목차
목차를 생성하는 중...
2.4. 실시간 코드 리뷰 및 품질 관리
현대 소프트웨어 개발에서 코드 리뷰는 품질 보증과 팀 내 지식 공유를 위한 필수 절차로 자리잡았습니다. 코드 리뷰는 일반적으로 다음 두 가지 방식으로 수행됩니다.
- 사후 리뷰: PR(Pull Request) 기반의 리뷰로, 코드가 작성된 후 병합 전 검토되는 방식
- 사전 리뷰: 작성 중이거나 완성 직후의 코드를 짝이나 시니어가 직접 확인하는 방식
이러한 리뷰 문화는 코드의 가독성과 일관성 유지, 오류 조기 발견, 보안 결함 방지에 긍정적인 영향을 줍니다. 그러나 전통적인 방식에는 뚜렷한 한계점이 존재합니다.
PR(Pull Request) 기반 코드 리뷰는 코드 작성 시점과 승인 시점 사이에 평균 4~24시간의 지연이 발생합니다. 특히 다음과 같은 상황에서 리뷰 병목이 두드러집니다.
- 리뷰어가 제한되어 팀 전체의 PR 대기가 누적됨
- 리뷰 기준이 문서화되지 않아 PR마다 해석이 다름
- 코드 양이 많거나 복잡도가 높을수록 피드백이 단절되기 쉬움
다양한 연구 및 GitHub 데이터 분석 사례에 따르면, 평균 PR 머지 시간은 수 시간에서 수십 시간에 이르는 것으로 보고됩니다. 팀의 규모, 리뷰어 수, 코드 변경량, 자동화 수준 등에 따라 편차가 존재하지만, 일반적으로 ‘PR 하나당 평균 1영업일 이상(≈24시간 이내)’이 소요된다는 점은 대부분의 프로젝트에서 공통적으로 관찰됩니다. 이러한 지연은 팀의 배포 주기와 피드백 속도에 직접적인 영향을 미칩니다.
이러한 지연의 주요 원인 중 하나는 코드 리뷰가 명확한 판단 기준 없이 사람의 직관에 크게 의존한다는 점입니다. 특히 사람 중심 리뷰는 다음과 같은 한계를 갖습니다.
🅧 “이 함수는 조금 복잡하네요”
🅧 “이 부분은 나중에 리팩토링하면 좋겠어요”
🅞 “이 메소드의 인지 복잡도(Cyclomatic Complexity)가 15를 초과합니다 (기준: 10)”
이처럼 정량 기준이 결여된 피드백은 수용 여부가 리뷰어의 영향력이나 작성자의 경험에 좌우되기 쉽고, 리뷰의 일관성과 공정성을 저해합니다. 또한 리뷰 시 가장 심각한 문제는 보안 결함이나 치명적 버그를 리뷰 단계에서 놓치는 경우입니다. 예를 들어 SQL 인젝션 취약점은 다음과 같은 코드에서 자주 발생합니다.
String query = "SELECT * FROM users WHERE name = '" + username + "'";
이 코드가 PR에 포함되더라도, 리뷰어가 평소에 보안 감수를 하지 않는다면 이슈를 발견하지 못할 수 있습니다. 이처럼 리뷰어의 지식 편차나 피로도가 코드 안전성에 직결된다는 점에서, 자동화된 보조 수단의 필요성이 점점 부각되고 있습니다.
AI 도입의 필요성과 기대 효과
전통적인 코드 리뷰의 한계를 보완하고 개발 효율성과 품질을 동시에 향상시키기 위해, 최근에는 AI 기반 자동화 리뷰 시스템의 도입이 빠르게 확산되고 있습니다. 특히 LLM과 정적 분석 알고리즘이 결합된 형태는 단순한 정규식 기반 리뷰를 넘어서, 문맥을 이해하고 판단을 제시하는 수준으로 진화하고 있습니다.
1. 반복성 높은 패턴의 자동 감지
코드 리뷰에서 반복적으로 지적되는 사항은 대부분 정적 규칙이나 구조적 문제에서 비롯됩니다.
예를 들어:
- 메소드 길이 초과
- 중복된 if-else 블록
- 하드코딩된 상수
- try-catch 누락
이러한 패턴은 사람이 수작업으로 찾기보다는, AI가 코드 구조를 분석하여 정해진 규칙 또는 학습된 기준에 따라 자동으로 탐지할 수 있습니다. 예를 들어 다음 코드는 중복된 조건문과 과도한 복잡도로 지적될 수 있습니다.
if (user != null && user.getRole() != null && user.getRole().equals("ADMIN")) {
// ...
}
GPT-4 기반 모델은 위 코드를 보고 다음과 같은 코멘트를 자동으로 생성할 수 있습니다.
[AI Review] 조건문이 중첩되어 있어 읽기 어렵습니다. 아래와 같이 리팩토링을 고려해보세요:
Optional.ofNullable(user) .map(User::getRole) .filter(role -> role.equals(“ADMIN”)) .ifPresent(…);
2. 리뷰 속도 향상과 병목 제거
AI는 사람보다 빠르고 항상 대기 중이라는 특성을 지닙니다. 코드가 커밋되는 즉시 자동 리뷰가 트리거되면, 리뷰 결과를 몇 초 내로 제공할 수 있으며, 다음과 같은 형태로 구현됩니다.
- GitHub Actions 또는 사내 CI/CD 도구에서 PR 생성 시 정적분석 및 LLM 리뷰 에이전트 실행
- 리뷰 코멘트는 PR에 자동으로 등록
- 정적 분석 결과를 요약하여 인라인 코멘트(Inline comment)로 표시
이러한 구조는 팀의 코드 리뷰 병목을 최소화하고, 리뷰어가 오롯이 핵심 로직이나 아키텍처 판단에 집중할 수 있도록 여지를 만들어줍니다.
3. 정량화된 품질 피드백 제공
기존 리뷰가 주관적 코멘트에 머물렀다면, AI는 정량 기준 기반 리뷰 결과를 자동 리포트로 제공할 수 있습니다. 예를 들어 다음과 같은 메트릭이 포함된 결과가 가능합니다.

이러한 자동 리뷰 결과는 QA, 운영, 릴리즈 승인 등의 다음 단계로 쉽게 연계할 수 있으며, 데브옵스 흐름에서 일관된 품질 기준 적용이 가능해집니다.
4. 사내 특화 리뷰 기준 학습 가능
일반적인 오픈소스 기준 외에도, 사내 코드 스타일이나 장애 이력, 컴포넌트 구조 등에 특화된 리뷰 기준을 사내 자체 LLM 모델에 학습시킬 수 있습니다.
예를 들어:
- 과거 장애 유발 코드 → ‘유사 조건’을 학습하여 위험 알림
- 특정 라이브러리 버전 사용 금지 → 리뷰 시점에서 경고
- 공통 모듈의 변경 시 영향 범위 분석 → AI가 자동 댓글
이를 통해 AI 리뷰는 단순한 룰 기반 이상으로 진화하여, 팀/조직 맞춤형 리뷰 에이전트로 활용될 수 있습니다.
실시간 리뷰가 개발 문화에 미치는 영향
AI 기반 실시간 코드 리뷰는 단순히 리뷰 프로세스를 자동화하는 것을 넘어, 개발자 경험과 조직의 코드 품질 문화 전반에 큰 영향을 미칩니다. 특히 다음과 같은 세 가지 측면에서 그 효과가 뚜렷하게 나타납니다.
1. 피드백 주기의 단축
전통적인 리뷰는 리뷰 요청 → 검토 대기 → 피드백 수령 → 수정 요청 → 재검토의 흐름으로, 하나의 PR마다 수 시간이 소요되고는 했습니다. 하지만 AI 리뷰가 실시간으로 피드백을 제공하면서 다음과 같은 변화가 일어날 수 있습니다.
- 수정 주기가 분 단위로 단축됨 → 리뷰 병목 제거, 커밋 횟수 증가
- 즉시 확인 가능한 인라인 제안(Inline Suggestion) 제공 → IDE 또는 PR UI에서 바로 수정 가능
이러한 즉시성은 개발자에게 “코드를 작성하는 흐름(flow)을 끊지 않고 피드백을 받을 수 있다”는 점에서, 정서적 피로도 감소와 작업 몰입도 향상으로 이어집니다.
2. 리뷰 피드백의 표준화 및 심리적 안정성 증가
실시간 AI 리뷰는 누구에게나 동일한 기준으로 판단된 피드백을 제공하기 때문에, 다음과 같은 조직 문화적 긍정 효과가 나타납니다.
- 피드백의 일관성 확보: 리뷰어마다 다르게 해석되었던 코드 스타일 문제, 리팩토링 기준 등이 명확해집니다.
- 리뷰 주체와 피드백의 분리: 사람이 아닌 AI가 먼저 리뷰를 제공함으로써, 피드백 수용에 대한 심리적 부담이 감소합니다.
- 경험이 적은 개발자의 성장 지원: 신입 개발자도 리뷰를 통해 표준화된 개선 지점을 빠르게 인지하고 반복 학습할 수 있습니다.
예를 들어, 다음과 같은 코드 피드백이 사람이 아닌 AI 리뷰어로부터 제시될 경우 피드백 수용률이 더 높아지는 경향이 있습니다.
[AI Review] 이 메소드는 42줄로 구성되어 있어 유지보수가 어렵습니다.
메소드를 2개 이상으로 나누는 것을 고려해보세요.
사람 리뷰어보다 객관적·비판적이지 않은 방식으로 전달되며, 감정적 마찰 없이 개선이 이루어 질 수 있습니다.
3. 코드 품질 중심의 팀 문화 강화
AI 리뷰는 모든 코드를 동일한 기준으로 분석하고 기록할 수 있기 때문에, 팀 차원의 품질 관리가 자연스럽게 이루어집니다.
- 팀 코드 품질 지표의 가시화: 평균 순환 복잡도(Cyclomatic Complexity), 평균 커버리지, 중복 코드 비율 등을 자동 산출하여 주간 리포트로 공유 가능합니다.
- 리뷰 피드백 이력의 구조화: 팀 전체 리뷰 패턴을 분석하여 조직적 개선 방향을 도출할 수 있습니다.
- 리뷰-배포 연계 시나리오 강화: AI 리뷰 결과가 릴리즈 조건에 직접 반영되며, 품질을 기준으로 릴리즈 여부가 결정되는 문화를 조성할 수 있습니다.
AI 기반 정적 분석 기술
AI 기반 실시간 코드 리뷰가 가능하려면 코드를 지능적으로 분석하고 의미 있는 피드백을 생성할 수 있는 기반이 필요합니다. 그리고 이 기반을 정적 분석 기술이 제공해 줄 수 있습니다.
정적 분석(static analysis)은 프로그램을 실행하지 않고, 소스 코드 자체를 분석하여 오류나 취약점을 찾아내는 기술입니다. 이는 컴파일러가 수행하는 문법 검사 이상의 정밀한 분석을 포함하며, 현대 소프트웨어 품질 관리의 핵심 기법으로 널리 활용됩니다.
여기에 LLM과 같은 AI 기술이 결합되면서, 정적 분석은 단순한 규칙 기반의 검사를 넘어 코드의 문맥과 의미를 이해하고, 인간이 놓칠 수 있는 복잡한 패턴까지 감지하며, 더욱 정교하고 실용적인 피드백을 제공하는 수준으로 진화하고 있습니다.
AI 모델을 활용한 코드 복잡도 분석
정적 분석에서 코드 복잡도는 코드 품질을 수치로 계량화하는 가장 중요한 지표 중 하나입니다. 특히 순환 복잡도(Cyclomatic Complexity)와 인지 복잡도(Cognitive Complexity)는 함수 단위의 구조와 이해 난이도를 정량화하는 핵심 메트릭으로, AI 리뷰 시스템에서도 코드 위험도를 예측하는 중요한 기준으로 활용됩니다.
1. 순환 복잡도
순환 복잡도(Cyclomatic Complexity)는 제어 흐름 내 분기 지점의 수를 기반으로 계산되며, 일반적으로 다음 공식을 따릅니다.
M = E - N + 2P
- E (Edges): 프로그램 흐름 상의 경로 수
- N (Nodes): 조건, 문장 등의 실행 단위
- P (Connected Components): 보통 하나의 함수/프로시저는 1개의 연결 요소로 간주됨
하지만 대부분의 정적 분석 도구는 간단화된 계산 방식으로 아래와 같이 구현하기도 합니다.
M = 1 + 조건문의 수 (if, while, for, catch, case, &&, || 등)
[예제: Java 메소드의 순환 복잡도 계산]
public boolean validate(User user) {
if (user == null) return false;
if (user.getAge() < 18) return false;
if (user.isBlocked() || user.isBanned()) return false;
return true;
}
if3개||1개 → 1개 추가 분기- 총 복잡도: 1 + 3 + 1 = 5
일반적으로 10 이상일 경우 리팩토링을 권장하며, 20 이상이면 매우 복잡한 코드로 리뷰 또는 테스트 강화가 필요하다고 판단합니다.
2. 인지 복잡도
인지 복잡도(Cognitive Complexity)는 순환 복잡도보다 더 사람의 이해 관점에서 코드를 분석합니다. 단순 분기 수가 아니라, 중첩, 흐름의 깔끔함, 반환 위치의 예측 가능성 등을 고려합니다.
예를 들어 다음과 같은 코드는 순환 복잡도는 낮지만 인지 복잡도는 높게 평가될 수 있습니다.
for (...) {
if (...) {
while (...) { // 반복/분기 중첩이 깊을수록 Cognitive Complexity는 비선형적으로 증가
// … // 조건/루프 탈출이 예측 불가능하거나 흐름이 복잡하면 더 가중치 부여
}
}
}
인지 복잡도는 일반적으로 15 이상이면 이해하기 어려운 코드로 평가됩니다.
3. AI 모델은 복잡도를 어떻게 해석하는가?
LLM은 복잡도를 직접 수치 계산하지 않지만, 다음과 같은 방식으로 복잡도와 유사한 패턴을 인지합니다.
- 조건문, 루프, try-catch 구조의 AST 노드 수를 인지
- 코드 블록의 중첩 수준을 계산
- 분기마다 예외 처리·로깅·사이드이펙트 등 문맥 기반 복잡도를 반영
- 동일 기능을 구현한 다른 코드들과의 유사도(코사인 거리) 를 비교하여 ‘복잡한 구조’ 판단
[GPT-4 기반 코드 요약 예]
[AI Review] 이 메소드는 분기 조건이 많고, 예외 상황이 분리되어 있지 않아 가독성이 떨어집니다.
→ ‘isValidUser’와 ‘checkUserPermission’으로 분리해보세요.
4. AI + 수치 기반 복합 분석 예시
AI 리뷰 시스템에서는 다음과 같은 방식으로 수치 복잡도와 LLM 판단을 결합합니다.
{
"function": "validateUserAccess",
"cyclomatic_complexity": 13,
"cognitive_complexity": 21,
"ai_feedback": "중첩된 조건문과 긴 논리 조합으로 인해 이해하기 어렵습니다. 리팩토링을 권장합니다.",
"suggestion": [
"조건을 별도 메소드로 분리",
"로깅 및 에러 처리를 명시적으로 구조화"
]
}
이 결과는 GitHub PR 리뷰에 자동 첨부되거나, 품질 보고서의 일부로 리포팅됩니다. 나아가 배포 차단 조건 또는 QA 심각도 분류 기준으로도 사용될 수 있습니다.
보안 취약점 탐지 및 대응
코드 품질 못지않게 중요한 요소가 바로 보안입니다. 특히 프로덕션 환경에서 실행되는 코드에 존재하는 입력 검증 누락, 자원 접근 권한 오류, 하드코딩된 민감정보 등은 치명적인 서비스 장애와 정보 유출로 이어질 수 있습니다. 이러한 심각한 보안 이슈를 방어하기 위해 코드 정적 분석을 통하여 코드 실행 없이 코드 구조 및 문자열 리터럴 분석을 통해 보안 취약점을 사전 탐지할 수 있으며, 최근에는 여기에 AI 기반 문맥 해석 및 대응 제안 기능까지 결합되고 있습니다.
1. 주요 보안 취약점 유형(OWASP 기준)
OWASP Top 10은 코드 내 존재하는 보안 취약점을 체계적으로 분류한 국제적 기준입니다. 다음은 그중 일부 예시입니다.
| 유형 | 설명 | 예시 |
|---|---|---|
| A01: Broken Access Control | 인증 없이 중요한 자원 접근 | URL 권한 검증 누락 |
| A03: Injection | 입력값에 의한 명령어 조작 | SQL, LDAP, Command Injection |
| A06: Vulnerable and Outdated Components | 구버전 라이브러리 사용 | log4j, spring-security-web 취약 버전 포함 |
| A07: Identification and Authentication Failures | 허술한 인증 도구 사용 | 단순한 ID, 비밀번호 등 |
이 중 일부는 문자열 정규식이나 패턴으로 탐지 가능하지만, 상당수는 조건문의 흐름, 입력 필터링의 누락 여부, 예외 처리 구조 등 문맥 기반 분석이 동반되어 분석해야 취약점 검출이 가능합니다.
2. 정적 분석으로 탐지 가능한 보안 이슈
카카오 사내 정적 분석 도구 SCAN은 다음과 같은 보안 룰을 적용해 취약점을 탐지하고 있습니다.
[예제: Dynamic Injection 탐지 (TypeScript)]
let value = eval('obj.' + propName);
정적 분석 결과:
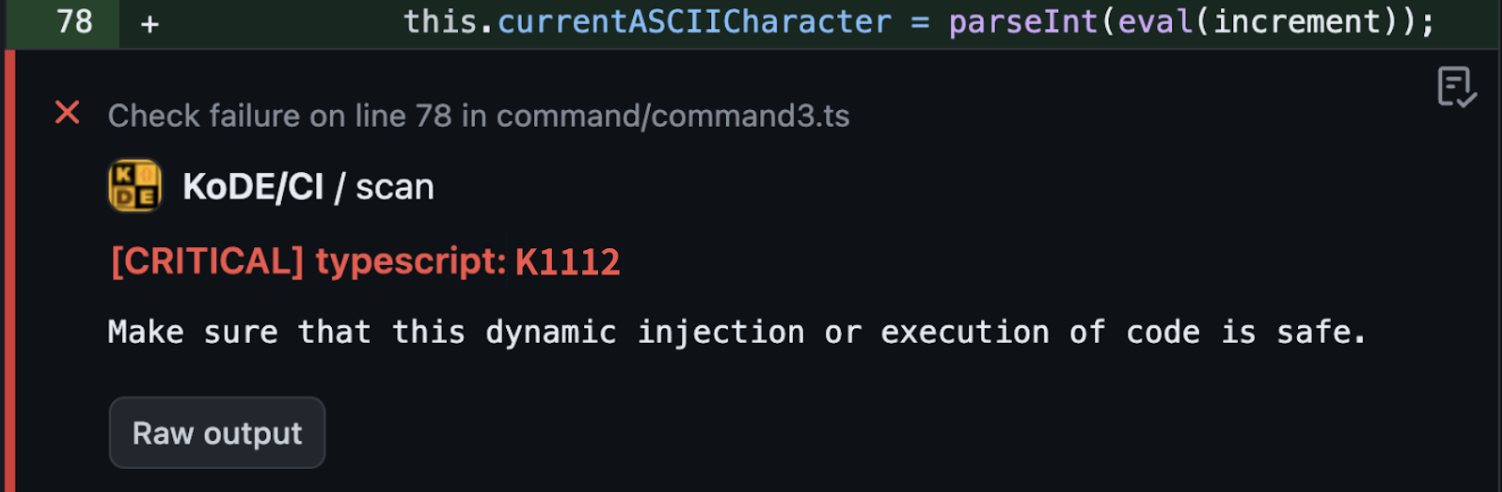
하지만 문제는 현실의 코드가 훨씬 복잡하다는 데 있습니다. 입력값을 다른 함수에서 검증했거나, 특정 프레임워크가 내부적으로 방어 로직을 가지고 있는 경우에도 정적 분석은 ‘일단 의심’하고 경고를 보내는 경우가 많습니다. 결국 개발자는 수많은 가짜 경고 속에서 진짜 위협을 놓칠 수 있게 됩니다.
3. AI가 보안 취약점을 바라보는 시각
AI 모델은 단순한 문자열 패턴 매칭을 넘어, 코드의 전체적인 구조와 흐름 속에서 위협을 해석하고 판단합니다. 예를 들어
@app.route("/search")
def search():
keyword = request.args.get("q")
return f"<div>Results for {keyword}</div>"
위의 코드 경우 GPT 기반 AI는 다음과 같은 리뷰 코멘트를 생성할 수 있습니다.
[AI Review] 사용자 입력값 ‘keyword’가 HTML로 직접 렌더링되는데 사용되고 있습니다. → XSS(Cross-site Scripting) 공격 가능성이 있습니다. → escape(), sanitize() 또는 템플릿 엔진 사용을 권장합니다.
AI는 이 코드가 웹 라우팅 컨텍스트 내에서 동작하고, HTML 문자열에 사용자 입력이 삽입되었음을 인지해, 단순 문자열 삽입이 아닌 XSS 가능성을 파악할 수 있습니다.
4. 복합 패턴 탐지를 위한 AI + 룰 기반 정적 분석 도구 결합
AI 기반 리뷰 시스템은 룰 기반 정적 분석도구와 다음과 같은 방식으로 보완적 관계를 형성할 수 있습니다.
| 기능 | 정적 분석 | AI 리뷰 |
|---|---|---|
| 빠르고 정형화된 룰 탐지 | ✅ 강점 | ⚠️ 한계 있음 |
| 컨텍스트 기반 이해 | ❌ 부족 | ✅ 강점 |
| 리팩토링 제안 | 제한적 (예: use try-with-resources) | 자연어 기반 리팩토링 권장 |
| 사용자 피드백 기반 학습 | ❌ 없음 | ✅ 가능 (Few-shot / Fine-tune) |
이러한 하이브리드 분석 시스템은 정적 분석이 놓치는 문맥 기반 보안 결함을 보완하면서, 단순 경고 이상으로 코드를 구체적으로 개선할 수 있도록 리팩토링 제안까지 자동화할 수 있습니다.
실용적인 버그 예측 모델 구축하기
하이브리드 시스템 구성을 위한 AI 기반 리뷰 시스템은 정적 분석의 명백한 룰 기반 탐지를 넘어, 개발팀의 과거 실수를 자산으로 만드는 학습 기반 버그 예측 모델을 구축하여 이를 사용할 수 있어야 합니다. 이 모델은 과거 코드 변경 이력과 실제 버그 데이터를 학습하여, 잠재적인 오류 가능성이 높은 코드 구조를 사전에 경고해 줄 수 있습니다.
1. 데이터 구성: ‘진짜’ 버그 이력 추출하기
버그 예측 모델의 성능은 학습 데이터의 질에 달려있습니다. 보통 다음 두 데이터를 사용합니다.
- 정상 커밋: 일반 기능 추가/리팩토링 등
- 버그 수정 커밋: 이슈 트래커와 연동된 ‘fix’, ‘bug’ 등의 키워드가 포함된 커밋
여기서 가장 큰 허들이 발생합니다. 실무에서는 ‘fix’ 키워드가 버그 수정이 아닌 단순 오타 수정이나 설정 변경에 사용되는 경우가 많아 노이즈가 심합니다. 따라서 커밋 메시지뿐만 아니라, Jira 티켓의 ‘Bug’ 레이블과 커밋을 연동시키는 등, 데이터를 정제하는 과정이 모델 성능에 결정적인 영향을 미칩니다. 또한 정적 분석 도구로부터 검출된 이슈를 수정한 커밋 데이터 역시 모델의 성능 개선에 큰 영향을 미칠 수 있는 중요한 데이터입니다.
버그 수정 커밋에 대한 간단한 예시를 보겠습니다.
- if (user != null && user.getName().equals("admin")) {
+ if (user != null && user.getName() != null && user.getName().equals("admin")) {
이 변경은 NullPointerException 회피 목적의 수정이며, 이를 통해 다음과 같은 레이블을 부여할 수 있습니다.
{
"before_code": "if (user != null && user.getName().equals(\"admin\"))",
"after_code": "if (user != null && user.getName() != null && user.getName().equals(\"admin\"))",
"bug_type": "NullDereference"
}
이러한 변경 수천~수십만 건을 수집하여 학습 데이터셋을 구성합니다. 공개 데이터로는 Defects4J, CVEfixes 등이 있어 이를 충분히 활용할 수 있으며, 가장 좋은 것은 팀의 코드 베이스와 개발 문화가 담긴 자체 데이터셋입니다.
2. 모델 구성: 현실적인 선택과 트레이드오프
버그 예측 모델은 크게 두 가지 방식으로 나뉩니다. 각각 장단점이 명확하므로, 팀의 현재 기술 스택과 목표에 맞춰 선택해야 합니다.
(1) ML 기반 분류 모델: 작고 빠르게 시작하기
- 특징을 수치로 변환(예: 코드 복잡도, API 호출 빈도 등) 후 RandomForest, XGBoost 등으로 분류합니다.
- 장점: 모델이 가볍고, 해석이 비교적 용이하며, 기존 데이터 분석가들이 다루기 쉽습니다.
- 단점: 어떤 피처가 버그와 연관이 있을지 정의하는 ‘피처 엔지니어링’ 과정이 매우 어렵고, 많은 시간과 노력이 필요합니다. 코드의 미묘한 문맥을 반영하기 어렵다는 한계도 명확합니다.
(2) LLM 기반 패턴 유사도 모델: 높은 정확도를 목표로
- CodeBERT/GPT와 같은 사전학습된 LLM이나 오픈소스 모델을 코드에 직접 적용하여 위험도를 판단합니다.
- 장점: 피처 엔지니어링 없이 코드의 문맥과 의미 자체를 이해하므로, 전통적인 ML 모델보다 훨씬 높은 정확도를 보일 잠재력이 있습니다.
- 단점: 모델 운영을 위한 고사양 인프라(GPU) 비용이 부담될 수 있습니다. 또한, 코드베이스에 특화된 버그 패턴을 학습시키기 위한 파인튜닝은 상당한 전문성을 요구합니다. 초기에는 파인튜닝 대신, 유사 버그 사례를 검색해주는 RAG(Retrieval-Augmented Generation) 방식이 더 현실적인 대안이 될 수 있습니다.
3. 위험도 판단과 ‘실용적인’ 리뷰 연동
모델의 예측 결과는 개발자가 ‘신뢰하고 행동할 수 있도록’ 제공되어야 합니다.
{
"function": "validateUser",
"risk_score": 0.91,
"matched_bug_type": "NullDereference",
"suggestion": "user.getName() 호출 전 null 확인이 필요합니다. 과거 유사 버그(Kakoa-BugFix/6824)를 참고하세요.",
"business_impact": "High (로그인 실패 및 사용자 경험 저하 유발 가능)",
"owner": "@kakao-team/service/shopping"
}
단순히 위험 점수를 보여주는 것을 넘어, 유사한 과거 버그 티켓을 링크해주거나, 이 버그가 비즈니스에 미칠 수 있는 영향을 함께 명시할 때 개발자는 경고를 더 심각하게 받아들이고 즉각적인 조치를 취하게 됩니다.
설정 오류 탐지 및 장애 유발 가능성 예측
현대의 애플리케이션은 단순한 코드 외에도 수많은 설정(configuration) 값에 의해 동작이 결정됩니다. Spring Boot의 application.yml, Docker의 docker-compose.yml, Kubernetes의 deployment.yaml, Python의 .env 파일 등은 실행 환경, 보안 정책, 외부 연동 조건을 지정하는 핵심 구성 요소입니다.
이러한 설정 파일은 다음과 같은 특성을 가집니다.
- 코드와 달리 컴파일러나 IDE가 검증하지 않음
- 런타임 이후에야 오류가 드러남
- 장애 발생 원인 중 높은 비율을 차지
따라서 설정 파일에 대한 정적 분석과 AI 기반 이상 탐지 모델이 결합되면, 사전 위험 예측의 정확도를 크게 향상시킬 수 있습니다.
1. 설정 오류의 일반 유형
설정 파일 오류는 보통 다음 네 가지 범주로 나뉩니다.
| 유형 | 설명 | 예시 |
|---|---|---|
| 누락(Missing) | 필수 키나 값이 없음 | spring.datasource.url 누락 |
| 오타(Typo) | 존재하지 않는 키 사용 | servlet.seession.timeout (오타) |
| 범위 오류(Range Violation) | 값이 허용 범위를 초과 | maxConnections: -1 |
| 상호 충돌(Inconsistency) | 두 항목이 논리적으로 충돌 | tls: enabled + port: 80 |
이러한 오류는 대부분 배포 이후에 장애로 나타나는 경우가 많기 때문에, 리뷰 단계 또는 빌드 시점에 탐지하는 것이 매우 중요합니다.
다음은 고위험 설정 옵션에 대한 예시 목록입니다.
| 범주 | 설정 키 (예시) | 설명 | 잘못된 값 예 | 위험 요인 |
|---|---|---|---|---|
| 네트워크 연결 | connectTimeout, socketTimeout, readTimeout | 외부 서비스/API 연결 대기 시간 | 너무 짧은 값 (ex. 100ms) | 네트워크 지연 감당 불가 → 실패 연속 발생 |
| 스레드/풀 관리 | maxThreads, minSpareThreads, corePoolSize, queueSize | 요청을 처리할 쓰레드 수/큐 용량 | 과도한 값 (ex. 1000 이상) 너무 작은 값 (ex. 1) |
과부하로 인한 thread starvation 또는 OOM |
| 데이터베이스/캐시 연결 | maxPoolSize, connectionTimeout, idleTimeout | DB 커넥션 풀 크기, 대기 시간 | 설정 미달 or 과대 (ex. 풀=5, 타임아웃=10ms) | 커넥션 고갈, timeout 누적 장애 |
| GC/메모리 설정 | Xmx, Xms, newSize, GC type | JVM 메모리, GC 방식 | 적은 heap, GC 불균형 | 잦은 Full GC → 응답 시간 급증 |
| API 보안 설정 | allowCredentials, cors.allowedOrigins, csrf.enabled | API 인증/권한/보안 설정 | * 또는 disabled | 인증 우회, CORS 우회, 보안 허점 |
2. 정적 분석 도구를 통한 구성 오류 탐지
정적 분석 도구나 스키마 검증 도구는 다음과 같은 방식으로 설정 오류를 식별할 수 있습니다.
- YAML/JSON Schema 기반 키 유효성 검사
- 필수 값 누락 검사 (required)
- 정규식 기반 허용값 검사 (pattern, enum)
- 상호 의존 필드 논리 검사 (e.g. A가 true일 때 B는 필수)
[예제: application.yml 스키마 검증]
spring:
datasource:
url: jdbc:mysql://localhost:3306/db
username: admin
password: admin123
→ spring 기반 application yml 스키마 정의:
{
"spring.datasource.url": { "type": "string", "required": true, "pattern": "^jdbc:" },
"spring.datasource.username": { "type": "string", "required": true },
"spring.datasource.password": { "type": "string", "required": true }
}
이 스키마를 기반으로 검증하면 URL 값 누락, 타입 오류, 형식 오류 등을 사전에 탐지할 수 있습니다.
3. AI 모델을 활용한 구성 오류 탐지
정적 분석이 탐지하지 못하는 문맥 기반 위험은 AI 기반 분석을 통해 보완할 수 있습니다. 특히, 기존에 보안 취약점 탐지를 목적으로 학습된 버그 예측 모델을 활용하면, 구성 파일 내 요소 간의 의미적 불일치나 잘못된 조합을 실시간으로 탐지할 수 있습니다. 이 모델은 구성 항목 간 상관성을 분석하여 잠재적인 설정 오류나 충돌 가능성을 사전에 식별하며, 다음과 같은 방식으로 개발자에게 실시간 피드백을 제공할 수 있습니다.
- 설정 간 논리적 충돌 탐지
- 누락된 필수 항목 또는 비권장 조합 경고
- 과거 유사 구성 오류와의 유사도 기반 리스크 평가
이와 같은 방식은 단순 규칙 기반 접근을 넘어, 의미 기반의 구성 오류 탐지 및 피드백 제공 체계를 구축할 수 있는 기반이 됩니다.
[예제: 리뷰 시점에서의 위험 피드백 생성 예시 (application deployment script 중)]
env:
- name: JAVA_TOOL_OPTIONS
value: >
-Dsun.net.inetaddr.ttl=0
-javaagent:/share-vol/apm/apm.agent.jar
-Dapm_application_key=$(APM_APPLICATION_KEY) <- 실수로 삭제가 되었다면
-Dapm_collector_address=$(APM_COLLECTOR_ADDRESS)
-XX:InitialRAMPercentage=60.0
-> GPT 기반 모델 분석 결과

4. 정적 분석 + AI 하이브리드 구성 전략
정적 분석과 AI 분석을 결합하면 상호 보완적이며 강력한 구성 오류 탐지 시스템을 만들 수 있습니다.
| 기능 | 정적 분석 | AI 기반 분석 |
|---|---|---|
| 키/타입 오류 | ✅ 강함 | ❌ 미지원 |
| 조합 논리 오류 | ❌ 불가능 | ✅ 가능 |
| 과거 장애 맥락 기반 경고 | ❌ 없음 | ✅ 학습 가능 |
| 커스터마이징 유연성 | 제한적 (Schema 기반) | 높음 (사내 데이터 기반 학습 가능) |
통합 예시:
- CI 단계에서 schema-check 먼저 수행 → YAML 오류 필터링
- 이후 AI 모델에게 변경된 설정 diff 전달 → 위험도 추정 + 리뷰 코멘트 생성
- Risk Score ≥ 임계값일 경우 PR 코멘트 등록 또는 배포 차단 트리거 연동 가능
이 하이브리드 구조는 명백한 오류는 빠르게 차단, 복잡하거나 문맥 의존적인 문제는 AI가 보완하는 강력한 품질 방어선 역할을 충분히 할 수 있을 것입니다.
AI 기반 리뷰 시스템은 독립적으로 운영되기보다는, 기존의 정적 분석 도구와 함께 구성되어 보완적 역할을 수행하는 것이 일반적입니다. SonarQube, Semgrep, SpotBugs 같은 오픈소스 분석기는 이미 수많은 조직에서 정량적 품질 관리의 핵심으로 자리잡고 있으며, 카카오는 SCAN이라는 코드 정적 분석 도구와 함께 AI 모델을 이용한 분석 도구와 연계하여 정확성, 설명력, 확장성 면에서 시너지를 낼 수 있도록 구성하고 있습니다.
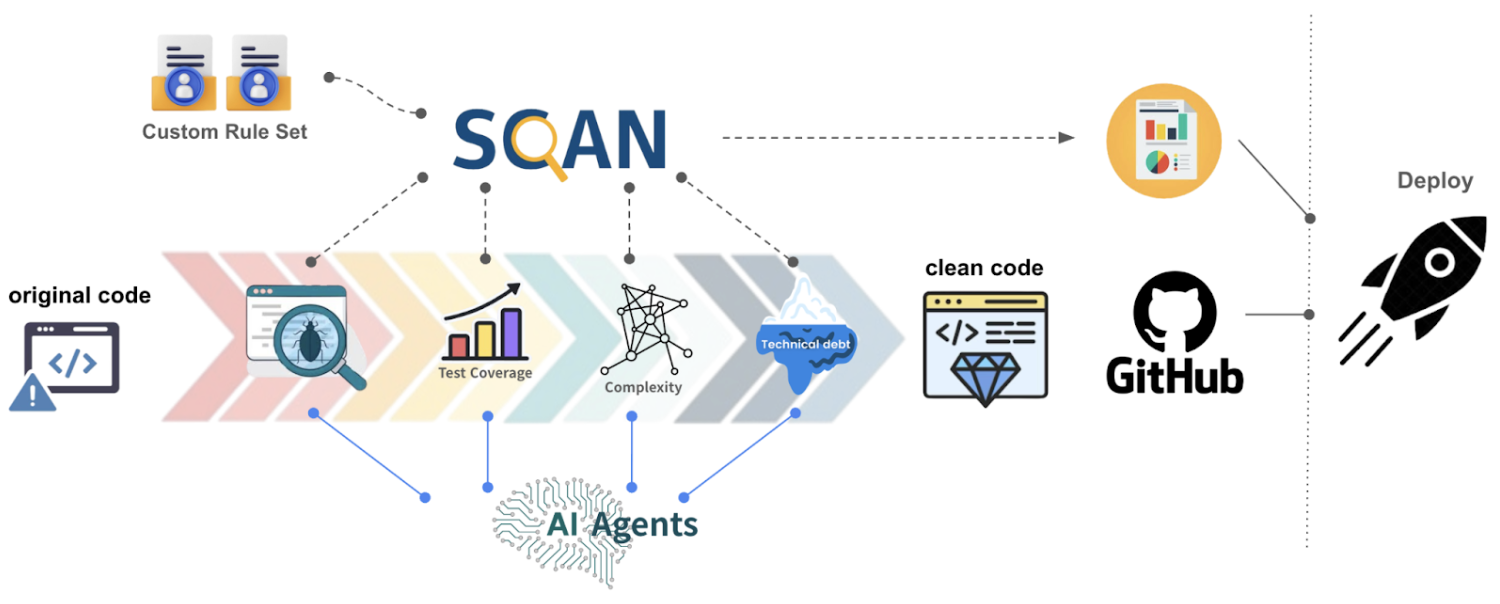
단위 테스트 자동 생성을 통한 코드 품질 향상
단위 테스트는 코드 품질을 유지하고 회귀 오류를 방지하기 위한 핵심 수단입니다. 하지만 현실적으로 단위 테스트는 작성이 어렵고, 시간이 오래 걸리며, 작성자의 역량과 시간 제약에 따라 누락되기 쉽습니다.
이러한 한계를 극복하기 위해 최근에는 LLM 기반의 테스트 코드 자동 생성 기술이 급속도로 도입되고 있으며, 이는 코드 커버리지를 향상시키고 개발자의 생산성과 품질을 동시에 높이는 새로운 접근으로 주목받고 있습니다.
LLM은 코드의 문맥과 제어 흐름을 이해하고, 적절한 테스트 케이스를 생성할 수 있는 능력을 갖추고 있습니다. 기본적인 동작 흐름은 다음과 같습니다.
- 분석 대상 메소드의 시그니처 및 본문 파싱
- 입력 타입, 조건 분기, 예외 흐름 등을 기반으로 테스트 시나리오 도출
- 테스트 프레임워크(JUnit 등)에 맞는 템플릿에 삽입
- 가상(Mock) 객체, 어서션(Assertion), 경계값 등을 자동 구성
[예제: 대상 코드]
public class Calculator {
public int divide(int a, int b) {
if (b == 0) throw new IllegalArgumentException("Division by zero");
return a / b;
}
}
[GPT 기반 자동 생성 테스트 예시 (JUnit 5)]
@Test
void testDivide_ValidInputs() {
Calculator calc = new Calculator();
assertEquals(2, calc.divide(4, 2));
}
@Test
void testDivide_DivideByZero() {
Calculator calc = new Calculator();
assertThrows(IllegalArgumentException.class, () -> calc.divide(4, 0));
}
이처럼 LLM은 코드의 의미를 파악해 정상 케이스와 예외 케이스에 대한 테스트를 자동으로 생성할 수 있습니다.
자동 테스트 생성을 위해 AI는 다음과 같은 코드 요소를 분석합니다.
| 요소 | 역할 | 예시 |
|---|---|---|
| 파라미터 타입 | 입력 값의 유효 범위 추정 | int, String, List<?> |
| 조건문 (if, switch) | 경계 조건별 테스트 분기 생성 | if (x > 100) → x=99, x=100, x=101 |
| 예외 처리 | 실패 케이스 유도 | throw new IllegalArgumentException(…) |
| 의존성 주입 | 가상(Mock) 객체 생성 여부 판단 | UserService userService = … |
이러한 정보를 종합해 GPT등의 모델들은 단순 단일 테스트 시나리오가 아닌 여러 테스트 시나리오를 자동 구성할 수 있습니다.
단위 테스트 품질 향상을 위한 AI 전략
AI는 단위 테스트 코드를 자동 생성할 수 있지만, 기계적으로 생성된 테스트 코드가 실무에서 곧바로 실행 가능하고 의미 있는 품질을 보장하지는 않습니다.
따라서 다음과 같은 전략적 요소를 활용하면 생성된 테스트 코드의 실용성과 신뢰성을 대폭 높일 수 있습니다.
1. 의존성 분석을 통한 의존 클래스 코드 활용
AI가 테스트 대상을 분석할 때, 해당 클래스가 내부적으로 호출하거나 사용하는 의존 클래스를 자동으로 식별하고, 이를 함께 테스트에 포함시키는 능력은 생성된 테스트 코드의 품질을 높이는데 큰 역할을 합니다.
예를 들어 다음과 같은 코드가 있습니다.
public class UserService {
private final UserRepository repository;
public UserService(UserRepository repository) {
this.repository = repository;
}
public User findUser(long id) {
return repository.findById(id).orElseThrow(() -> new NotFoundException());
}
}
AI는 단순히 UserService만 테스트하는 것이 아니라, 아래와 같이 UserRepository를 분석하여 적절한 가상(Mock) 동작을 구성해야 합니다.
@Test
void testFindUser_Found() {
UserRepository repo = mock(UserRepository.class);
User user = new User(1L, "test");
when(repo.findById(1L)).thenReturn(Optional.of(user));
UserService service = new UserService(repo);
User result = service.findUser(1L);
assertEquals("test", result.getName());
}
이처럼 의존성 분석은 정확한 컨텍스트 모킹(Context Mocking)¹을 가능하게 하며, 불필요한 NPE 회피 코드 생성을 줄이고, 진짜 의미 있는 테스트 흐름을 만들 수 있게 함에 필수적입니다.
2. Java 컴파일러를 통한 단위 테스트 유효성 자동 체크
AI가 생성한 테스트는 문법적으로는 그럴듯해 보여도, 컴파일 시 오류가 나는 경우가 빈번히 발생합니다. 예를 들어:
- 테스트 클래스 내부에 import 누락
- private 메소드 호출
- 없는 필드나 메소드 호출
이러한 문제를 사전에 방지하기 위해, 생성된 테스트 코드는 Java Compiler API 또는 javac로 사전 컴파일 시도 후, 실패 시 AI에게 오류 내용을 재피드백하는 구조가 반드시 필요합니다.
3. JUnit Runner를 통한 단위 테스트 실행 검증
테스트는 코드만으로는 그 가치에 큰 의미가 없습니다. 실제로 성공/실패를 구분하고 의미 있는 결과를 내야 그 가치가 스스로 입증되고 제품의 품질을 증진시킬 수 있다고 할 수 있습니다.
이를 위해 AI를 통해 생성된 테스트는 자동으로 JUnit Runner를 통해 실행되어야 하며, 다음과 같은 방식으로 결과를 도출하고 실패 시 AI를 통하여 분석하고 그 결과를 반영하여 다시 테스트 코드를 생성할 수 있는 자동화된 피드백 루프 형태를 구성해야 합니다.
[예시: 카카오 테스트 생성 Agent가 수행한 생성된 테스트 코드의 JUnit Runner를 통한 실행 결과]
{
"status": "FAILED",
"summary": "5 tests found.\n4 tests successful.\n1 tests failed.\n",
"errorLog": "\nFailures (1):\n testAverageWithSingleElementArray()\n MethodSource [className = 'com.kakao.quality.sample.AverageCalculatorTest', methodName = 'testAverageWithSingleElementArray', methodParameterTypes = '']\n => org.opentest4j.AssertionFailedError: expected: <-3.3> but was: <-3.0> [...]\n",
"failedTestMethodList": [
{
"className": "com.kakao.quality.sample.AverageCalculatorTest",
"methodName": "testAverageWithSingleElementArray",
"failedMessage": "expected: <-3.3> but was: <-3.0>"
}
],
"passedTestMethodList": [
{
"className": "com.kakao.quality.sample.AverageCalculatorTest",
"methodName": "testAverageWithMixedNumbers"
},
[...]
]
}
실패 로그와 함께 실패 및 성공 메소드를 정확하게 분리 관리하고, 실패 로그를 재분석하여 AI를 통하여 생성된 테스트 코드가 정상적으로 수행될 수 있도록 수정할 수 있어야 합니다.
{
"AiMessage": {
"text": "(1) `testAverageWithSingleElementArray`\n*
Cause: The failure log likely indicates a mismatch between the expected and actual output for the test case `assertEquals(-3.3, calculator.average(new int[]{-3, -3, -3}), 0.001);`. The test is incorrectly written because it is trying to test the average of an array with identical elements, and the expected value set in the test is incorrect. The expected average of the array `{-3, -3, -3}` should be `-3.0`, as all elements are `-3`, and the average would also be `-3.0`, not `-3.3`.\n\n*
How to fix: Correct the expected value in the `testAverageWithSingleElementArray` method for the test case involving an array with the elements `{-3, -3, -3}`. Change the expected value from `-3.3` to `-3.0`.\n\nHere's the corrected test method:\n\n```java\n@Test\npublic void testAverageWithSingleElementArray() {\n [...]"
}
}
4. JaCoCo 모듈을 이용한 커버리지 측정 및 증분 평가
AI가 테스트 코드를 생성했을 때, 가장 신뢰할 수 있는 품질 지표 중 하나는 바로 코드 커버리지 증가량입니다.
이를 위해 JaCoCo²와 같은 커버리지 측정 도구를 테스트 실행 후 연동하여 실제 커버리지를 수치화합니다.
[예시: 카카오 테스트 생성 Agent가 수행한 커버리지 변동 결과]
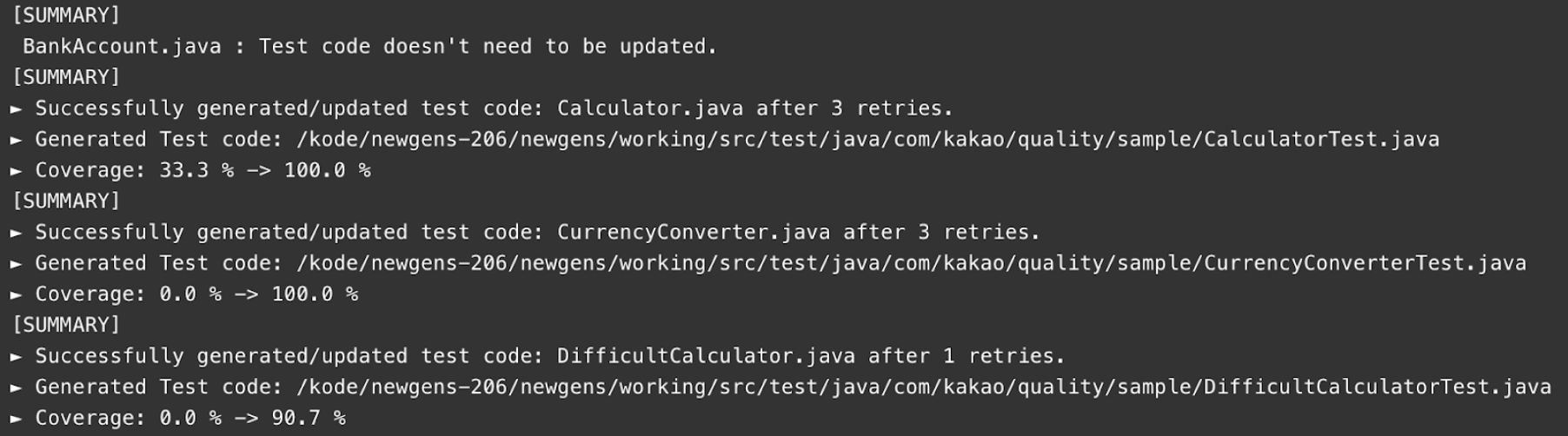
커버리지 증가는 단순히 테스트가 “존재한다”라는 사실을 넘어서, 기존 커버리지 맹점(blind spot)을 메웠는가에 대한 실질적 근거가 됩니다. 또한 이 결과는 코드 리뷰 시 자동 배지로 PR에 등록되어 품질 가시성을 높일 수 있습니다.
5. Jaro-Winkler / Levenshtein 기반 유사 코드 활용
AI가 이전에 생성한 테스트 코드나 프로젝트 내 유사한 테스트 클래스를 분석하여, 기존 테스트 흐름과 유사한 구조/경로/패턴을 재사용하면 생성되는 테스트 코드의 품질을 높일 수 있습니다.
이를 위해 Jaro-Winkler, Levenshtein 등 문자열 거리 알고리즘을 사용해 다음을 자동 분석할 수 있습니다.
| 기준 | 활용 |
|---|---|
| 클래스명 유사도 | OrderService, OrderHandler, OrderManager → 공통 유닛 검출 |
| 클래스명 역순 유사도 | OrderService, MemberService, AccountService → 유사 패턴 로직 검출 |
| 기존 테스트와의 유사도 | OrderServiceTest.testCalculateTotal() 구조 복제 가능성 판단 |
[예시 코드 (Levenshtein Distance)]
LevenshteinDistance levenshtein = new LevenshteinDistance(threshold)
int distance = levenshtein.apply(aClass.getCode(), bClass.getCode());
이 방식은 테스트 생성의 일관성 유지, 중복 피드백 방지, 패턴 기반 최적화에 기여하며 프로젝트 내의 기존 테스트 자산을 기반으로 일관된 코드 컨벤션을 지키며 품질 높은 테스트 생성을 가능하게 만듭니다.
실시간 코드 리뷰와 테스트 자동 생성 연계
단위 테스트 자동 생성은 단순 IDE 내 도구로 끝나지 않고, 코드 리뷰 또는 PR 시점과 실시간으로 연동될 때 큰 효과를 발휘합니다.
다음은 실시간 코드 리뷰와 연계된 테스트 자동 생성에 대한 추천 워크플로입니다.
- PR 생성 → 변경된 클래스 감지
- 자동으로 테스트 생성 요청
- 생성된 테스트 코드는 PR에 자동 커밋 또는 주석 코멘트로 제안
- 테스트 커버리지 배지 갱신 (JaCoCo 연동)
[예시: 카카오 테스트 생성 Agent가 수행한 PR 리뷰 코멘트]
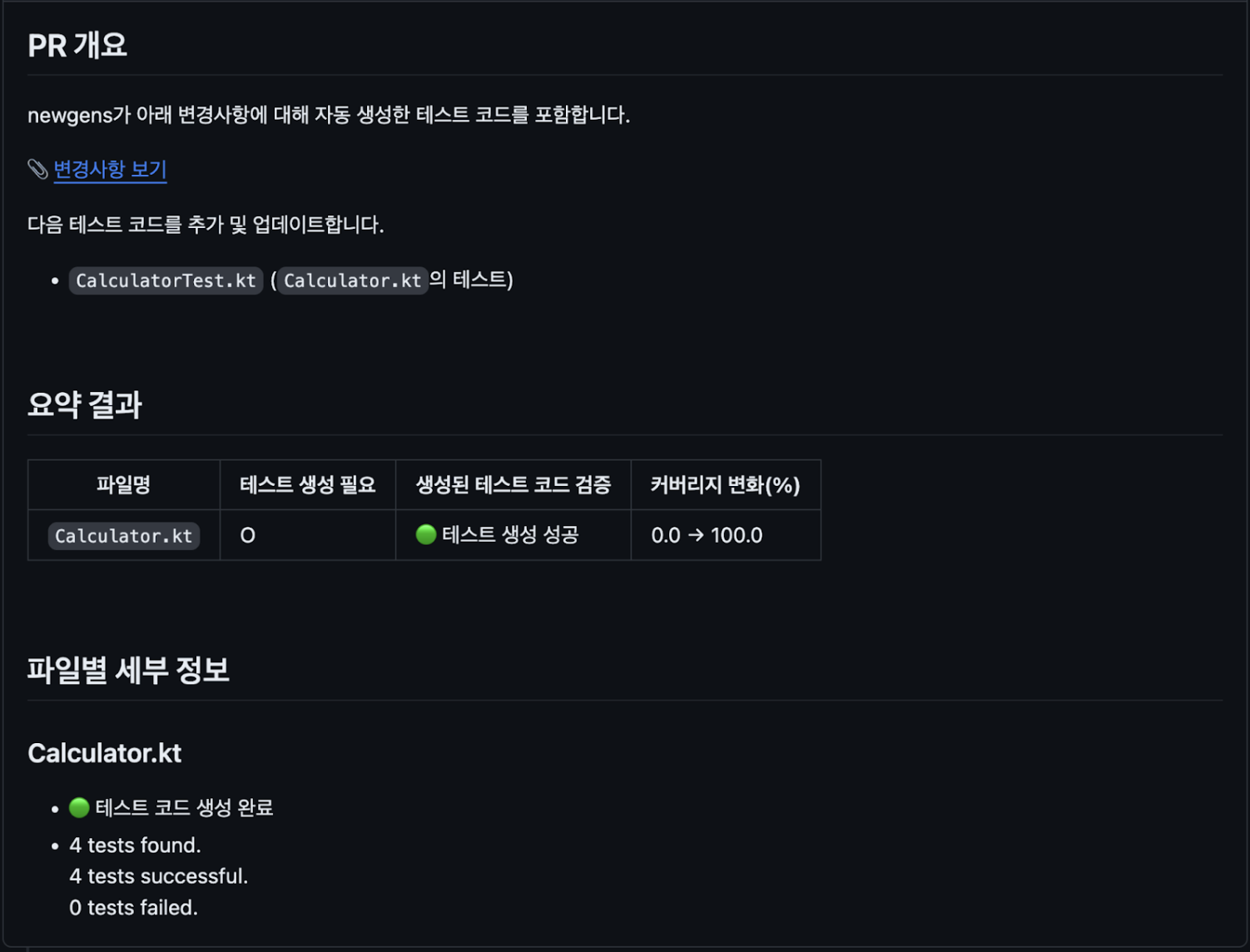
위 설명처럼 AI가 생성한 테스트 코드를 품질 있는 자산으로 만들기 위해서는 다음 전략이 중요합니다.
- 의존성 분석을 통한 정확한 가상(Mock) 클래스코드 구성
- 컴파일러 기반 유효성 확인으로 실패 방지
- JUnit 실행 기반 테스트 실효성 확보
- JaCoCo 커버리지 측정을 통한 성과 수치화
- 유사도 기반 재사용 전략으로 테스트 품질·일관성 확보
이 모든 요소가 결합되면, AI 기반 테스트 생성은 단순 자동화를 넘어, 신뢰 가능한 QA 프로세스의 일부로 통합될 수 있습니다.
자동화 파이프라인을 통한 품질 관리
앞서 다룬 AI 리뷰, 정적 분석, 테스트 자동 생성 기술은 실시간 코드 품질 관리를 가능하게 만들었지만, 이는 시작에 불과합니다.
이제는 각 기술 요소를 단절된 기능이 아닌 유기적인 흐름으로 엮어내는 자동화 파이프라인이 필요합니다.
에이전틱 워크플로 기반의 리뷰 및 품질 관리
에이전틱 워크플로(Agentic Workflow)는 각 품질 관리 단계에 맞는 전문 에이전트들이 자율적으로 판단하고 협력하면서 전체 리뷰 프로세스를 수행하는 아키텍처입니다.
다음은 카카오의 코드 퀄리티 통합 에이전트에 대한 에이전틱 워크플로 구성 예시입니다.
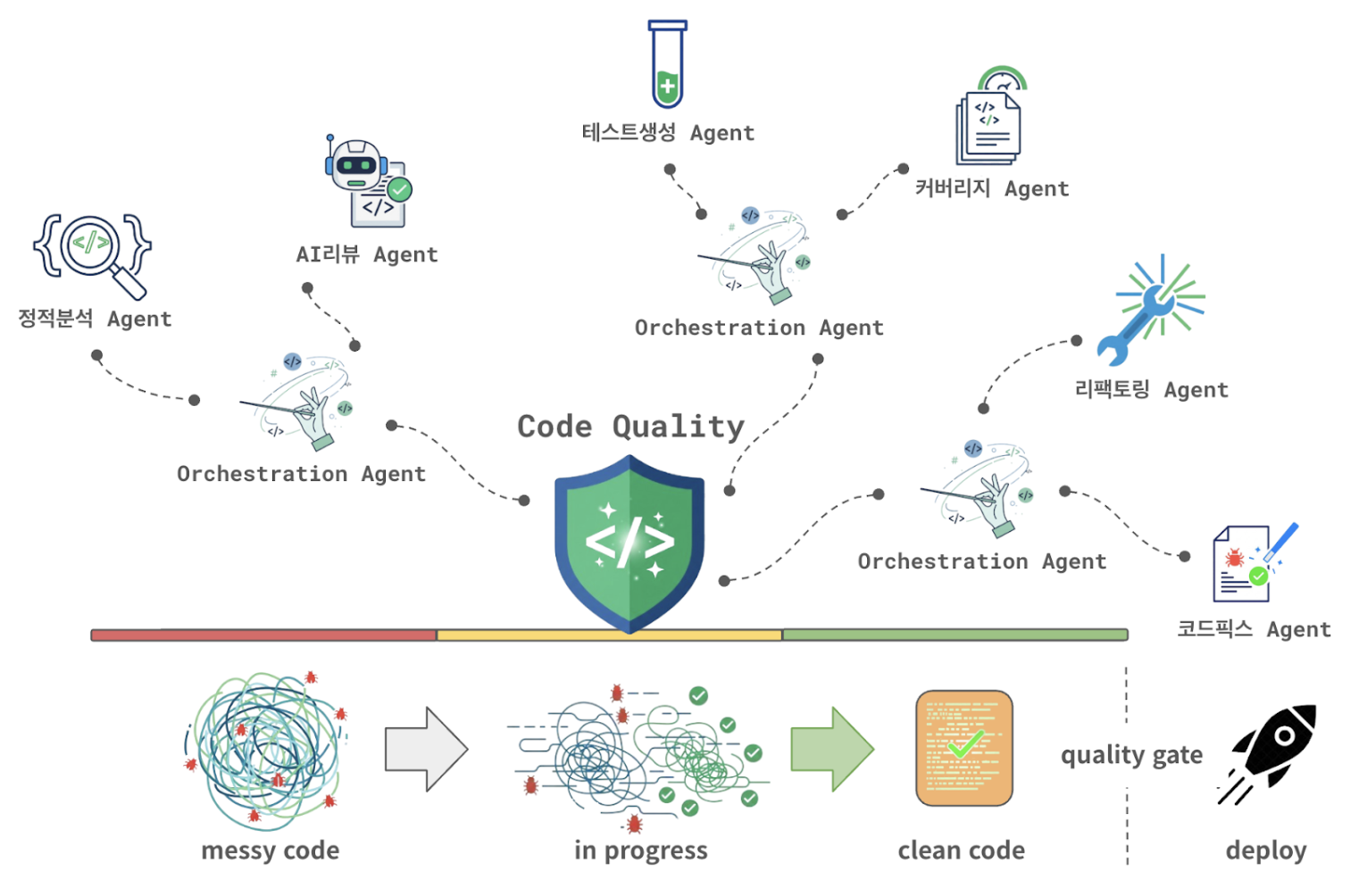
코드 변경의 감지를 시작으로 코드 퀄리티 통합 에이전트는 여러 지능형 에이전트와 연계하여 안전한 배포가 이루어 질 수 있도록 동적으로 판단하며 코드를 수정해 나갑니다. 이러한 복잡한 품질 보증 과정을 에이전틱 워크플로로 구성하여 유연하게 자동화할 수 있습니다.
개발 생산성 향상 도구와의 연계 시나리오
에이전틱 워크프로는 코드 품질 자동화에 그치지 않고, Jira, 카카오워크, GitHub 같은 협업 도구와 카카오릴리즈등 배포 관리 도구와 연동해 실제 개발자의 행동을 유도하고 지원할 수 있어야 합니다.
다음은 연계 시나리오 예시입니다.
- PR(Pull Request) 생성 시, 관련 지라 태스크(Jira Task)를 자동 추적
- 카카오워크 에서 AI 리뷰 결과 요약 알림 (위험도 80% 이상인 경우)
- GitHub PR에 테스트 누락 여부 또는 배포 차단 기준 표시
- 테스트 커버리지 낮은 모듈을 Confluence Wiki 문서로 자동 정리
- 카카오릴리즈에 코드품질 점수를 제공하여 배포 관리
각주
1) 컨텍스트 모킹(Context Mocking)은 소프트웨어 테스트 시, 특정 코드나 구성 요소가 의존하는 ‘컨텍스트(환경 또는 상태 정보)’를 실제가 아닌 가상(모의)의 객체로 대체하여 테스트하는 기법입니다.
2) JaCoCo (Java Code Coverage)는 Java 애플리케이션의 코드 커버리지(Code Coverage)를 측정하는 데 사용되는 오픈소스 도구이자 라이브러리를 말합니다.