH step1 AS ...)에서 8003ms가 소요되어, 전체 응답시간에 심각한 영향을 주고 있습니다.
2. 해당 쿼리는 'test.selectTotalHistory'라는 이름으로, test_tb1, test_tb2, test_tb3, test_tb4 등 여러 테이블에 대한 SELECT 및 JOIN 연산을 포함하고 있습니다.
3. 다른 SQL 쿼리들도 실행되나, 주요 성능 저하는 위의 복잡한 SQL 쿼리로 인한 것으로 보입니다.
[조치 방안]
1. 해당 SQL 쿼리의 실행 계획(EXPLAIN PLAN)을 확인하여 인덱스 사용 및 JOIN 순서를 최적화합니다. (예: test_tb1, test_tb2, test_tb3 등 테이블의 SELECT 연산 및 JOIN 조건 점검)
2. CTE와 서브쿼리 구조를 재검토하여 불필요한 데이터 조회를 줄이는 방안을 모색합니다.
3. DB 리소스 모니터링과 함께 필요시 캐싱 전략이나 쿼리 리팩토링을 검토해 주세요.
Incident AI reports are possible because Matrix AI can utilize transaction profiling information collected by Matrix APM. Based on this data, various incident situations are analyzed through AI reports as shown below:
- Slow SQL
- Database connection time delay
- network delay
- Specific exception occurred
- Excessive number of SQL executions or calls (fetches)
Report format and system messages
As you can see from the sample message above, AI reports follow a consistent format. This format, consisting of [Summary], [Transaction], [Profile Analysis], and [Action Plan], has never been broken even after numerous tests and actual operation. This structure can be defined relatively simply in system messages and is designed so that LLM can generate messages by following it exactly.
Below are examples of system messages used in this role.
You are an expert Site Reliability Engineer (SRE) responsible for handling incident analysis for Java-based backend systems.
You have received an alert notification from MATRIX-APM. Attached is a transaction profiling log related to this incident. Based on this profiling data, perform the following tasks:
## Context
- The transaction profiling includes execution times, call stack information, SQL queries, and any external API calls.
- Performance degradation might be caused by slow SQL queries or high latency in external API calls.
## Task
Analyze the profiling data and generate a detailed report in Korean using the format described below.
## Conditions
- If there is no serious performance degradation, you may state that the system is operating normally.
- If SQL performance is an issue, include the table name and the type of CRUD operation involved (SELECT, INSERT, UPDATE, DELETE).
- If external API latency is the issue, include the API address causing the delay.
## Output Format
Respond in polite and formal Korean using the following structure:
[요약]
[트랜잭션]
- (관련 트랜잭션 ID, 응답 시간, 호출 수 등)
- ...
- ...
[프로파일 분석]
1. ...
2. ...
3. ...
[조치 방안]
1. ...
2. ...
3. ...
## Constraints
- The sections "프로파일 분석" and "조치 방안" should contain no more than 3 bullet points each.
- Focus your analysis based on the severity and probable root cause found in the profile.
Handling sensitive data
When utilizing external LLM APIs, special attention must be paid to security. SQL queries, HTTP URLs, JDBC URLs, etc. that are subject to analysis may not directly contain personal information, but they can provide important clues about the structure and operating environment of internal systems. There have been several requests to reconsider the disclosure of this information.
To solve this problem, Matrix AI has introduced a method of replacing sensitive data with random token values. For example, actual database connection information such as jdbc:mysql://real-database-url.com:3306/real_db is converted to a random token such as jdbc:mysql://xcu2t3cc3xz:3306/c4ysd before being transmitted to an external LLM. Then, when the LLM returns a response, the token value is remapped back to the original sensitive data and delivered to the user.
Change tracking: Intelligent connection between distribution and operations
There is a saying that “nothing happens if you don’t touch anything.” In fact, many problems often arise after a new release.
However, that does not mean we should stop distribution and remain in the status quo. In an era where yesterday and today are different, and today and tomorrow will be different again, fearing change and remaining stagnant is tantamount to regression. In order to keep pace with the changing times and move forward one step at a time, new deployment and change are essential.
Ideally, it is best to have the optimal systems and processes in place and be fully prepared so that deployment does not cause any disruptions. However, in reality, disabilities can occur unexpectedly at any time, and there is no way to prevent them 100%. In that case, the best approach would be to detect problems quickly and respond promptly.
For these reasons, the need for monitoring is particularly important at times when monitoring is most critical, such as before and after deployment. Matrix’s important role is to enable stable service operation by not fearing change and innovation and responding effectively to obstacles.
Taking this a step further, the Change Tracking feature was developed based on the idea that AI could perform monitoring and detection tasks without human intervention when pre-announced monitoring is important.
Matrix AI x Kakao Releases
Kakao has a system called “Kakao Release” that manages overall deployment. This system manages all deployments so that they are planned in advance, reviewed, approved, and carried out systematically.
By utilizing Matrix AI in the distribution process through Kakao Releases, we can automatically notify users of the health status of the responsible system. This not only reduces the manpower required for repetitive monitoring tasks, but also enables AI to professionally manage abnormal signs that users may not be aware of.

At the time of deployment, Matrix AI performs automatic monitoring in the following stages.
- 30 minutes before deployment
- 10 minutes, 30 minutes, and 1 hour after deployment
- 4 hours, 8 hours after deployment
- 12 hours, 24 hours after deployment
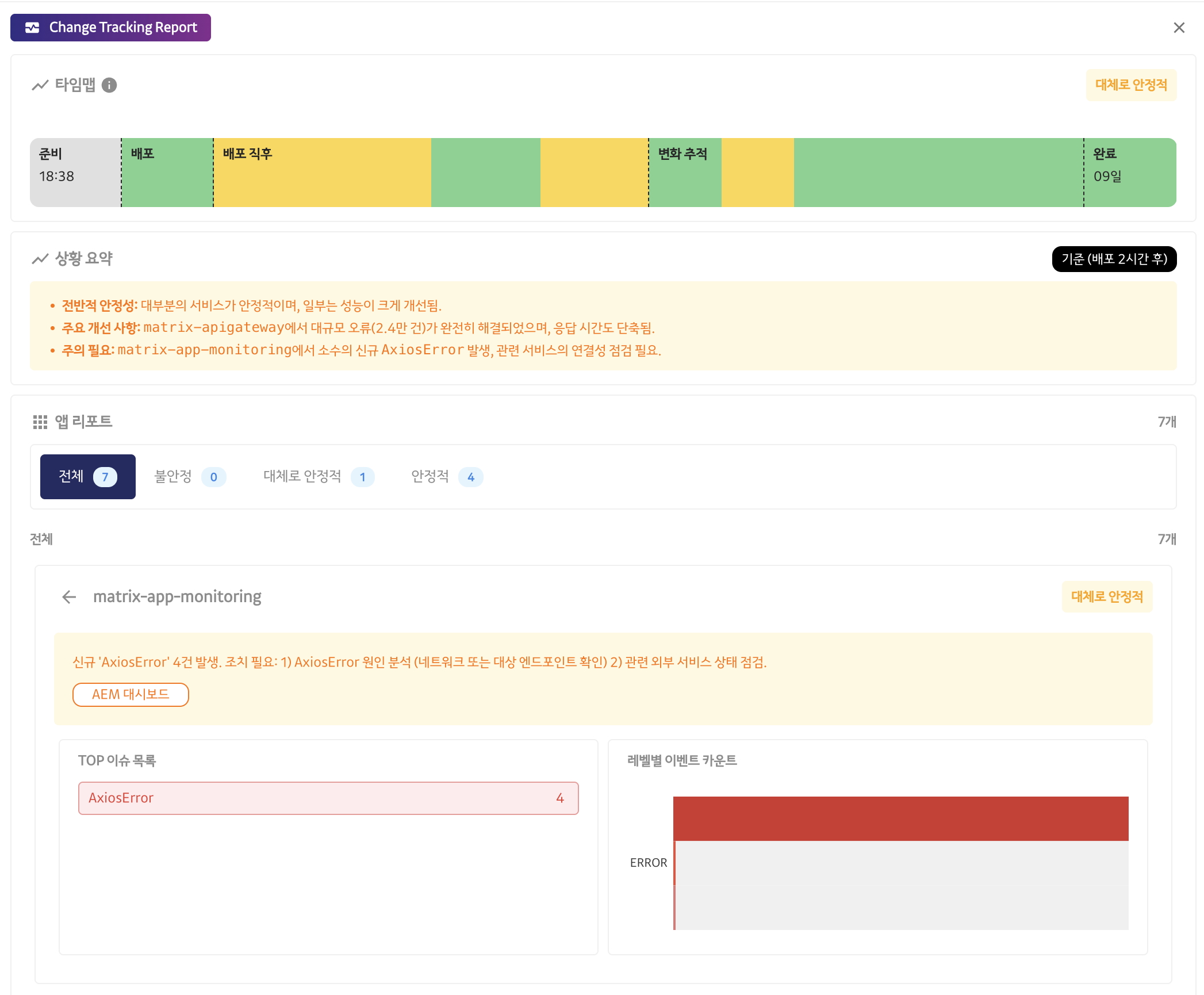
In particular, we conduct preliminary checks to ensure that the system is operating stably before distribution, and only proceed with deployment if no problems are found. In addition, immediately after distribution, we maintain frequent monitoring intervals and then gradually increase the monitoring intervals over time for efficient management. This systematic AI-based monitoring improves both service stability and operational efficiency.
How is service status determined?
The service status is determined based on data collected from the matrix.
- Request throughput and error-handled requests
- Request response time (p50, p90, p95)
- Error log statistics by level
- Top Issue
- Incident Alarm History
The data used to determine the status of the system can be obtained internally from each lineup (OpenTelemetry, APM, LOG, Prometheus, etc.) of the matrix. However, it is difficult to determine whether the service is actually stable or unstable based on the absolute values of this data alone.
For example, if the request response time (p50) for a service is 2 seconds, it does not necessarily mean that there is a problem. This is because the service may have a characteristic that allows a response time of about 2 seconds.
To overcome these limitations, the change tracking feature determines the status based on relative values rather than absolute values. In other words, we compare current data with data from 24 hours ago or a week ago to analyze trends in changes.
This method considers it an abnormal condition if the number of errors has increased sharply compared to yesterday or a week ago, or if the response time has increased significantly. By comparing relative data in this way, we can detect anomalies that deviate from normal service patterns more accurately.
Structured response format
In many cases, it is necessary to further process the LLM’s response before delivering it to the user. Similarly, in change tracking, when the LLM specifies the problematic metric, Matrix AI adds additional query results for that metric and sends them to the client.
Through this process, users can obtain not only simple comments but also more detailed and specific information, greatly improving their understanding of the problem situation.

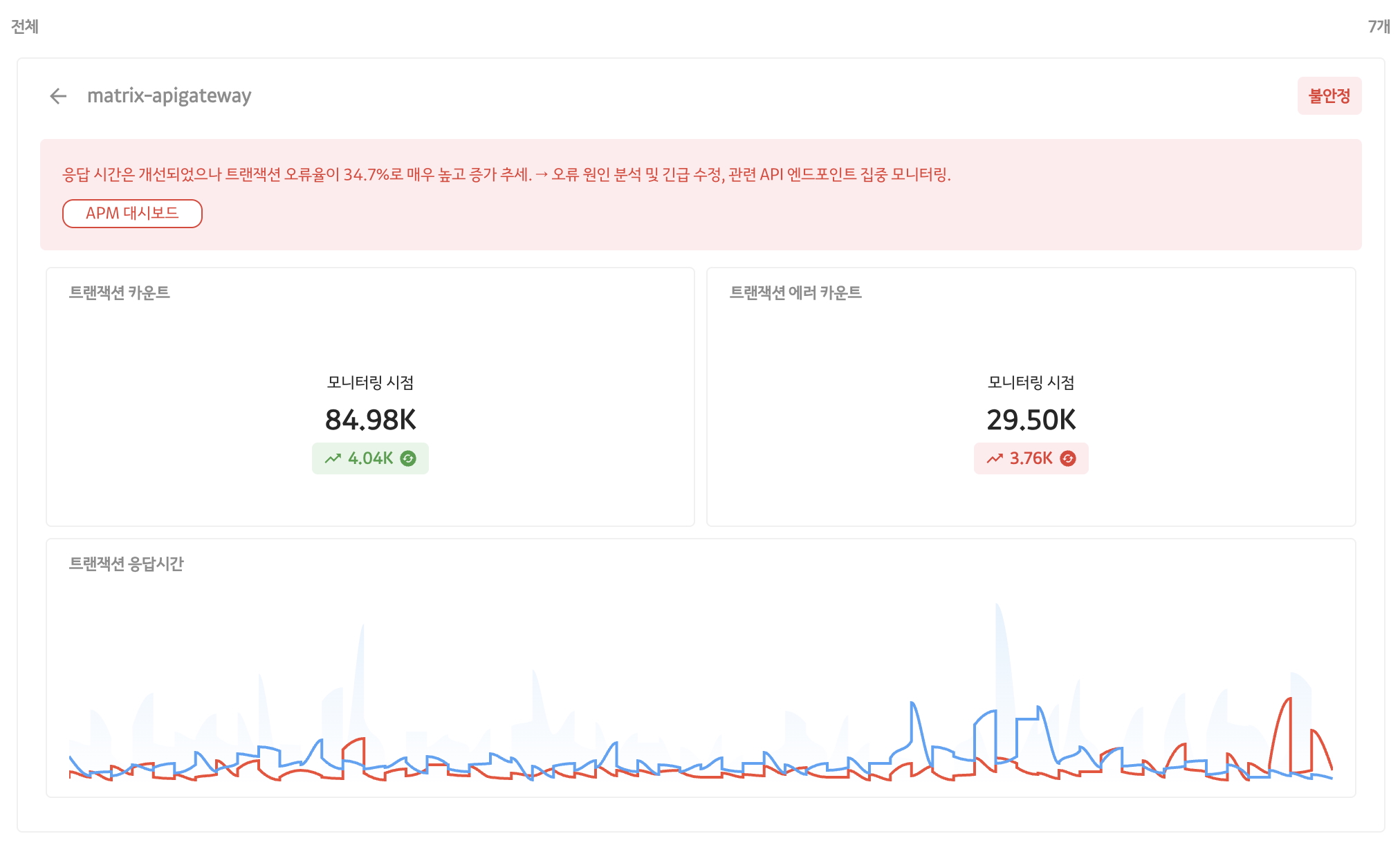
In order to effectively process LLM responses, structured responses such as JSON are required rather than simple text.
For example, let’s assume that the following response is received:
{
"message": "현재 TEST 애플리케이션은 2025-06-15 12:00~13:00 사이에 에러 트랜잭션 카운트가 지난주보다 크게 증가 했습니다."
}
Simple text responses like this have limitations when it comes to the application performing additional processing or analysis. On the other hand, if a JSON response structured as follows is provided, the situation changes.
{
"application_name": "TEST 애플리케이션",
"issue_start_time": "2025-06-15 12:00:00",
"issue_end_time": "2025-06-15 12:00:00",
"issue_metric":
[
"error_transaction"
]
}
The application automatically performs additional queries for the error_transaction metric through JSON parsing, providing more information to the client. Structured responses like these greatly increase data utilization and automation levels.
All of the leading LLMs effectively support these structured responses via APIs. What is even more remarkable is that the LLM fills in the required values in the correct locations based on the key values of the predefined response format. This enabled us to obtain the desired data in a stable manner.
Below is an example of the response format used in change tracking. Using this format, we confirmed that the LLM generates responses as intended.
{
"type": "json_schema",
"name": "application_health_report_format",
"format":
{
"type": "object",
"properties":
{
"applications":
{
"type": "array",
"items":
{
"type": "object",
"properties":
{
"name":
{
"type": "string"
},
"applicationId":
{
"type": "number"
},
"state":
{
"type": "string",
"enum":
[
"STABLE",
"MOSTLY_STABLE",
"UNSTABLE"
]
},
"metric":
{
"type": "array",
"items":
{
"type": "string",
"enum":
[
"TRANSACTION",
"ALERT",
"ISSUE"
]
}
},
"comment":
{
"type": "string"
}
},
"required":
[
"name",
"applicationId",
"state",
"metric",
"comment"
],
"additionalProperties": false
}
},
"state":
{
"type": "string",
"enum":
[
"STABLE",
"MOSTLY_STABLE",
"UNSTABLE"
]
},
"comment":
{
"type": "string"
}
},
"required":
[
"applications",
"state",
"comment"
],
"additionalProperties": false
}
}
24-hour non-stop AI-based service monitor: AI On-Call
The knowledge base-driven service health AI monitoring built for change tracking is currently being expanded with AI on-call functionality. Even now, many major platforms and services designate on-call personnel to detect problems first and quickly communicate the situation 24 hours a day, 365 days a year. On-call personnel do not simply detect problems; they also act as a bridge, either resolving issues directly or quickly connecting the appropriate personnel.
However, it is not realistic for any organization to have on-call personnel available 24 hours a day, 365 days a year. It is particularly challenging to manage personnel during periods of external activities, such as holidays and group workshops. In such situations, AI OnCall can be of great help.
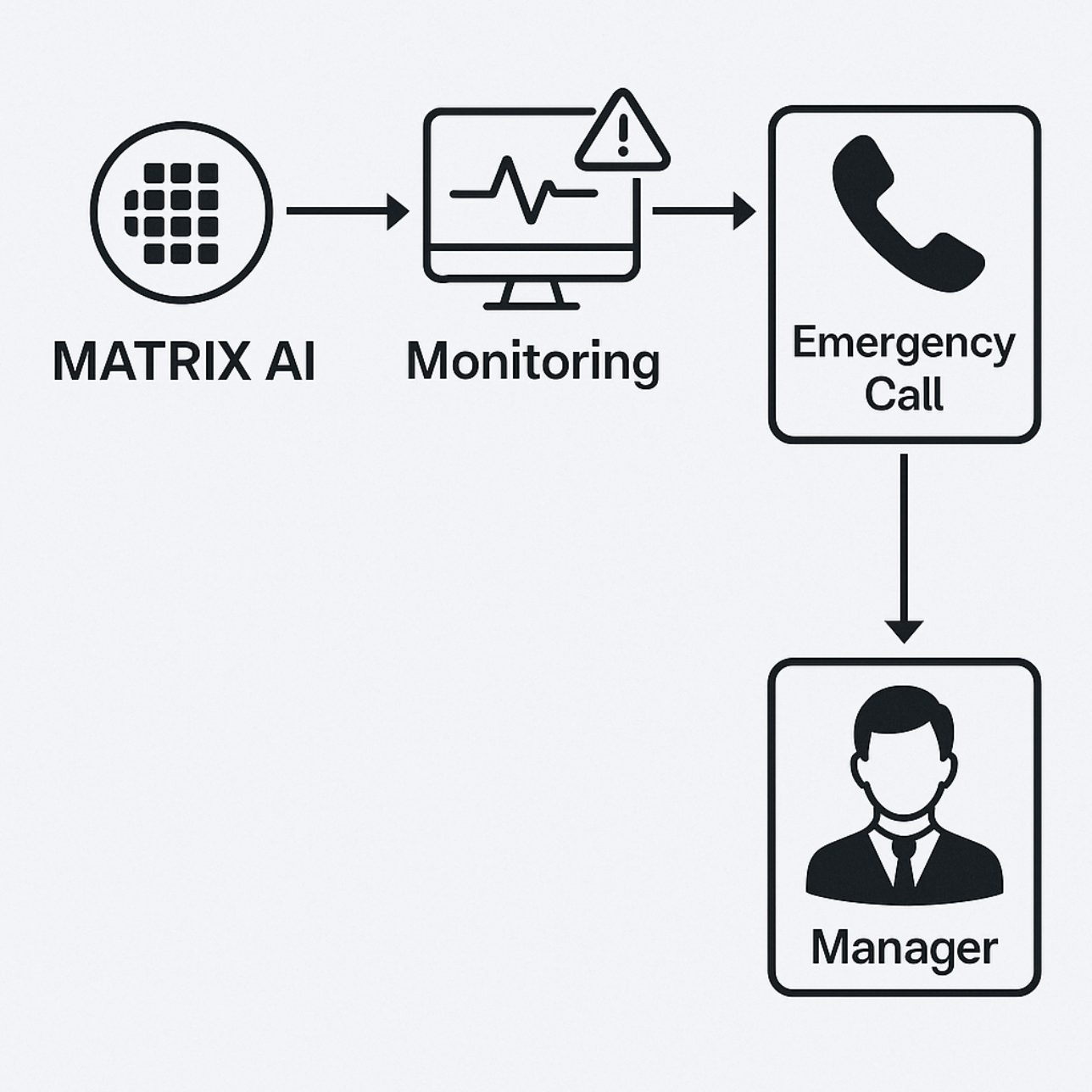
AI OnCall can provide functions such as service health monitoring, user inquiry response, and notification transmission to incident handlers.
In particular, incident managers can be notified directly by phone depending on the severity of the situation. To this end, we have utilized telephone API and TTS (text-to-speech) technology, and designed the system to automatically look up the contact number of the person in charge so that we can quickly get in touch.
The beginning of autonomous code improvement and automation: Code Tuning Agent
It is no exaggeration to say that we are now in the “age of coding agents.” Recently, there has been an increase in code automatically generated by AI such as Cursor and Claude Code, rather than code entered directly by developers. As coding agent AI models develop rapidly, there are growing expectations that AI will be able to modify code appropriately based on code-level error information and performance delay information provided to it.
Based on these ideas, the following system configuration diagram can be drawn.
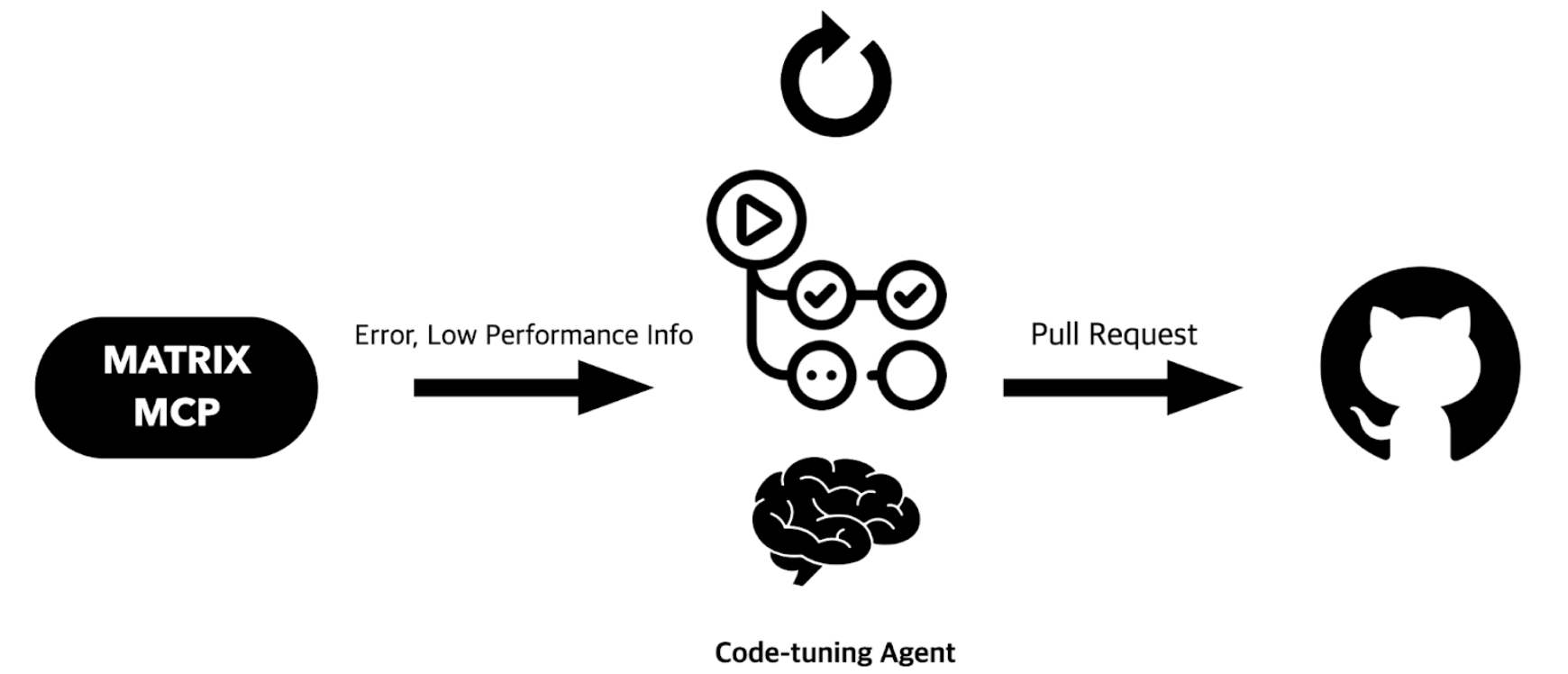
Matrix plans to open an MCP server to provide this diverse information to AI clients. Through the Matrix MCP server, we can transmit not only code-level error information such as error stack traces, error messages, and error codes, but also performance-related data such as slow transaction stack trace sets and slow SQL information.
This information is linked to the standard code of a pre-set branch, enabling the LLM to automatically modify the code and generate a PR (Pull Request).
For example, when the scheduler runs every morning via GitHub Actions, the Code-tuning Agent automatically posts new PRs. After arriving at work, the person in charge only needs to review the PR generated by the AI agent and merge it, which greatly improves the efficiency and productivity of the development process.
AI-native observability, the next step
Service monitoring consists of a cyclical process of “monitoring → detection → root cause analysis → action → reflection.” Through the AI-based examples introduced earlier, we can now effectively delegate many tasks, from monitoring and detection to root cause analysis and action, to AI. Although there are still challenges to overcome before the “reflection” stage can be fully automated, we expect that AI will soon take the lead in this area as well.