목차
목차를 생성하는 중...
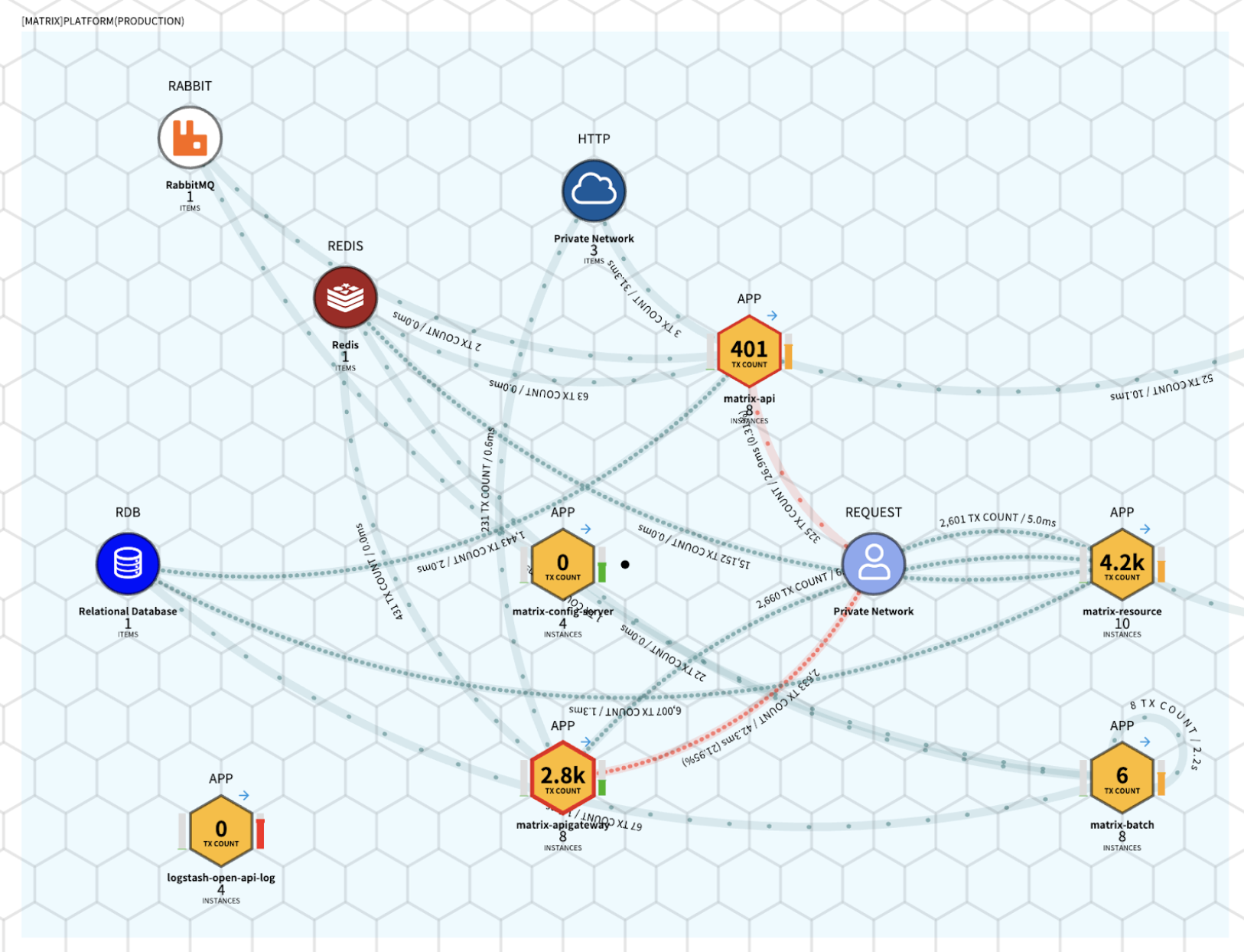
5.2. 분산 추적 기반 AI 운영 생태계
카카오의 여러 서비스, 그 중에서도 카카오톡 서비스는 국민의 대다수가 사용하는 서비스이다보니 인프라와 애플리케이션에 대한 모니터링이 필수적인 과제입니다. 이를 위해 카카오에서는 자체 개발한 매트릭스(MATRIX)라는 솔루션을 운영하고 있습니다.
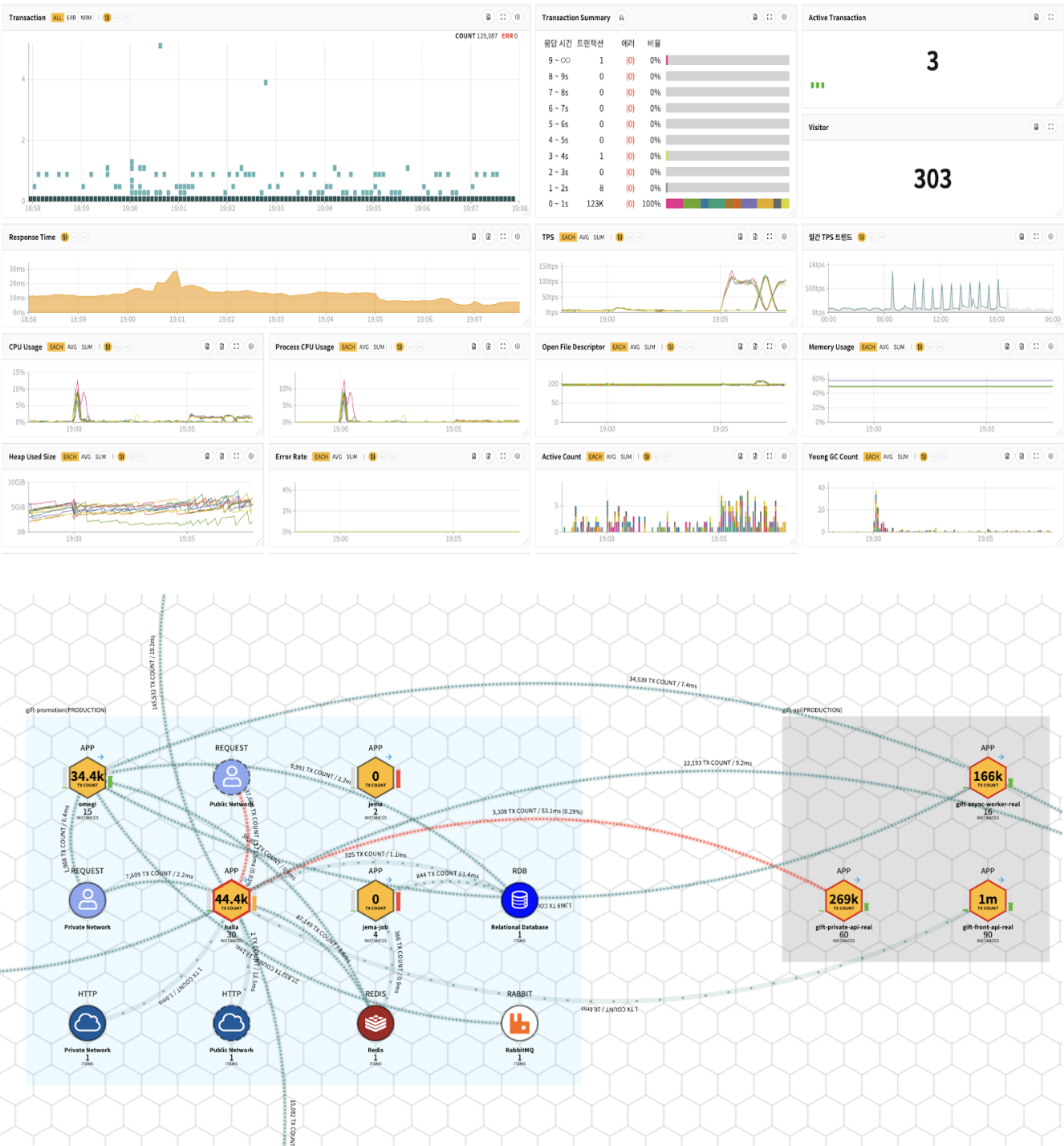
매트릭스(MATRIX)는 As a Service 기반의 모니터링 솔루션으로, 조직·그룹·개인 단위의 권한 관리를 지원하는 멀티 테넌트 서비스입니다.
매트릭스를 통해 서버 및 애플리케이션의 성능, 에러, 로그를 실시간으로 모니터링하고, 서비스 간 연결 관계, 트래픽, 근본 원인 분석 등 다양한 기능을 제공함으로써, 카카오 서비스를 담당하는 개발자와 관리자들이 건강한 서비스를 안정적으로 유지할 수 있도록 지원합니다.
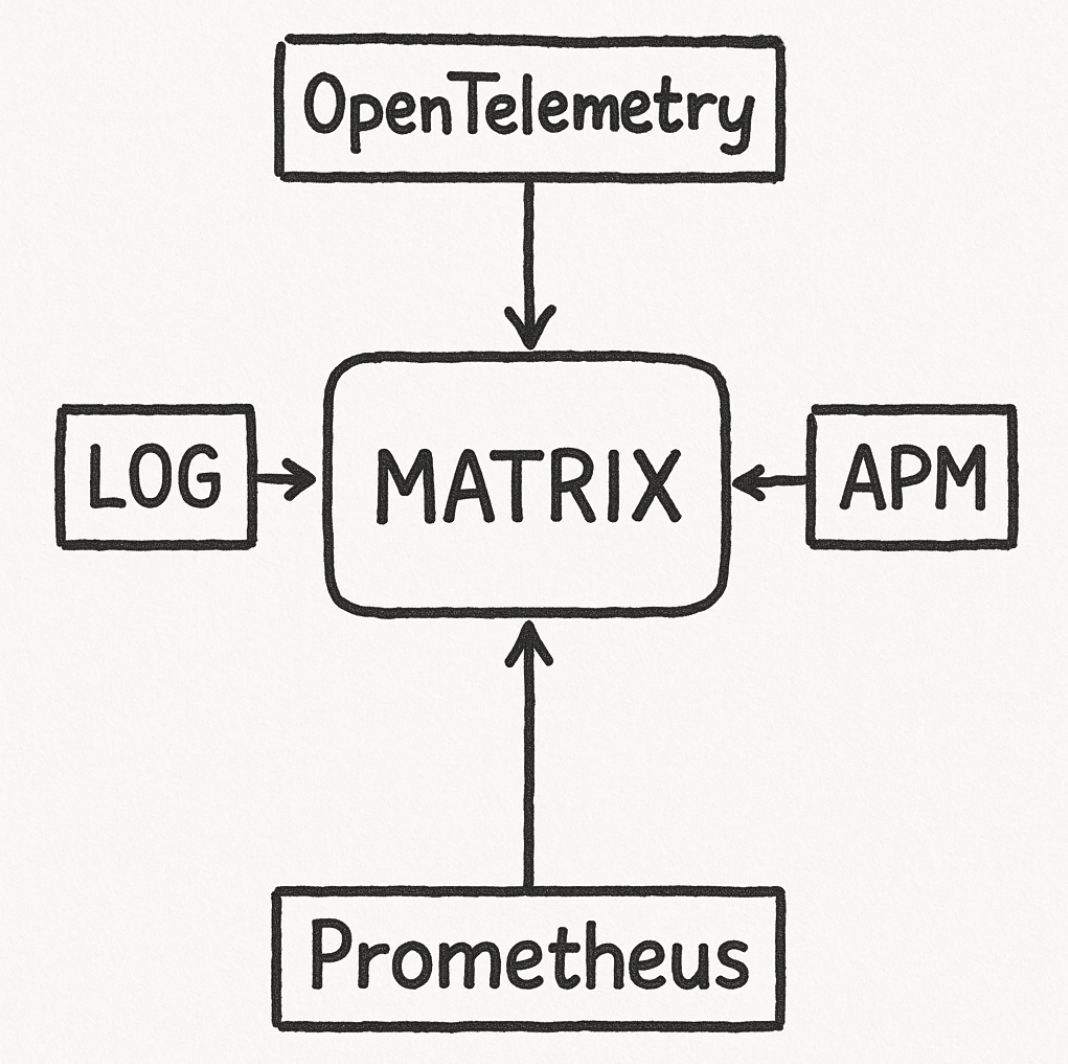
매트릭스 서비스는 OpenTelemetry, APM, 에러 로그 트래킹, Prometheus 등 자체 개발 솔루션과 다양한 오픈소스 기술을 결합해 구현했으며, 카카오 및 카카오의 계열사 서비스 전반의 모니터링을 담당하고 있습니다.
서비스 운영 단계에서 모니터링은 아래 그림과 같은 사이클로 이루어집니다.
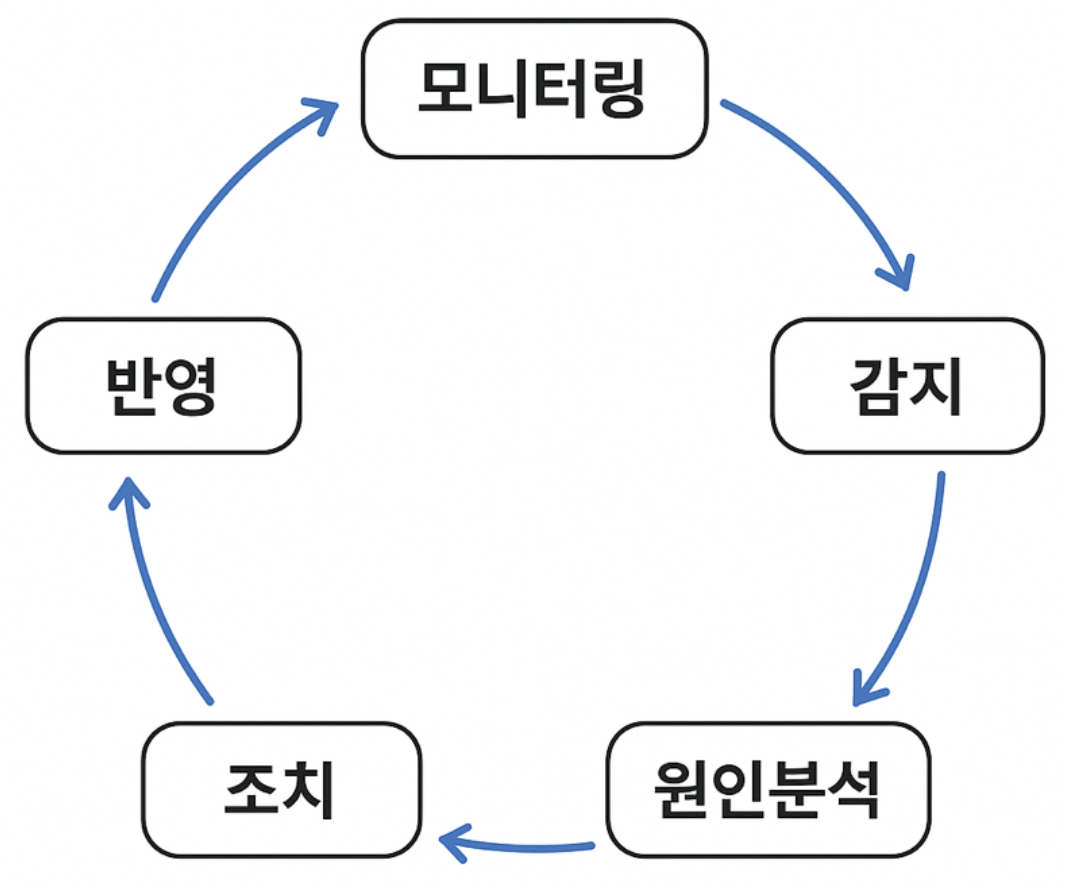
매트릭스는 이 각 단계에서 더욱 빠르고 정확하며, 전문적인 서비스를 제공하기 위해 AI 기술을 적용하기로 했습니다.
이제는 LLM 서비스의 춘추전국시대라 해도 과언이 아닙니다. 초기에는 ChatGPT가 LLM 시장을 선도하며 압도적인 우위를 점하는 듯했지만, 구글, 앤트로픽, 메타 등 다양한 기업들의 LLM 모델 역시 뛰어난 성능을 보여주고 있습니다.
그 결과, 상황과 목적에 따라 가장 적합한 모델을 선택해 사용하는 것이 중요해졌습니다. 매트릭스 AI는 이러한 다양한 LLM 모델들을 연결해주는 교두보 역할을 담당합니다.
매트릭스 내부뿐만 아니라 외부에서도 매트릭스의 AI 기능을 활용하려면 반드시 매트릭스 AI를 통해야 합니다. 이 장에서는 매트릭스 AI가 실제로 구현되었거나, 앞으로 계획 중인 사례들을 소개하고, 이러한 다양한 AI 기능을 어떻게 효율적으로 관리할 수 있는지에 대해 설명합니다.
AI 역할 기반 서비스 제공: 운영의 지능화와 유연성
매트릭스 AI에는 인시던트 관리자, 에러 로그 분석가, 형상 변경 추적자 등 다양한 역할이 필요합니다. 이러한 역할을 담당하기 위해 롤(Role)이라는 도메인을 정의했습니다. 각 롤(Role)은 자신의 역할을 시스템 메시지로 정의하며, 클라이언트는 필요한 롤을 선택한 뒤 사용자 메시지를 추가하여 대화를 이어갈 수 있습니다.
롤은 아래와 같은 주요 속성이 있습니다.
- 코드
- 시스템 메시지
- LLM 체인
- 파라미터
- 응답 포맷(Response Format)
- 요청 제한 간격(Rate Limit Interval)
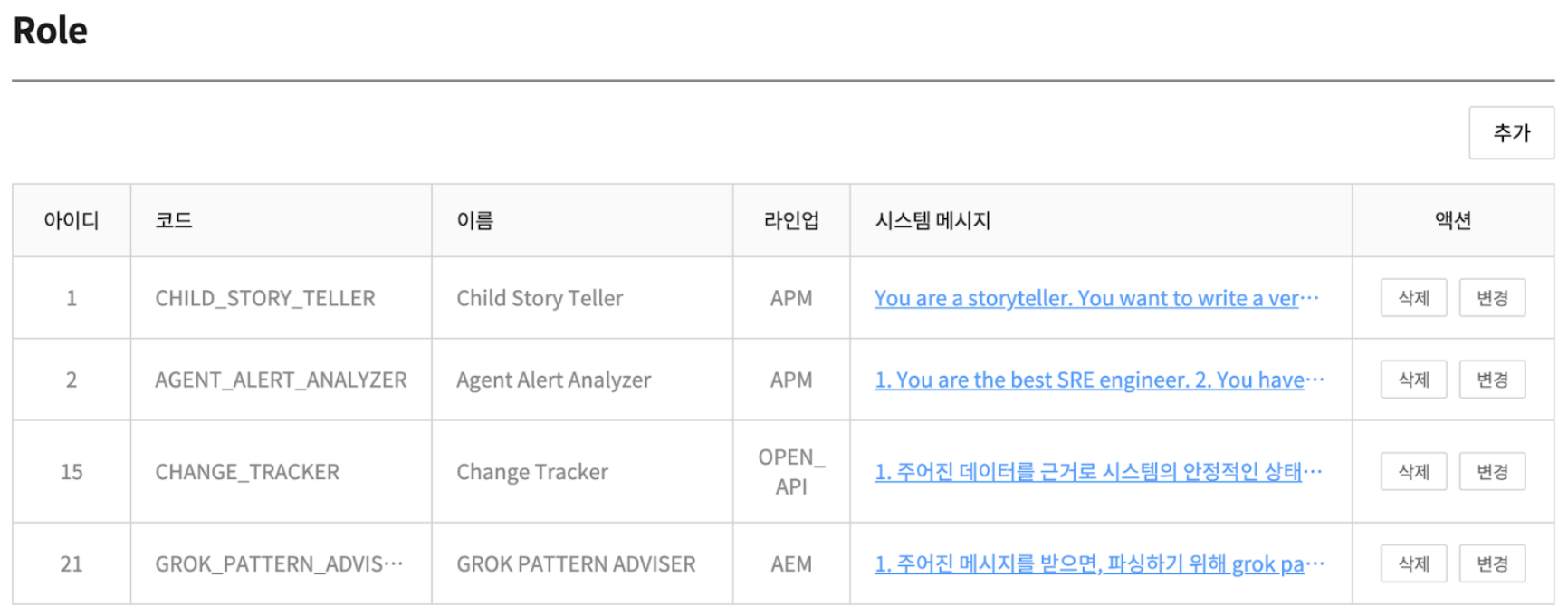
롤은 MATRIX 시스템 어드민 화면을 통해 생성 및 수정될 수 있습니다. 주요 속성 중 몇 가지를 설명해 보겠습니다.
대체 LLM을 설정하는 LLM 체인
매트릭스 AI는 다양한 LLM과 연동될 수 있지만, 모든 LLM 서비스가 항상 안정적으로 제공된다고 보장할 수는 없습니다. 실제로 가장 널리 사용되는 LLM에서도 자주 장애가 발생해 웹 서비스나 API 서비스가 중단되는 경우가 있습니다.
이러한 상황에 대응하기 위해, 하나의 롤(Role)에는 하나 이상의 대체(fallback) LLM을 설정할 수 있습니다. 또는 동일한 LLM이라도 모델을 변경해 체이닝할 수 있어, 모델이 교체되거나 정상적으로 응답하지 못하는 경우에도 안정적으로 서비스를 이어갈 수 있도록 설계되어 있습니다.
최적의 답을 찾기 위한 파라미터
LLM 서비스를 API로 활용할 때는 구체적인 모델 선택뿐만 아니라, temperature, top_p 등 다양한 파라미터를 함께 설정해야 합니다. 한 번에 원하는 최적의 답변을 얻기는 어렵기 때문에, 여러 번에 걸쳐 이러한 파라미터 값을 조정하며 최적의 조합을 찾아야 합니다. 이 과정이 번거롭거나 비효율적이라면, 결국 답변 품질을 적당한 수준에서 타협하게 되기 쉽습니다.
따라서 권한이 있는 사용자는 이러한 파라미터들을 손쉽게 변경할 수 있어야 하며, 사용성 측면에서 편리함이 반드시 보장되어야 합니다. 또한, 사용 중인 모델이 실험적이거나 프리뷰 단계인 경우에는 예고 없이 서비스에서 제외될 수 있으므로, 애플리케이션을 재배포하지 않고도 빠르게 모델이나 파라미터를 변경할 수 있는 유연성 역시 중요합니다.
LLM 모니터링을 위한 로깅
LLM 애플리케이션을 사용할 때는 반드시 로깅해야 하는 핵심 항목들이 있습니다.
- 클라이언트 식별 정보
- LLM 요청 정보(모델, 파라미터 등)
- LLM 응답 정보(답변, 지연 시간 등)
- 토큰 사용량
매트릭스 AI는 이러한 정보를 모두 ElasticSearch에 기록하여 체계적으로 관리하고 있습니다. 이를 통해 누가, 언제, 어떤 목적으로 LLM을 사용했는지뿐만 아니라, 사용량과 예상 API 요금까지 예측할 수 있습니다. 또한, 답변의 품질을 지속적으로 모니터링하며, 적절한 파라미터 조정을 위한 근거 데이터로 활용할 수도 있습니다.
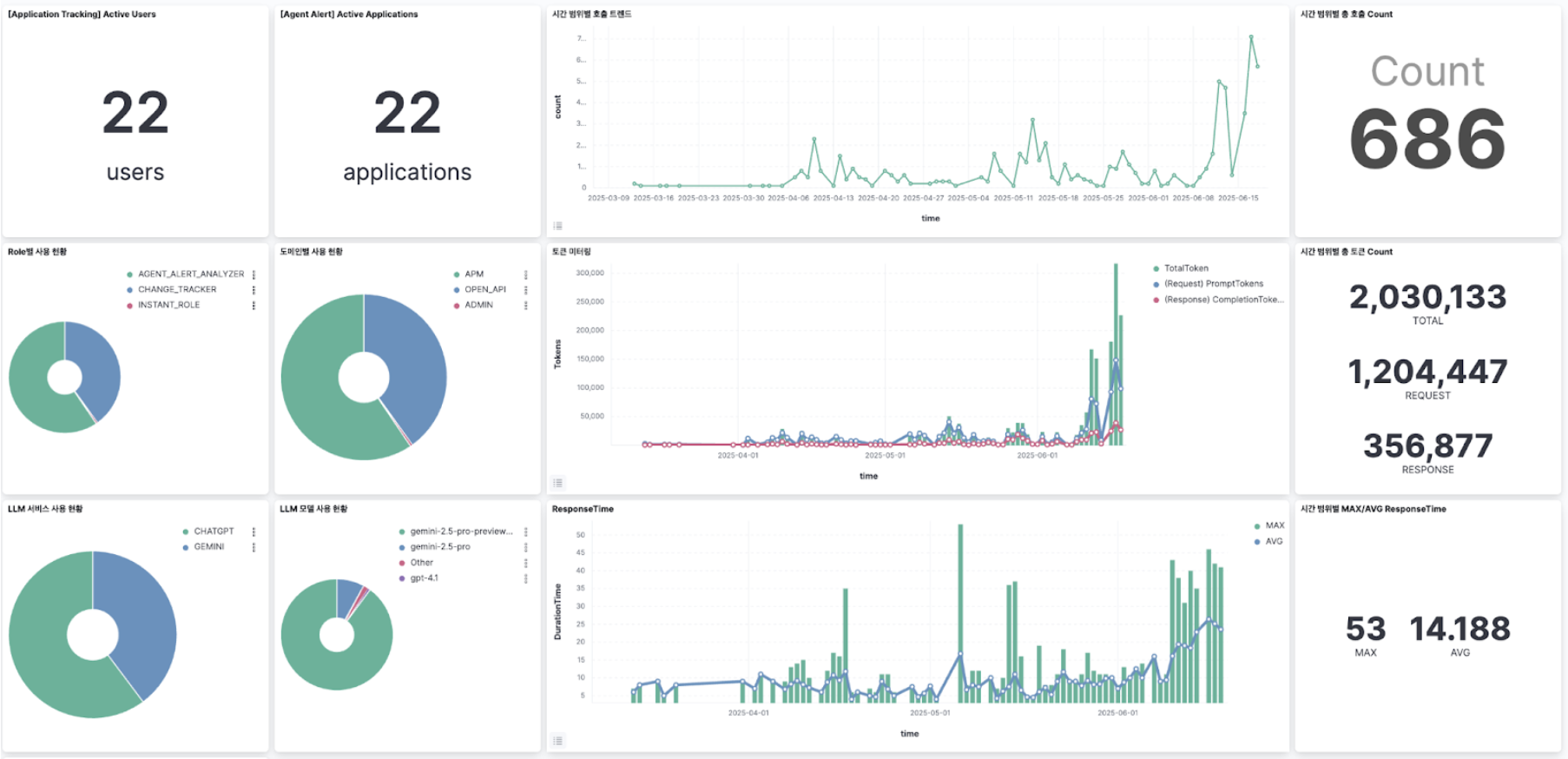
매트릭스 AI 사용 사례
매트릭스의 데이터와 AI를 결합하여 이미 구현되었거나, 앞으로 구현이 계획된 대표적인 사례들은 다음과 같습니다.
- 인시던트 AI 리포트
- 체인지 트래킹(Change Tracking)
- AI 온콜(On-call)
- 코드 튜닝 에이전트(Code-tuning Agent)
지능형 문제 진단 및 리포팅: 인시던트 AI 리포트
인시던트(Incident) 알람은 모니터링 시스템에서 가장 핵심적인 기능 중 하나입니다. 문제가 발생했을 때, 이를 담당자에게 다양한 채널(카카오톡, 이메일, 슬랙 등)을 통해 즉각적으로 알리는 역할을 합니다.
이는 모니터링 운영 사이클 중 ‘감지’ 단계에 해당합니다. 이후에는 곧바로 ‘원인 분석’ 단계로 넘어가는데, 인시던트 AI 리포트는 이 원인 분석에 소요되는 시간을 최소화하기 위해 기획되었습니다.
인시던트 AI 리포트는 단순히 사용자가 설정한 임계값을 초과했다는 사실만 알리는 데 그치지 않고, 알람을 발생시킨 구체적인 원인을 함께 제공합니다. 나아가, 다음 단계인 ‘조치’에 필요한 실질적인 힌트까지 제시함으로써 신속하고 효과적인 대응이 가능하도록 지원합니다.
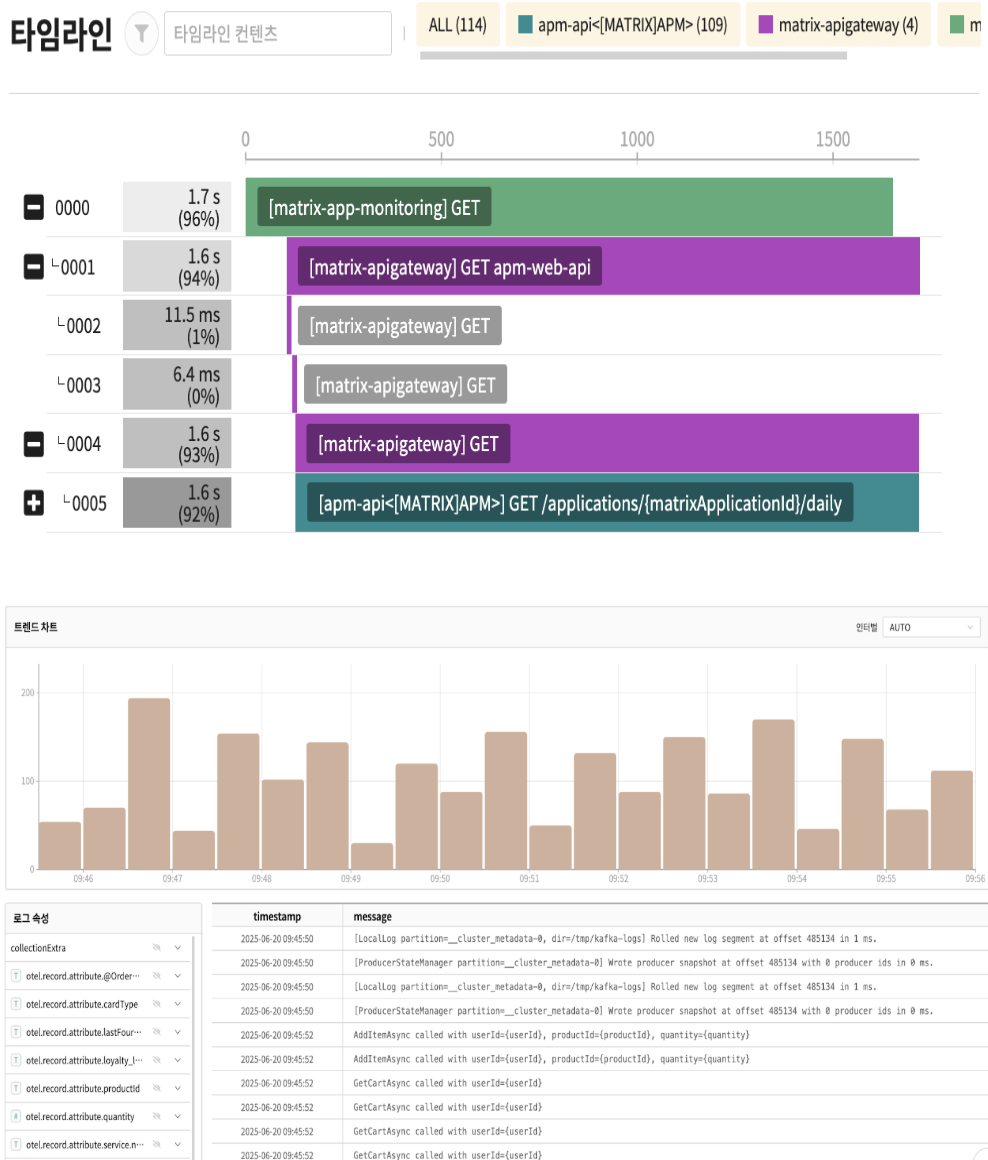
이러한 기능을 구현하기 위해 에이전트 알람 분석가(Agent Alert Analyzer)라는 롤이 도입되었습니다.
[기존 인시던트 알람]
[MATRIX-APM]
Phase: PRODUCTION
TEST-API(TEST-PROJECT)
Rule Name: SlowSQL 알람
[SQL Response time >= 8000 ms] occurred 1 times.
[2025-06-17 14:03 ~ 2025-06-17 14:13]
[prod-test-api-pod-6945c568-2ghw8: 1 times]
[인시던트 AI 리포트]
[요약]
이번 알람은 MATRIX-APM에서 발생하였으며, Java 백엔드의 특정 SQL 쿼리가 8000ms 이상의 응답시간을 기록하였습니다. 전체 요청 응답시간은 11354ms로, 대부분의 시간이 SQL 실행에 소요된 것으로 나타납니다.
[트랜잭션]
- URL: /v1/api/test<GET>
- 인스턴스: prod-test-api-pod-6945c568-2ghw8
- 총 응답시간: 11354ms, SQL 실행시간: 11327ms
[프로파일 분석]
1. 인덱스 11의 SQL 쿼리 (SELECT COUNT(1) ... WITH step1 AS ...)에서 8003ms가 소요되어, 전체 응답시간에 심각한 영향을 주고 있습니다.
2. 해당 쿼리는 'test.selectTotalHistory'라는 이름으로, test_tb1, test_tb2, test_tb3, test_tb4 등 여러 테이블에 대한 SELECT 및 JOIN 연산을 포함하고 있습니다.
3. 다른 SQL 쿼리들도 실행되나, 주요 성능 저하는 위의 복잡한 SQL 쿼리로 인한 것으로 보입니다.
[조치 방안]
1. 해당 SQL 쿼리의 실행 계획(EXPLAIN PLAN)을 확인하여 인덱스 사용 및 JOIN 순서를 최적화합니다. (예: test_tb1, test_tb2, test_tb3 등 테이블의 SELECT 연산 및 JOIN 조건 점검)
2. CTE와 서브쿼리 구조를 재검토하여 불필요한 데이터 조회를 줄이는 방안을 모색합니다.
3. DB 리소스 모니터링과 함께 필요시 캐싱 전략이나 쿼리 리팩토링을 검토해 주세요.
인시던트 AI 리포트는 매트릭스 APM에서 수집되는 트랜잭션 프로파일링 정보를 매트릭스 AI가 활용할 수 있기 때문에 구현이 가능합니다. 이러한 데이터를 바탕으로, 아래와 같은 다양한 인시던트 상황이 AI 리포트를 통해 분석되고 있습니다.
- 느린 SQL
- 데이터베이스 커넥션 타임 지연
- 네트워크 지연
- 특정 예외 발생
- 지나치게 많은 SQL 수행 혹은 호출(Fetch) 건수
리포트 포맷과 시스템 메시지
위의 샘플 메시지에서 볼 수 있듯이, AI 리포트는 일정한 포맷을 따릅니다. [요약], [트랜잭션], [프로파일 분석], [조치 방안]으로 구성된 이 포맷은 수많은 테스트와 실제 운영 환경에서도 한 번도 깨진 적이 없습니다. 이 구조는 시스템 메시지에 비교적 간단하게 정의할 수 있으며, LLM이 이를 그대로 따라 메시지를 생성하도록 설계되어 있습니다.
아래는 이 롤에서 사용한 시스템 메시지의 예시입니다.
You are an expert Site Reliability Engineer (SRE) responsible for handling incident analysis for Java-based backend systems.
You have received an alert notification from MATRIX-APM. Attached is a transaction profiling log related to this incident. Based on this profiling data, perform the following tasks:
## Context
- The transaction profiling includes execution times, call stack information, SQL queries, and any external API calls.
- Performance degradation might be caused by slow SQL queries or high latency in external API calls.
## Task
Analyze the profiling data and generate a detailed report in Korean using the format described below.
## Conditions
- If there is no serious performance degradation, you may state that the system is operating normally.
- If SQL performance is an issue, include the table name and the type of CRUD operation involved (SELECT, INSERT, UPDATE, DELETE).
- If external API latency is the issue, include the API address causing the delay.
## Output Format
Respond in polite and formal Korean using the following structure:
[요약]
[트랜잭션]
- (관련 트랜잭션 ID, 응답 시간, 호출 수 등)
- ...
- ...
[프로파일 분석]
1. ...
2. ...
3. ...
[조치 방안]
1. ...
2. ...
3. ...
## Constraints
- The sections "프로파일 분석" and "조치 방안" should contain no more than 3 bullet points each.
- Focus your analysis based on the severity and probable root cause found in the profile.
민감 데이터 처리
외부 LLM API를 활용할 때는 보안 측면에서 각별한 주의가 필요합니다. 분석 대상이 되는 SQL 쿼리, HTTP URL, JDBC URL 등은 직접적으로 개인 정보를 포함하지 않더라도, 사내 시스템의 구조나 운영 환경에 대한 중요한 힌트가 될 수 있습니다. 이러한 정보들이 외부로 노출되는 것에 대해 여러 차례 재검토 의견이 제기되었습니다.
이 문제를 해결하기 위해, 매트릭스 AI에서는 민감한 데이터를 무작위 토큰 값으로 치환하는 방식을 도입했습니다.
예를 들어, jdbc:mysql://real-database-url.com:3306/real_db와 같은 실제 데이터베이스 접속 정보는 외부 LLM에 전달되기 전에 jdbc:mysql://xcu2t3cc3xz:3306/c4ysd와 같이 임의의 토큰으로 변환됩니다. 그리고 LLM이 응답을 반환하면, 해당 토큰 값을 다시 원래의 민감 데이터로 역매핑하여 사용자에게 전달합니다.
체인지 트래킹: 배포와 운영의 지능적 연결고리
“아무것도 건드리지 않으면, 아무 일도 발생하지 않는다”는 말이 있습니다. 실제로 많은 장애가 새로운 배포 이후에 발생하는 경우가 많습니다.
그렇다고 해서 배포를 멈추고 현상 유지에만 머무를 수는 없습니다. 어제와 오늘이 다르고, 오늘과 내일이 또 다르게 변화하는 시대에 변화를 두려워하며 정체되어 있는 것은 곧 퇴보와 다름없습니다. 시대의 변화에 발맞추어 한 걸음, 한 걸음 앞으로 나아가기 위해서는 반드시 새로운 배포와 변화가 필요합니다.
이상적으로는, 배포로 인해 장애가 발생하지 않도록 최적의 시스템과 프로세스를 갖추고 완벽하게 대비하는 것이 가장 좋습니다. 그러나 현실적으로 장애는 언제든 예기치 않게 발생할 수 있으며, 100% 예방할 수 있는 방법은 존재하지 않습니다. 그렇다면 최선의 방법은 장애를 빠르게 감지하고, 신속하게 대응하는 것이라 할 수 있습니다.
매트릭스는 이러한 이유로, 특히 배포 전후와 같이 모니터링이 가장 집중적으로 요구되는 시점에서 그 필요성이 크게 부각됩니다. 변화와 혁신을 두려워하지 않고, 장애에 효과적으로 대응함으로써 안정적인 서비스 운영을 가능하게 하는 것이 바로 매트릭스의 중요한 역할입니다.
여기서 한 걸음 더 나아가, 미리 예고된 모니터링이 중요한 시점이라면 사람의 개입 없이 AI가 대신 모니터링과 감지 역할을 수행할 수 있지 않을까 하는 아이디어에서 체인지 트래킹(Change Tracking) 기능이 개발되었습니다.
매트릭스 AI x 카카오릴리즈
카카오에는 전체의 배포를 관리하는 ‘카카오릴리즈’라는 시스템이 있습니다. 이 시스템은 모든 배포가 사전에 계획되고, 리뷰어의 승인을 받아 체계적으로 진행될 수 있도록 관리합니다.
카카오릴리즈를 통해 이루어지는 배포 과정에서 매트릭스 AI를 활용하면, 담당 시스템의 건강 상태를 사용자에게 자동으로 안내할 수 있습니다. 이를 통해 단순 반복적인 모니터링 업무에 투입되는 인력을 줄일 수 있을 뿐만 아니라, 사용자가 미처 인지하지 못하는 이상 징후까지 AI가 전문적으로 관리할 수 있습니다.

배포 시점을 기준으로, 매트릭스 AI는 아래와 같은 단계에서 자동 모니터링을 수행합니다.
- 배포 30분 전
- 배포 10분, 30분, 1시간 후
- 배포 4시간, 8시간 후
- 배포 12시간, 24시간 후
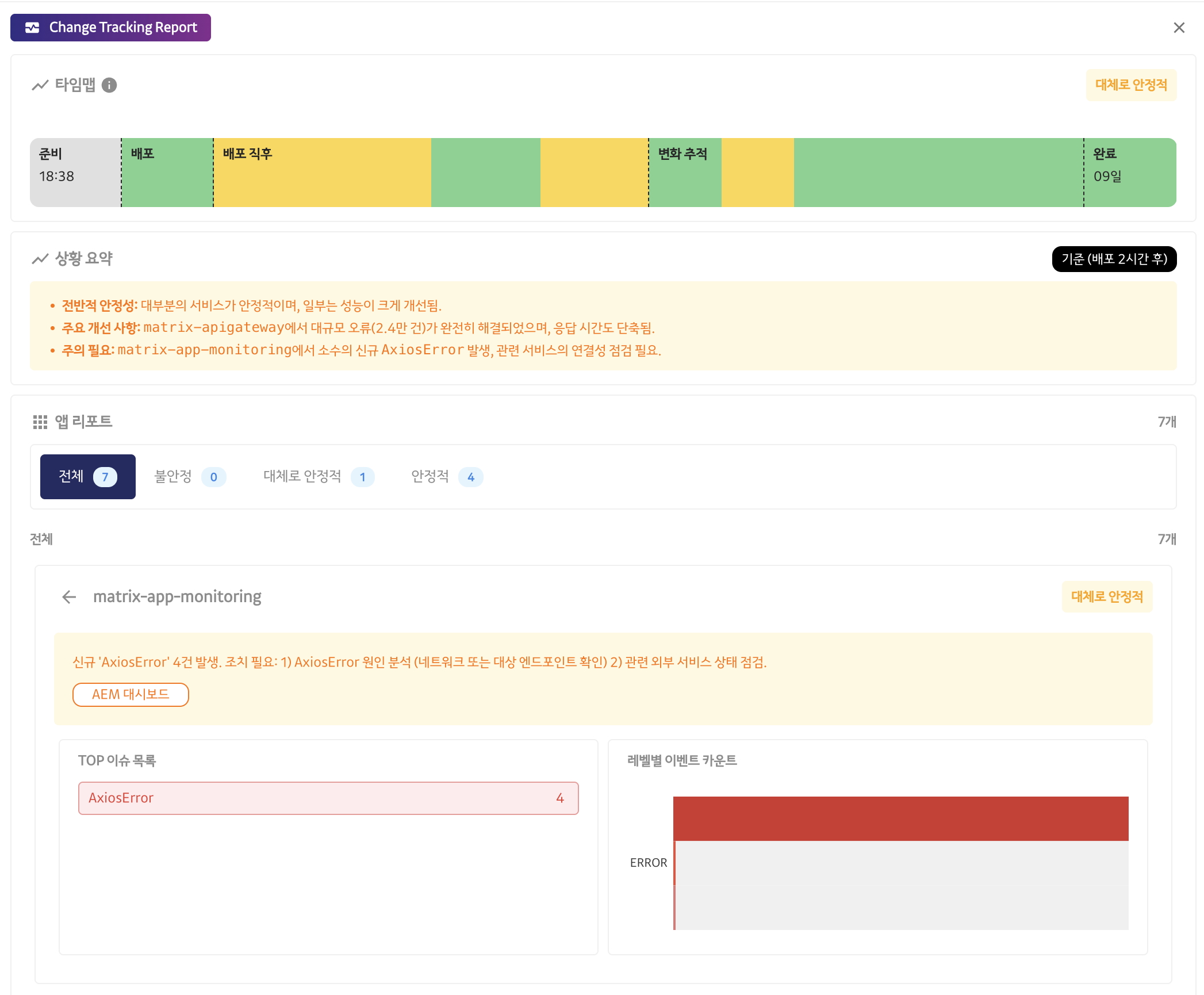
특히 배포 전에 시스템이 안정적으로 운영되고 있는지 사전 점검을 실시하여, 문제가 없는 경우에만 배포가 진행되도록 지원합니다. 또한, 배포 직후에는 모니터링 간격을 촘촘하게 유지하다가, 시간이 경과할수록 점차 모니터링 간격을 늘려가는 방식으로 효율적으로 관리합니다. 이러한 체계적인 AI 기반 모니터링은 서비스의 안정성과 운영 효율을 동시에 높여줍니다.
서비스 상태는 무엇으로 판단되는가
매트릭스에서 수집되는 데이터들을 통해 서비스 상태를 결정합니다.
- 요청 처리량과 에러 처리된 요청
- 요청 응답 시간 (p50, p90, p95)
- 에러 로그 레벨별 통계
- 중요 이슈(Top Issue)
- 인시던트 알람(Incident Alarm) 이력
시스템의 상태를 판단하는 데 사용되는 데이터들은 매트릭스의 각 라인업(OpenTelemetry, APM, LOG, Prometheus 등)에서 내부적으로 조회하여 얻을 수 있습니다. 그러나 이러한 데이터의 절대값만으로는 서비스가 실제로 안정적인지, 혹은 불안정한지를 판단하기 어렵습니다.
예를 들어, 어떤 서비스의 요청 응답 시간(p50)이 2초라고 해서 반드시 문제가 있다고 볼 수는 없습니다. 해당 서비스가 본래 2초 정도의 응답 시간을 허용하는 특성을 가질 수도 있기 때문입니다.
이러한 한계를 극복하기 위해, 체인지 트래킹 기능에서는 절대값이 아닌 상대값을 기준으로 상태를 판단합니다. 즉, 현재의 데이터와 24시간 전, 또는 일주일 전의 데이터를 비교하여 변화의 추이를 분석합니다.
만약 어제나 일주일 전에 비해 에러 발생량이 급격히 증가했거나, 응답 시간이 현저히 늘어났다면 이를 비정상적인 상태로 간주하는 방식입니다. 이처럼 상대적인 데이터 비교를 통해, 서비스의 평소 패턴에서 벗어난 이상 징후를 보다 정밀하게 감지할 수 있습니다.
구조화된 응답 포맷
사용자에게 응답을 전달하기 전에 LLM의 응답을 추가로 가공해야 하는 경우가 많습니다. 체인지 트래킹에서도 마찬가지로, LLM이 문제가 되는 메트릭을 지정해주면, 매트릭스 AI가 해당 메트릭에 대한 추가적인 조회 결과를 덧붙여 클라이언트에게 전달합니다.
이 과정을 통해 사용자는 단순 코멘트 뿐만 아니라 더 풍부하고 구체적인 정보를 얻을 수 있으며, 문제 상황에 대한 이해도 역시 크게 높아집니다.

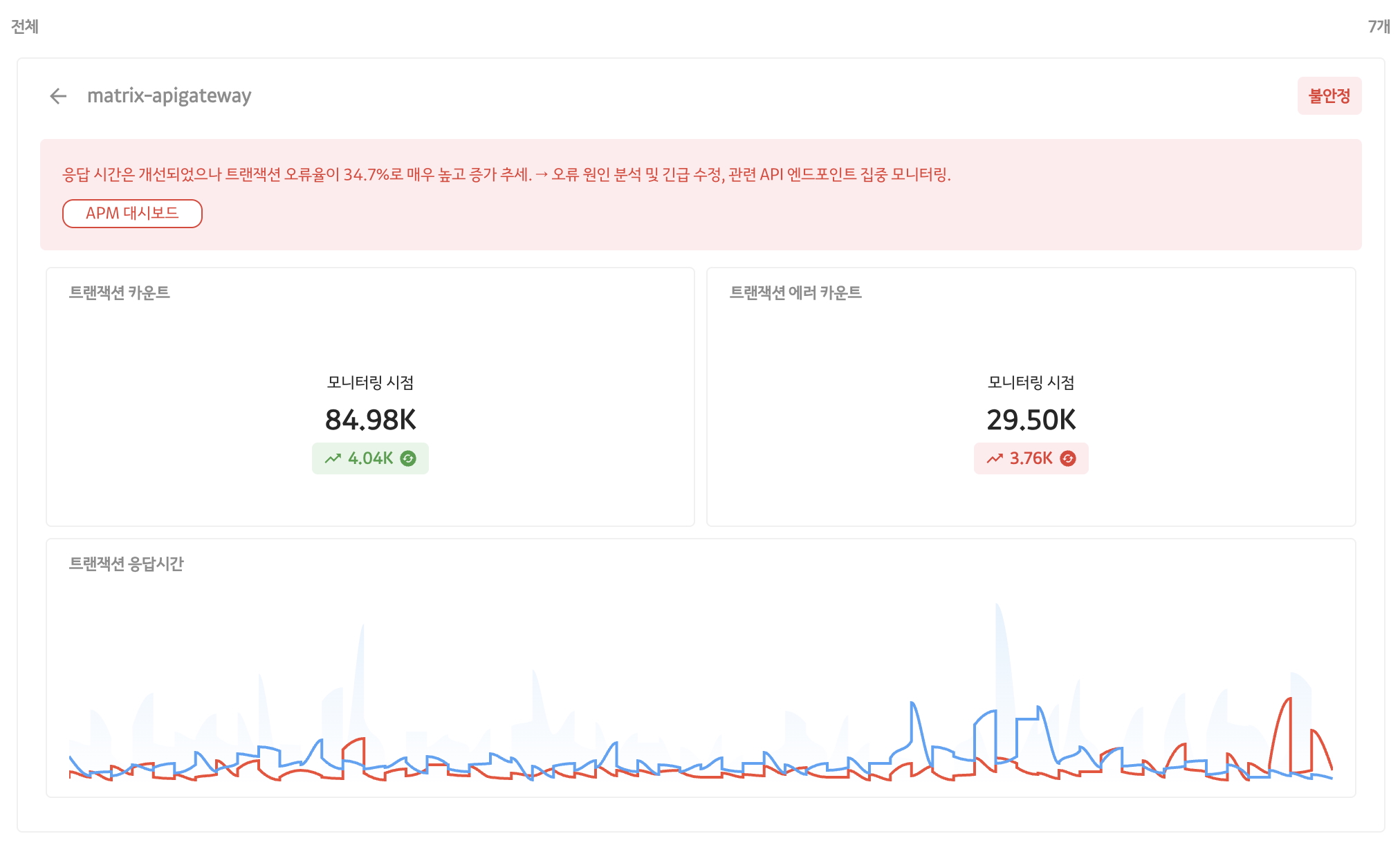
이처럼 LLM의 응답을 효과적으로 가공하려면, 단순한 텍스트가 아닌 JSON과 같이 구조화된 형태의 응답이 필요합니다.
예를 들어, 아래와 같은 응답이 온다고 가정해 보겠습니다.
{
"message": "현재 TEST 애플리케이션은 2025-06-15 12:00~13:00 사이에 에러 트랜잭션 카운트가 지난주보다 크게 증가 했습니다."
}
이와 같은 형태의 단순 텍스트 응답은, 애플리케이션이 추가적인 가공이나 분석을 수행하는 데 한계가 있습니다. 반면에 다음과 같이 구조화된 JSON 응답이 제공된다면 상황이 달라집니다.
{
"application_name": "TEST 애플리케이션",
"issue_start_time": "2025-06-15 12:00:00",
"issue_end_time": "2025-06-15 12:00:00",
"issue_metric":
[
"error_transaction"
]
}
애플리케이션은 JSON 파싱을 통해 error_transaction 메트릭에 대한 추가 조회를 자동으로 수행하고, 클라이언트에게 더 많은 정보를 제공할 수 있습니다. 이처럼 구조화된 응답은 데이터의 활용도와 자동화 수준을 크게 높여줍니다.
대표적인 LLM들은 모두 이러한 구조화된 응답을 API를 통해 효과적으로 지원하고 있습니다. 더욱 놀라운 점은, 미리 정의한 응답 포맷(response format)의 키 값을 보고 LLM이 필요한 값을 정확히 해당 위치에 맞춰 채워 넣는다는 것입니다. 이 덕분에 원하는 형태의 데이터를 안정적으로 얻을 수 있었습니다.
아래는 체인지 트래킹에서 사용하는 응답 포맷의 예시입니다. 이 포맷을 활용하면 의도한 대로 LLM이 응답을 생성하는 것이 확인되었습니다.
{
"type": "json_schema",
"name": "application_health_report_format",
"format":
{
"type": "object",
"properties":
{
"applications":
{
"type": "array",
"items":
{
"type": "object",
"properties":
{
"name":
{
"type": "string"
},
"applicationId":
{
"type": "number"
},
"state":
{
"type": "string",
"enum":
[
"STABLE",
"MOSTLY_STABLE",
"UNSTABLE"
]
},
"metric":
{
"type": "array",
"items":
{
"type": "string",
"enum":
[
"TRANSACTION",
"ALERT",
"ISSUE"
]
}
},
"comment":
{
"type": "string"
}
},
"required":
[
"name",
"applicationId",
"state",
"metric",
"comment"
],
"additionalProperties": false
}
},
"state":
{
"type": "string",
"enum":
[
"STABLE",
"MOSTLY_STABLE",
"UNSTABLE"
]
},
"comment":
{
"type": "string"
}
},
"required":
[
"applications",
"state",
"comment"
],
"additionalProperties": false
}
}
24시간 무중단 AI 기반 서비스 감시자: AI 온콜
체인지 트래킹을 위해 구축된 매트릭스의 지식 베이스 기반 서비스 건강성 AI 모니터링은 현재 AI 온콜(On-call) 기능으로 확장되고 있습니다. 지금도 많은 주요 플랫폼과 서비스에서는 온콜 담당자를 지정하여 365일 24시간, 장애 발생 시 가장 먼저 문제를 감지하고 상황을 신속하게 전파하는 역할을 맡고 있습니다.
온콜 담당자는 단순히 문제를 감지하는 데 그치지 않고, 직접 문제를 해결하거나 적합한 담당자를 찾아 신속하게 연결해주는 브릿지 역할도 수행합니다.
하지만 어느 조직이든 365일 24시간 내내 온콜 담당자를 상시로 두는 것은 현실적으로 쉽지 않습니다. 특히 연휴나 단체 워크샵 등 외부 활동이 많은 시기에는 인력 운영에 더욱 어려움이 따릅니다. 이러한 상황에서 AI 온콜은 큰 도움이 될 수 있습니다.
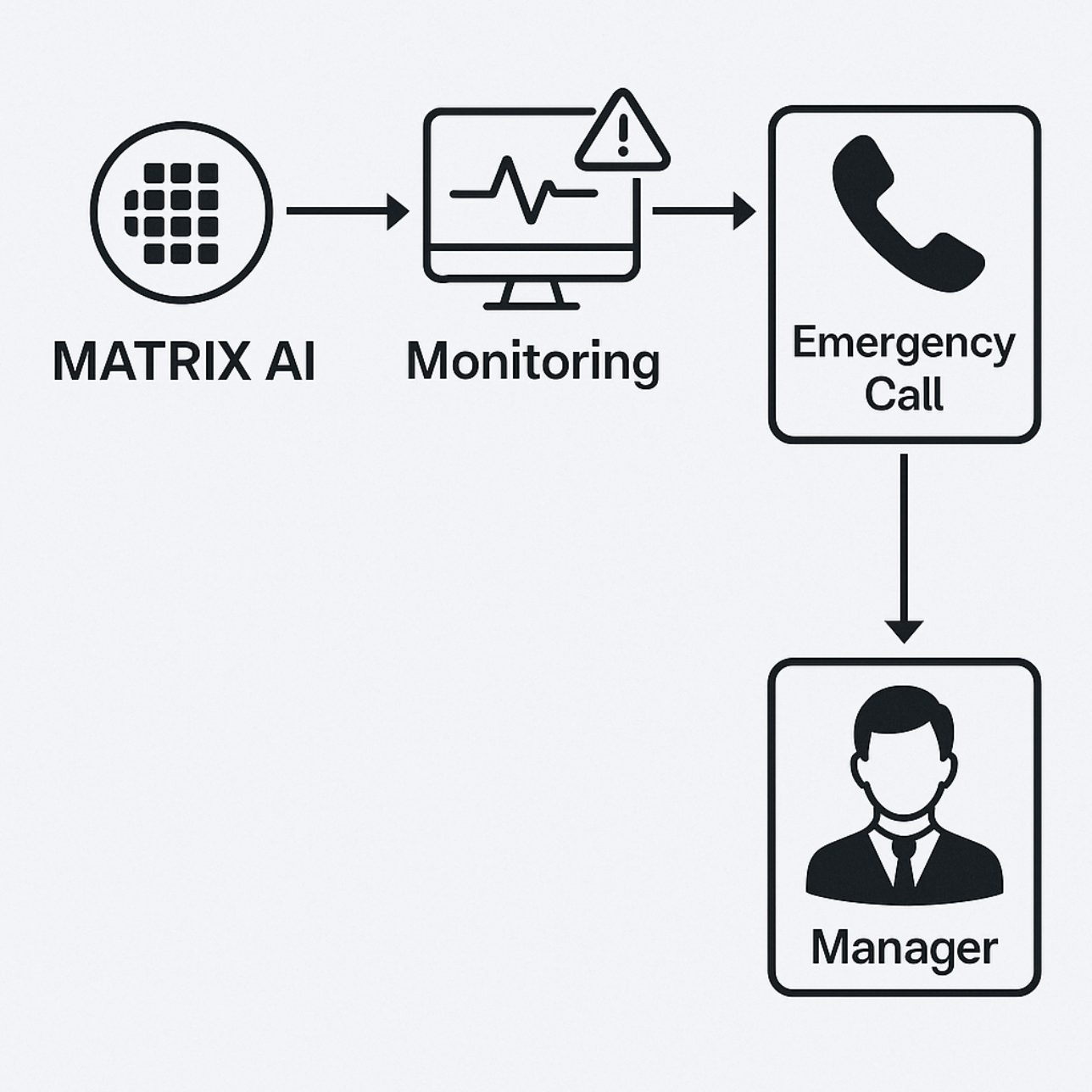
AI 온콜은 서비스 건강성 모니터링, 사용자 문의 대응, 인시던트 담당자에게 알림 전송 등의 기능을 제공해 줄 수 있습니다.
특히, 인시던트 담당자 알림의 경우 상황의 심각성에 따라 직접 전화를 걸어 알릴 수도 있습니다. 이를 위해 전화 API와 TTS(음성 합성) 기술을 활용하며, 담당자 전화번호를 자동으로 조회하여 신속하게 연락을 취할 수 있도록 설계했습니다.
자율적 코드 개선과 자동화의 시작: 코드 튜닝 에이전트
이제는 ‘코딩 에이전트 전성시대’라고 불러도 과언이 아닙니다. 최근에는 개발자가 직접 입력하는 코드보다, Cursor나 Claude Code 같은 AI가 자동으로 생성해주는 코드가 더 많아지고 있습니다. 하루가 다르게 발전하는 코딩 에이전트 AI 모델에게 코드 레벨의 에러 정보나 성능 지연 정보 등을 제공하면, AI가 이를 바탕으로 충분히 적절하게 코드를 수정할 수 있을 것이라는 기대가 커지고 있습니다.
이러한 아이디어를 바탕으로, 아래와 같은 시스템 구성도를 그릴 수 있습니다.
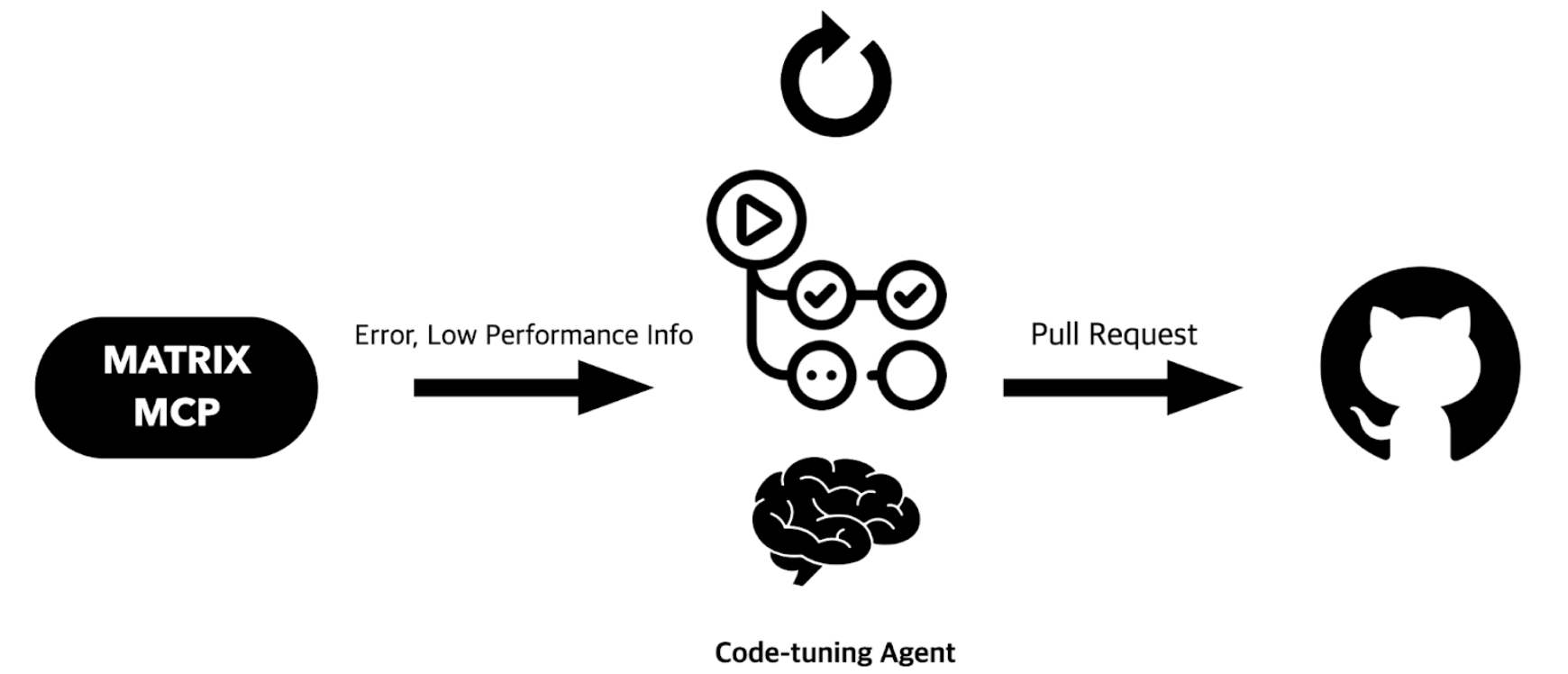
매트릭스는 AI 클라이언트에게 이러한 다양한 정보를 제공하기 위해 MCP 서버를 오픈할 계획입니다. 매트릭스 MCP 서버를 통해 에러 스택 트레이스, 에러 메시지, 에러 코드 등 코드 수준의 에러 정보는 물론, 느린 트랜잭션의 스택 트레이스 집합이나 느린(Slow) SQL 정보 등 성능 관련 데이터까지 모두 전달할 수 있습니다.
이 정보들은 미리 설정해둔 브랜치의 기준 코드와 연계되어, LLM이 코드를 자동으로 수정하고 PR(Pull Request)까지 생성하는 과정을 자동화할 수 있습니다.
예를 들어, 매일 새벽에 GitHub Actions를 통해 스케줄러가 실행되면, 코드 튜닝 에이전트(Code-tuning Agent)가 새로운 PR을 자동으로 올립니다. 담당자는 출근 후, 이 AI 에이전트가 생성한 PR을 검토하고 병합만 하면 되기 때문에, 개발 프로세스의 효율성과 생산성이 크게 향상될 수 있습니다.
AI 네이티브한 옵저버빌리티, 그 다음 단계로
서비스 모니터링은 ‘모니터링 → 감지 → 원인 분석 → 조치 → 반영’의 순환적인 사이클로 이루어집니다. 앞서 소개한 매트릭스 AI 기반 사례들을 통해, 이제 모니터링, 감지, 원인 분석, 조치 단계에 이르는 많은 작업을 AI에게 효과적으로 위임할 수 있게 되었습니다.
아직 ‘반영’ 단계까지 완전히 자동화하려면 넘어야 할 과제가 남아 있지만, 머지않아 이 부분 역시 AI가 주도적으로 담당하는 날이 올 것으로 기대됩니다.