TOC
Generating TOC...
5.1. AI DevOps System, Kakao Release
AI has brought about significant changes to deployment and operating environments. Thanks to this, Kakao’s DevOps culture is also accelerating, and service stability is improving.
In this chapter, we will examine how AI is streamlining Kakao’s deployment workflow, making the operating environment predictable, and challenging the transition to autonomous operations where systems solve problems on their own, focusing on Kakao’s actual experiences and technical challenges.
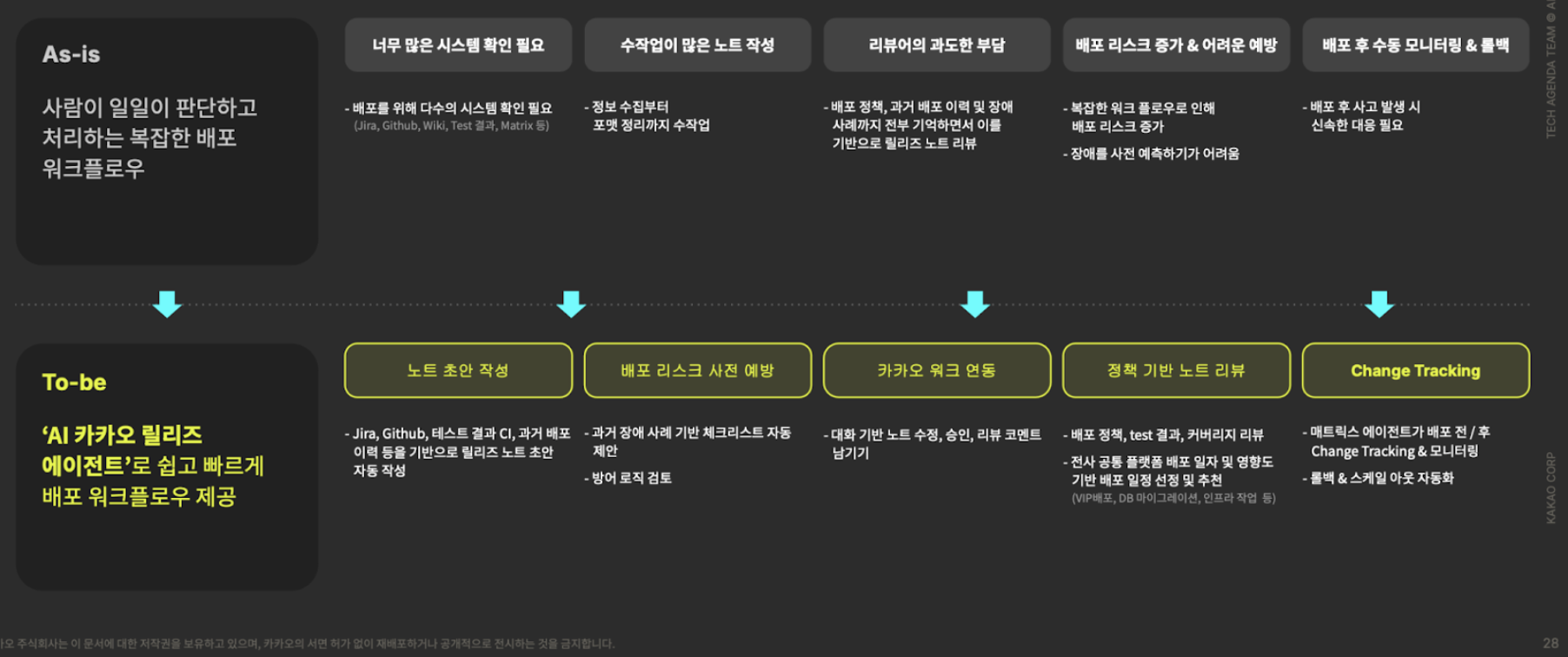
AI-based release management: Automatic documentation and risk analysis
Existing deployment management methods had several problems. Information about who deploys what and when is fragmented, and deployment and tasks that affect other services are not sufficiently shared across the company, sometimes causing unexpected problems.
In particular, in Kakao’s environment, where numerous services are intricately connected, problems caused by unpredictable service dependencies were frequent, and infrastructure work could have a widespread impact on the entire service.
In addition, there were clear limitations, such as risks that were not identified during the manual review process after the deployment plan was established, and an increase in the failure rate due to insufficient review during emergency deployment.
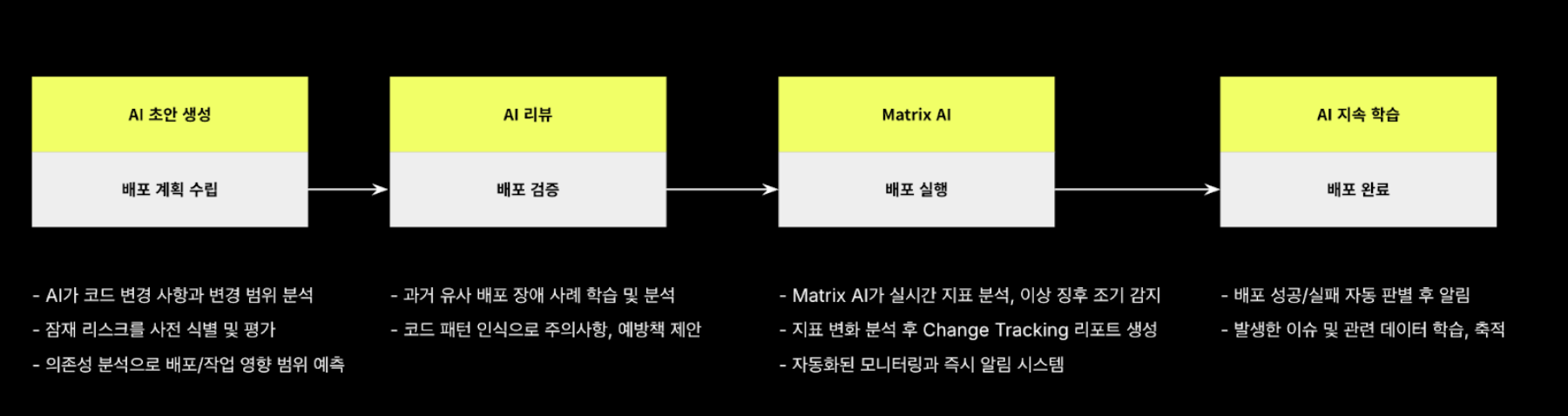
Kakao has built and operates Kakao Release, an AI-based release management platform, to solve these problems and redefine the deployment workflow. Kakao Release enables secure deployment by closely collaborating with AI throughout a series of processes, from establishing deployment plans to executing deployment and monitoring immediately after execution.
One of the core roles of Kakao Release is to automate the creation and review of release plan documents. Let’s take a look at how AI is solving the most time-consuming and quality-inconsistent areas of document creation and review.
Automatically generate complex deployment/task notes with AI agents
As mentioned earlier in the introduction to Kakao Release, the first area where AI was introduced was deployment/task note creation. Release notes typically include information such as a summary of changes, new features, and bug fixes.
However, in an environment where numerous services are intricately connected, such as Kakao, it is important to understand in advance how the deployment of one service will affect other services. To this end, Kakao writes documents that are more detailed than typical release notes.
Release notes are written when deploying application code, while work notes are written mainly for infrastructure tasks such as database version upgrades, server replacements, and certificate renewals.
These documents include changes and impact scope of deployment/work, rollback strategies and scenarios, monitoring scenarios, deployment/work personnel, and pre- and post-deployment/work checklists. Thanks to this, developers can determine in advance how a given release or task will affect related departments.
However, as the amount of information that must be included for safe deployment/operation has increased, document creation has become complex and time-consuming. In addition, depending on the author, important information may be omitted, or inconsistencies may arise due to the use of different writing formats within organizations. To solve this problem, we developed a feature that automatically generates deployment/work notes using AI.
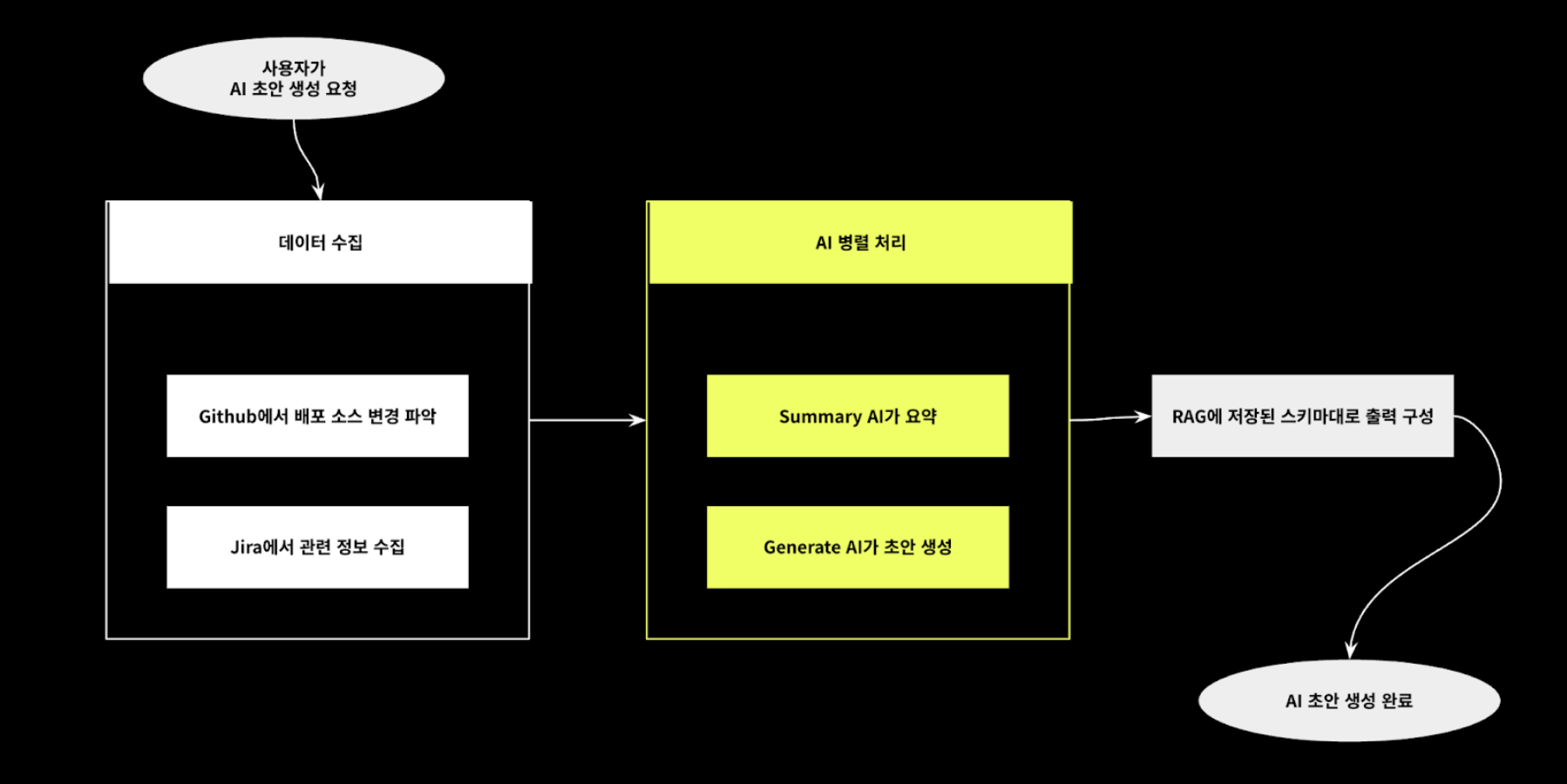
The process of AI generating deployment/work notes consists of three steps: ① Collecting data from GitHub and Jira, ② Summary AI summarizing the collected data and Generate AI creating a draft based on it, and ③ Referencing the schema stored in RAG to structure the output format.
① Data collection stage
- Extract commit diffs from GitHub branches or tags entered by the user.
- Understanding the scope of changes and the scale of changes in this release
- Identify pull requests related to the commit to be deployed
- Analyze Jira issues, including titles, descriptions, assignees, and acceptance criteria, to understand the planning intent and development objectives
- Analyze the five most recent deployment/task notes in the workspace¹
② AI processing stage
- Summary AI summarizes collected data
- Generate AI automatically creates notes in parallel
- Approximately 75% improvement in processing speed through parallel processing and context compression
③ Schema application stage
- Configure the output format by referring to the schema stored in RAG.
- Format verification and post-processing completed
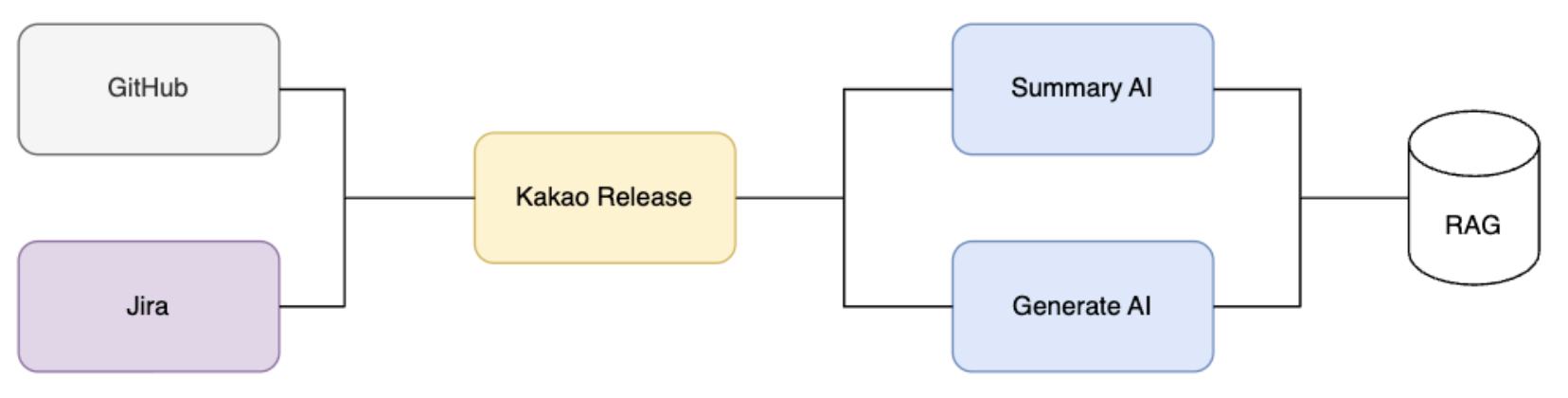
Initially, we expected that extracting relevant context from GitHub and Jira and feeding it into the LLM would immediately produce complete results. We kept the architecture simple because we expected to achieve satisfactory results without complicated processing.
However, the actual implementation process required more engineering work than expected. We needed to efficiently compress and transmit large amounts of context, and executing multiple API calls and AI processing caused response delays. In addition, the quality of the context was degraded due to noise in the raw data, and there were problems with the quality and format of the output results varying each time.
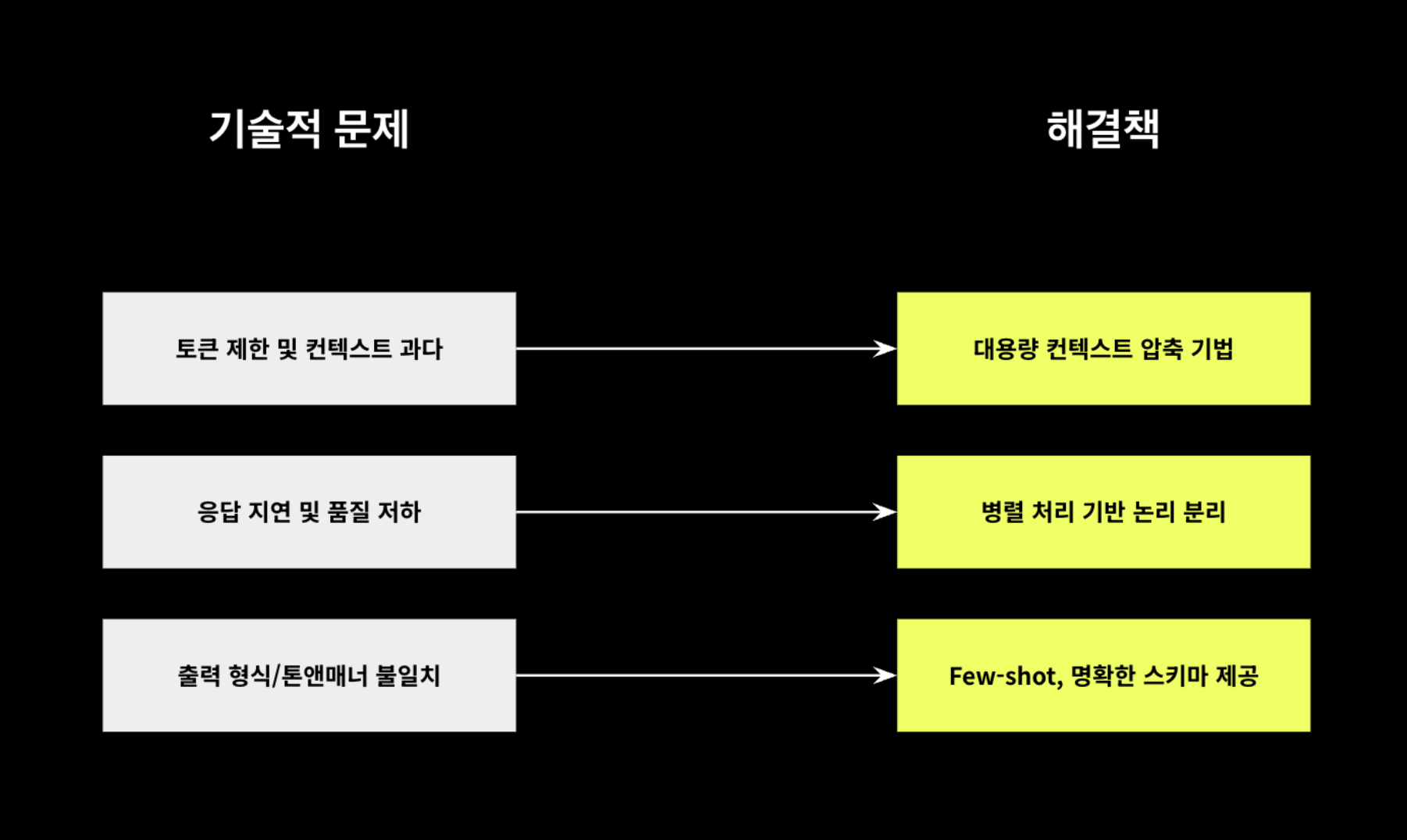
① Token limitation issues and large-scale context compression techniques
The context window of LLM has greatly expanded (GPT-4: 128k, Claude-3: 200k), compression is still needed. Although input token costs are trending lower than output token costs, costs increase significantly as the number of tokens accumulates.
In addition, processing time increases in proportion to the number of tokens, so designing the architecture and implementing functions in a way that keeps the number of tokens as low as possible is a cost-effective and efficient way to ensure performance.
To achieve this, it is necessary to focus on core information so that the essence can be processed without accumulating information, even with a minimum number of tokens. This is also related to the improvement of response quality.
After extracting only the core data necessary for drafting from each Jira issue and GitHub information, we created independent chunks² and create a ‘summary AI’ for summary in an asynchronous parallel processing manner. In addition, we extract only the necessary information from the five most recent distribution/work notes and summarize them in the same manner.
By cleaning and summarizing the input data in this way, the context has been structured around the core content. In particular, Jira issues and GitHub information were compressed by approximately 95%, from approximately 44,000 tokens to 2,300 tokens, enabling us to reduce unnecessary information and effectively improve content quality.

② Improved result quality and minimized response delays through parallel processing
Initially, we collected information from various sources, such as Jira, GitHub, and recent release histories, and delivered it to AI as a single long context for drafting release notes. This method had the problem of long response times and poor quality due to the AI’s inability to efficiently understand key content.
Considering the limitations of AI processing, we classified the information for draft creation into four logical units. In other words, we divided the information into four parts: basic information, checklist, main text, and repository information for deployment. By processing each part as an independent request in parallel, we enabled the AI to focus on each request.
We realized that the key is not simply entrusting everything to AI, but rather engineering optimization through data structuring and parallelization. As a result, draft quality improved, and processing speed improved by approximately 80%, from an average of over 120 seconds to within 30 seconds.

③ Actual application examples of few-shot learning
When we looked at how users write notes to draft something, we found that everyone has their own style, like tone, sentence structure, and how they use fields. In addition, there were inconsistencies with the maximum length (maxLength) and data types defined internally within the system, making it difficult for the AI to generate consistent drafts and increasing post-processing costs.
To solve this problem, we provided examples of best practices using few-shot³ and defined a clear schema to apply to RAG, thereby achieving uniformity in output format and expression style. We achieved high-quality results without taking many shots, and schema-based output greatly reduced post-processing work and improved the consistency of results.
As a result, we achieved significant improvements in three areas: ensuring consistency in tone and manner, maintaining consistency in output formats, and streamlining post-processing based on structured data.
[Schema example for Few-shot learning]
{
"type": "object",
"description": "배포 노트 초안 생성을 위한 입력 스키마입니다. noteDetails, checklistGroup, agitIntegrations, matr"+"ixIntegrations로 구성됩니다.",
"properties": {
"noteDetails": {
"type": "object",
"required": [],
"description": "배포 노트의 주요 필드.",
"properties": {
"title": {
"type": "string",
"maxLength": 100,
"description": "배포 노트 제목. 행동 지침을 준수하여 생성"
},
"content": {
"type": "string",
"default": "",
"maxLength": 10000,
"description": "리뷰어가 인지해야 하는 주요 배포 내용. 행동 지침을 준수하여 생성"
},
"rollbackStrategy": {
"type": "string",
"default": "REDEPLOY_NO_BUILD",
"enum": [
"REDEPLOY_NO_BUILD", "REDEPLOY", "CANARY", "BLUE_GREEN", "ETC"
],
"description": "롤백 전략"
}
}
},
"checklistGroup": {
// 중략
},
"agitIntegrations": {
// 중략
},
"matrixIntegrations": {
// 중략
}
}
}
Reconstructing the review process through collaboration between humans and AI
AI not only automatically generates draft deployment/work notes, but also reviews the written notes to identify potential risks in advance and determine their severity. This review process helps to improve the overall security of the deployment process.
Previous note reviews relied on the reviewer’s experience. The operations team would either judge that “such changes could be risky” based on past experience, or check each item on a checklist to see if anything had been overlooked. However, this method varies in quality depending on the reviewer’s experience and condition. In particular, there was a problem in that it was difficult to secure sufficient review time in emergency deployment situations.
Kakao Releases has overcome these limitations by establishing an AI-based automatic review system. This system stores more than 500 past failure cases in a vector database, identifies similar risk patterns in the current deployment plan, automatically detects and analyzes the company-wide deployment schedule to predict potential conflicts, and automatically verifies compliance with the “release standards” established for safe deployment.
What makes AI reviews particularly helpful is that AI goes beyond simply verifying policy compliance to explaining “why it is risky” and suggesting “what alternatives are available.” For example, for work notes related to certificate replacement, it provides practical advice such as informing you of the certificate expiration time and advising you to check it, or summarizing deployment/work plans for the same day and time to assess potential risks.
The AI review process consists of three steps: ① collecting incident logs, ② collecting context, and ③ AI review. Each step involves collaboration between AI and algorithms for optimal accuracy.
① Collecting disability logs
When reviewing deployment/work notes, there was a need to automatically refer to past failure cases to avoid repeating the same mistakes. However, previously, disability logs were stored in long texts scattered across different locations, and there was no structure in place to connect or utilize them in real time during reviews.
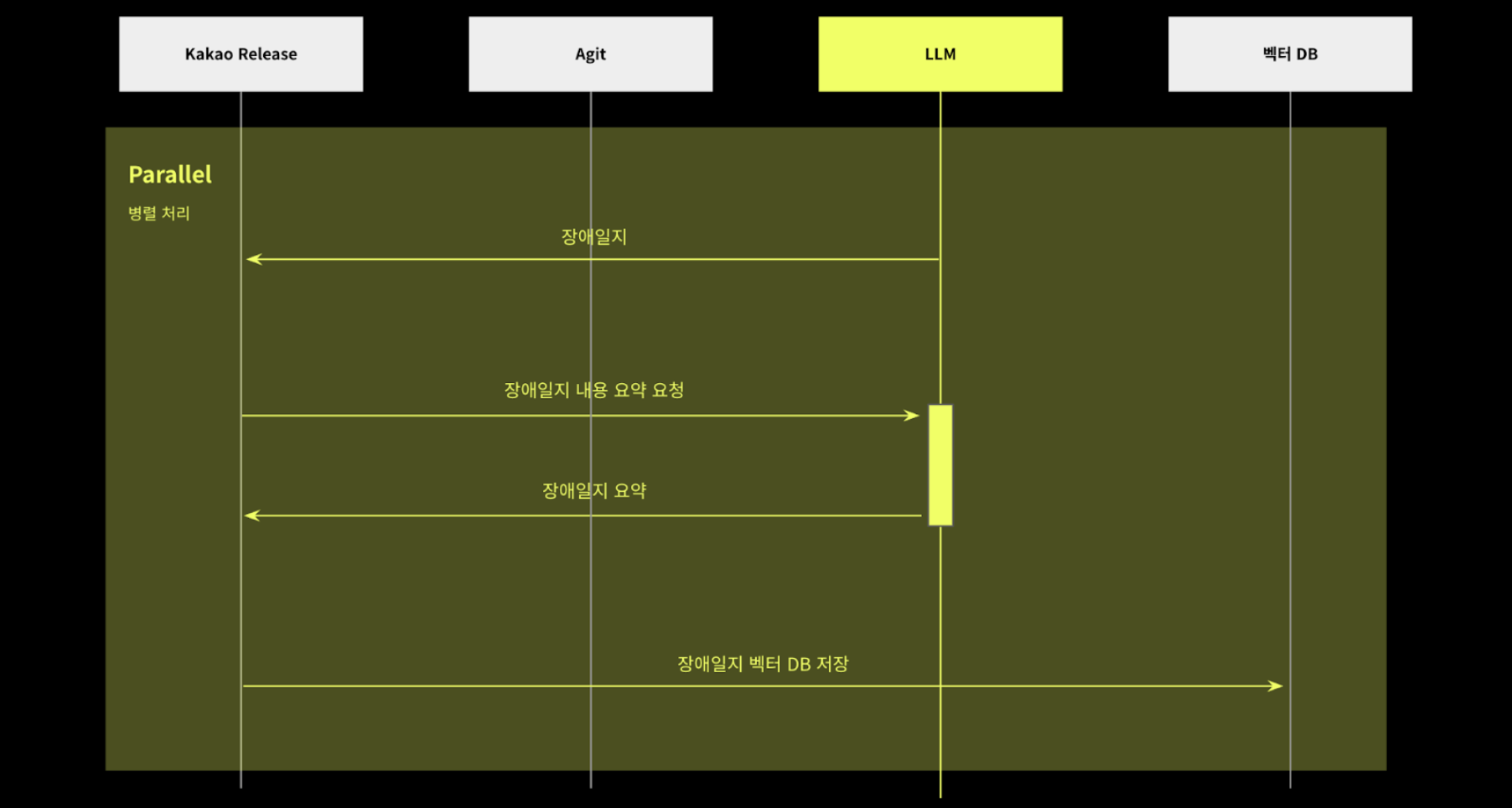
To solve this problem, we built a process that automatically collects bug reports registered on Agit (Kakao’s internal collaboration/community platform) based on webhooks, summarizes only the key information using Recap AI, and then embeds it as vectors and stores it in the RAG system.
The vector DB built this way can be searched in real time when AI reviews deployment/work notes, enabling automatic reference to past failure cases that match the context. Users do not need to search for incident logs separately, and AI can generate review opinions based on richer context. Through this structure, previously unconnected incident logs and note reviews have been integrated into a single flow.
As a result, AI-generated reviews have evolved to not only evaluate the notes themselves, but also to refer to past organizational experiences, enabling them to identify potential risks in advance. As the context of disability response was naturally incorporated into the notes, both the depth and reliability of the reviews were noticeably improved.
② Context collection
In order to enable AI to perform reviews, we collected and organized various policy-related data in advance. First, we compared the entire release calendar with the work schedule to identify any conflicts with other schedules that could affect the entire company.
In addition, in accordance with the release standard policy, we have collected the following items in a form that can be checked.
- Multiple responsibilities: At least two operators must be designated.
- Monitoring hours: Weekday working hours or monitoring hours
- Checklist Group: Mandatory checklists based on work type
- Required reviewers: Reviewer level requirements based on the impact of the work
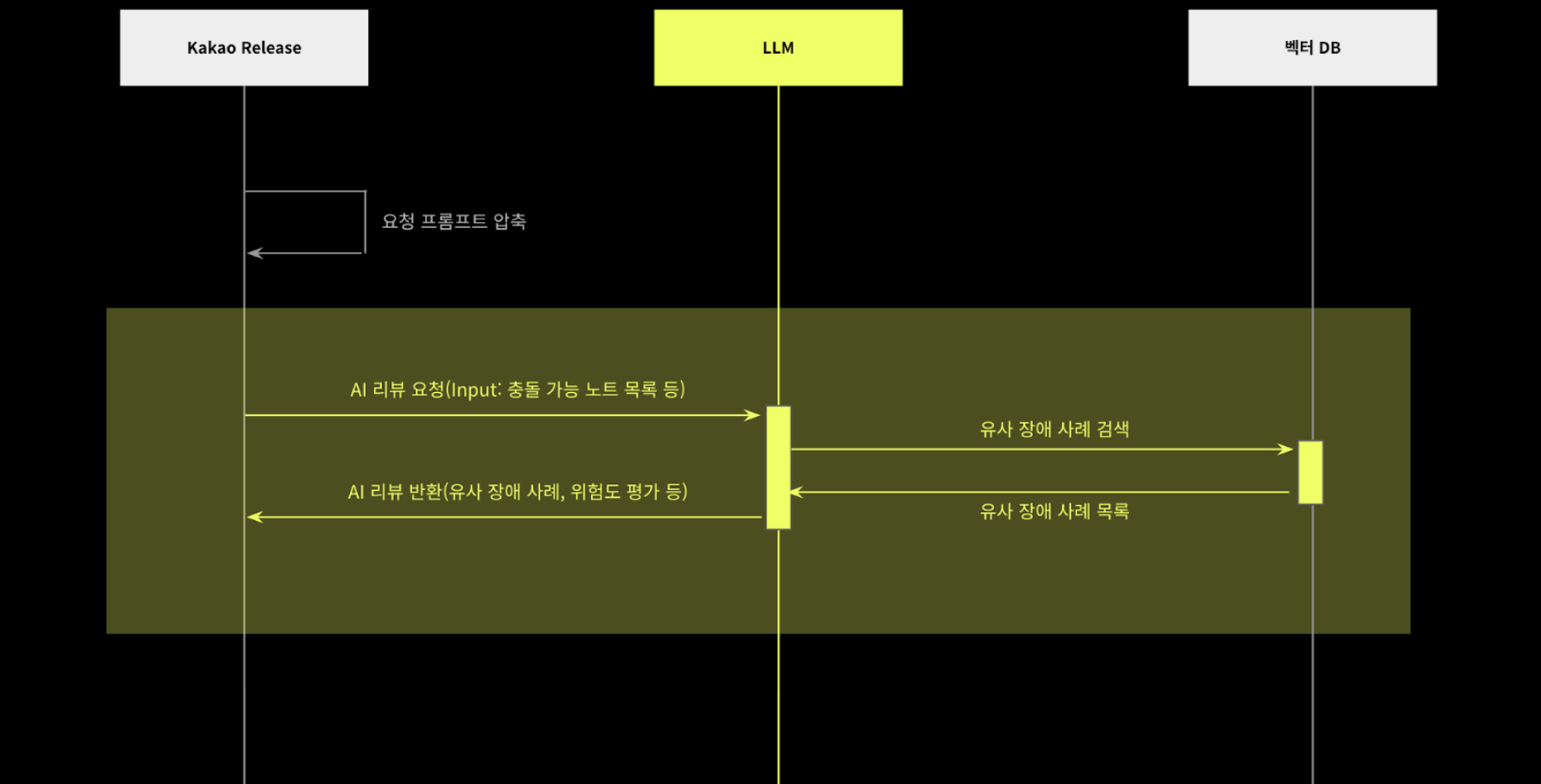
③ AI Review
AI reviews used a hybrid approach to simultaneously improve review efficiency and quality. We have built a workflow that combines the precise rule checking capabilities of algorithms with the flexible reasoning capabilities of AI.
First, in the “② Context Collection” stage, we automatically detect conflicts with the deployment and work schedules of other services that affect the entire company and check compliance with release standard policies. This process is algorithm-driven and quickly and accurately reviews clear rule-based issues such as policy violations and schedule interference.
AI analyzes past cases of disabilities. Through text similarity-based search, it finds past issues similar to the current task and helps you recognize potential risks or missing considerations in advance.
Through a hybrid approach in which algorithms quickly and accurately handle rule-based problems and AI provides flexible, data-driven insights, we were able to improve review quality and minimize operational risk.
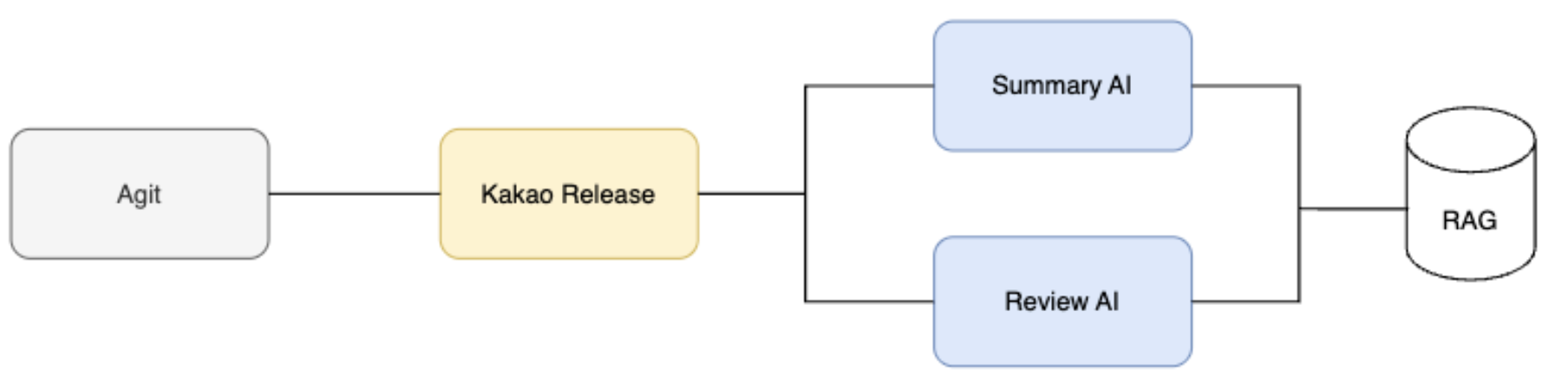

Vision for the complete automation of Kakao Releases
Kakao Releases aims to automate the entire release workflow, including note creation, review, deployment, and monitoring, using AI agents and systems, so that developers can focus more on development without having to write release notes.
To this end, we are utilizing AI beyond deployment planning and review to extend its use to post-deployment operations. In actual operating environments, unexpected variables occur, and it is particularly important to monitor service stability during the first 24 hours after deployment.
Previously, developers and operations teams manually checked service status by monitoring dashboards during this time. It requires considerable experience and time to identify issues such as increased error rates, response time delays, and changes in traffic patterns, determine the correlations between them, and determine whether they are caused by deployment.
To solve this problem, Kakao Release has developed a change tracking feature in collaboration with Matrix AI. Change tracking is a feature that analyzes data patterns for 24 hours after deployment execution to detect changes in data status in real time and determine the overall status.
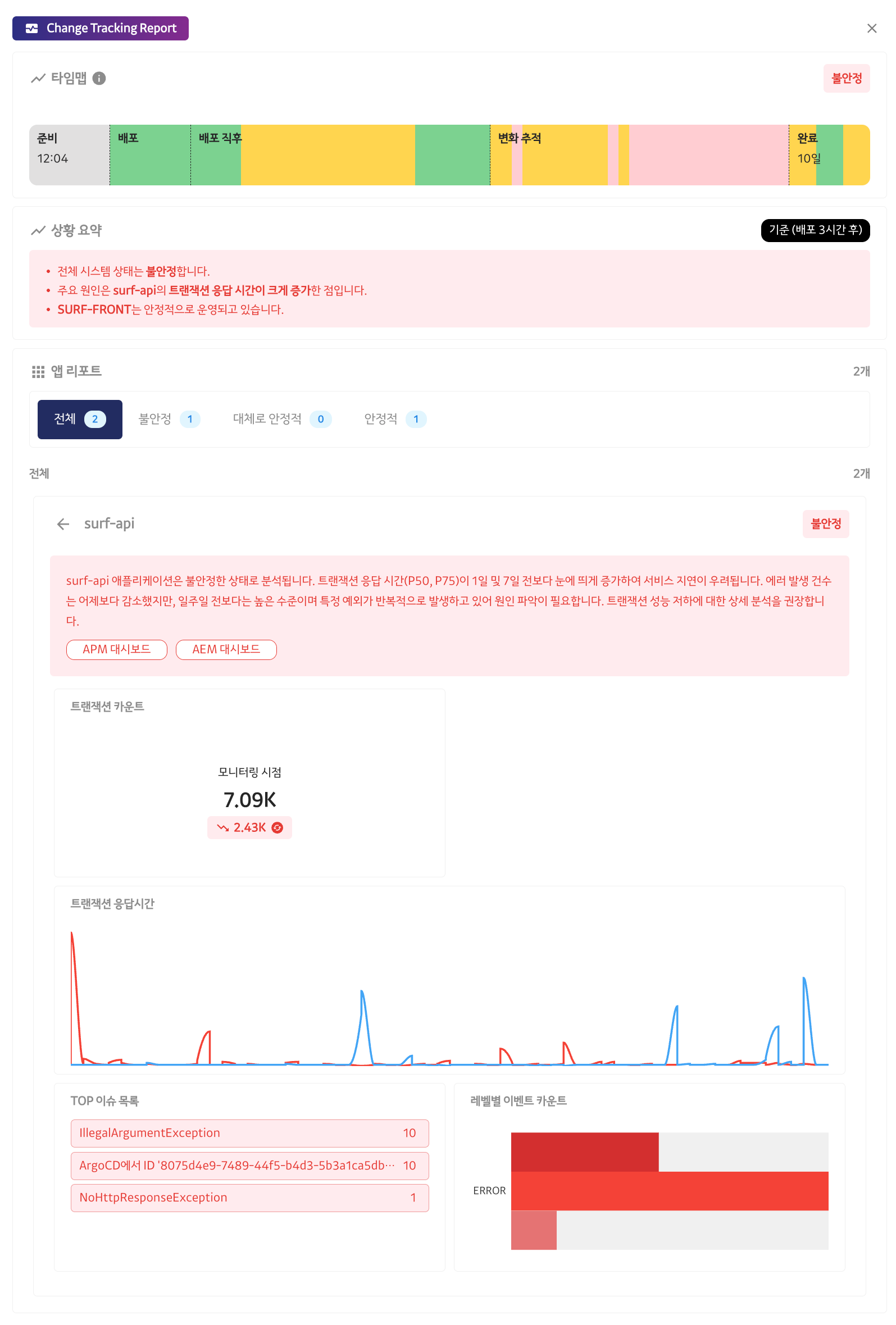
This change tracking feature allows developers to reduce the burden of ongoing monitoring after deployment.
Kakao Releases envisions a future where AI and systems automatically handle every step of the process, from the moment a developer pushes code to the final stage of safely providing services to actual users. It means E2E automation that ensures reliable quality and speed without human intervention.
In reality, for a major release to happen, multiple services, such as back-end and front-end, need to work together organically. For example, when deploying a web service, it is often the case that not only the back-end code is changed, but the front-end is also modified and released.
Kakao Releases aims to automate this complex deployment process as much as possible. When a tag is pushed from each module, a distribution note is automatically generated, and AI reviews it to check for any problems. It is particularly noteworthy that the changes made to these various modules are consolidated into a single release note.
This allows you to see all changes to various components, such as back-end and front-end, at a glance, ensuring that all deployment-related information is managed consistently without fragmentation. Work that passes review is automatically deployed, and after deployment, the monitoring system detects service status in real time.
If any abnormal signs are detected, AI analyzes the cause and determines whether a rollback is necessary for the relevant module, whether it is back-end or front-end, and then immediately takes the necessary measures.
In addition, the Kakao Release platform is designed to be independent of specific deployment (CD) tools and to enable flexible integration with various deployment tools in the future, much like plugins. We are laying the groundwork to flexibly accommodate the requirements of various teams and projects by allowing them to freely attach their preferred deployment tools, such as ArgoCD and Jenkins, according to each organization’s technology stack.
This will enable each team to maintain their own deployment environments while consistently enjoying the benefits of AI-based automation provided by Kakao Release.
Footnotes
1) The basic unit of work in Kakao Release
2) A chunk refers to grouping multiple separate pieces of information into a single meaningful unit.
3) Few-shot Learning is a machine learning method that enables a model to learn or classify new tasks using only a very small number of example data points.